
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


在全连接层构成的多层感知机网络中,我们要通过将图像数据展平成一维向量来送入模型,但这会忽略了每个图像的 空间结构信息 。理想的策略应该是要利用相近像素之间的相互关联性,将图像数据二维矩阵送给模型中学习.
卷积神经网络(convolutional neural network, CNN )正是一类强大的、专为处理图像数据(多维矩阵)而设计的神经网络, CNN 的设计是深度学习中的一个里程碑式的技术。在 Transformer 应用到 CV 领域之前,基于卷积神经网络架构的模型在计算机视觉领域中占主导地位,几乎所有的图像识别、目标检测、语义分割、3D目标检测、视频理解等任务都是以 CNN 方法为基础.
卷积神经网络核心网络层是卷积层,其使用了卷积(convolution)这种数学运算,卷积是一种特殊的线性运算。另外,通常来说,卷积神经网络中用到的卷积运算和其他领域(例如工程领域以及纯数学领域)中的定义并不完全一致.
在理解卷积层之前,我们首先得理解什么是卷积操作.
卷积与 傅里叶变换 有着密切的关系。例如两函数的傅里叶变换的乘积等于它们卷积后的傅里叶变换,利用此一性质,能简化傅里叶分析中的许多问题.
operation 视语境有时译作“操作”,有时译作“运算”,本文不做区分.
为了给出卷积的定义, 这里从现实世界会用到函数的例子出发.
假设我们正在用激光传感器追踪一艘宇宙飞船的位置。我们的激光传感器给出 一个单独的输出 \(x(t)\) ,表示宇宙飞船在时刻 \(t\) 的位置。 \(x\) 和 \(t\) 都是 实值 的,这意味着我们可以在任意时刻从传感器中读出飞船的位置.
现在假设我们的传感器受到一定程度的噪声干扰。为了得到飞船位置的低噪声估计,我们对得到的测量结果进行平均。显然,时间上越近的测量结果越相关,所 以我们采用一种 加权平均 的方法,对于最近的测量结果赋予更高的权重。我们可以采用一个加权函数 \(w(a)\) 来实现,其中 \(a\) 表示测量结果距当前时刻的时间间隔。如果我们对任意时刻都采用这种加权平均的操作,就得到了一个新的对于飞船位置的平滑估计函数 \(s\)
这种运算就叫做卷积( convolution )。更一般的,卷积运算的数学公式定义如下:
以上卷积计算公式可以这样理解
reverse ),相当于在数轴上把 \(g(t)\) 函数从右边褶到左边去,也就是卷积的“卷”的由来。 对卷积这个名词,可以这样理解: 所谓两个函数的卷积( \(f*g\) ),本质上就是先将一个函数翻转,然后进行滑动叠加 。在连续情况下,叠加指的是对两个函数的乘积求积分,在离散情况下就是加权求和,为简单起见就统一称为叠加.
因此,卷积运算整体来看就是这么一个过程
翻转—>滑动—>叠加—>滑动—>叠加—>滑动—>叠加..... 。
多次滑动得到的一系列叠加值,构成了卷积函数.
这里多次滑动过程对应的是 \(t\) 的变化过程.
那么, 卷积的意义是什么呢 ?可以从卷积的典型应用场景-图像处理来理解:
卷积意义的理解来自 知乎问答 ,有所删减和优化.
一维卷积的实例有 “丢骰子” 等经典实例,这里不做展开描述,本文从二维卷积用于图像处理的实例来理解.
一般,数字图像可以表示为如下所示矩阵:
本节图片摘自 知乎用户马同学的文章 .

而卷积核 \(g\) 也可以用一个矩阵来表示,如
按照卷积公式的定义,则目标图片的第 \((u, v)\) 个像素的二维卷积值为:
展开来分析二维卷积计算过程就是,首先得到原始图像矩阵中 \((u, v)\) 处的矩阵:
然后将图像处理矩阵 翻转 (两种方法,结果等效),如先沿 \(x\) 轴翻转,再沿 \(y\) 轴翻转( 相当于将矩阵 \(g\) 旋转 180 度 ):
最后,计算卷积时,就可以用 \(f\) 和 \(g′\) 的内积:
计算过程可视化如下动图所示,注意动图给出的是 \(g\) 不是 \(g'\) .

以上公式有一个特点,做乘法的两个对应变量 \(a, b\) 的下标之和都是 \((u,v)\) ,其目的是对这种加权求和进行一种约束,这也是要将矩阵 \(g\) 进行翻转的原因。上述计算比较麻烦,实际计算的时候,都是用翻转以后的矩阵,直接求 矩阵内积 就可以了.
在机器学习和图像处理领域,卷积的主要功能是 在一个图像(或某种特征) 上滑动一个卷积核(即滤波器),通过卷积操作得到一组新的特征 。一幅图像在经过卷积操作后得到结果称为特征映射( Feature Map )。如果把图像矩阵简写为 \(I\) ,把卷积核 Kernal 简写为 \(K\) ,则目标图片的第 \((i,j)\) 个像素的卷积值为:
可以看出,这和一维情况下的卷积公式 2 是一致的。因为卷积的可交换性,我们也可以把公式 3 等价地写作:
通常,下面的公式在机器学习库中实现更为简单,因为 \(m\) 和 \(n\) 的有效取值范围相对较小.
卷积运算可交换性的出现是因为我们将核相对输入进行了翻转( flip ),从 \(m\) 增 大的角度来看,输入的索引在增大,但是卷积核的索引在减小。我们将 卷积核翻转的唯一目 的是实现可交换性 。尽管可交换性在证明时很有用,但在神经网络的应用中却不是一个重要的性质。相反,许多神经网络库会实现一个 互相关函数 ( corresponding function ),它与卷积相同但没有翻转核:
互相关函数的运算,是两个序列滑动相乘,两个序列都不翻转。卷积运算也是滑动相乘,但是其中一个序列需要先翻转,再相乘.
互相关和卷积运算的关系,可以通过下述公式理解:
其中 \(\otimes\) 表示互相关运算, \(*\) 表示卷积运算, \(\text{rot180(⋅)}\) 表示旋转 180 度, \(Y\) 为输出矩阵。从上式可以看出,互相关和卷积的区别仅仅在于卷积核是否进行翻转。因此互相关也可以称为不翻转卷积. 。
离散卷积可以看作矩阵的乘法,然而,这个矩阵的一些元素被限制为必须和另外一些元素相等.
在神经网络中使用卷积是为了进行特征抽取, 卷积核是否进行翻转和其特征抽取的能力无关 (特别是当卷积核是可学习的参数时), 因此卷积和互相关在能力上是等价的 。事实上,很多深度学习工具中卷积操作其实都是互相关操作,用来 减少一些不必要的操作或开销(不反转 Kernal) .
总的来说, 。
在传统图像处理中, 线性空间滤波 的原理实质上是指指图像 \(f\) 与滤波器核 \(w\) 进行乘积之和( 卷积 )运算。核是一个矩阵,其大小定义了运算的邻域,其系数决定了该滤波器(也称模板、窗口滤波器)的性质,并通过设计不同核系数(卷积核)来实现低通滤波(平滑)和高通滤波(锐化)功能,因此我们可以认为卷积是利用某些设计好的参数组合(卷积核)去提取图像空域上相邻的信息.
在全连接前馈神经网络中,如果第 \(l\) 层有 \(M_l\) 个神经元,第 \(l-1\) 层有 \(M_{l-1}\) 个 神经元,连接边有 \(M_{l}\times M_{l-1}\) 个,也就是权重矩阵有 \(M_{l}\times M_{l-1}\) 个参数。当 \(M_l\) 和 \(M_{l-1}\) 都很大时,权重矩阵的参数就会非常多,训练的效率也会非常低.
如果采用卷积来代替全连接,第 \(l\) 层的净输入 \(z^{(l)}\) 为第 \(l-1\) 层激活值 \(a^{(l−1)}\) 和卷积核 \(w^{(l)}\in \mathbb{R}^K\) 的卷积,即 。
其中 \(b^{(l)}\in \mathbb{R}\) 为可学习的偏置.
上述卷积层公式也可以写成这样的形式: \(Z = W*A+b\) 。
根据卷积层的定义,卷积层有两个很重要的性质
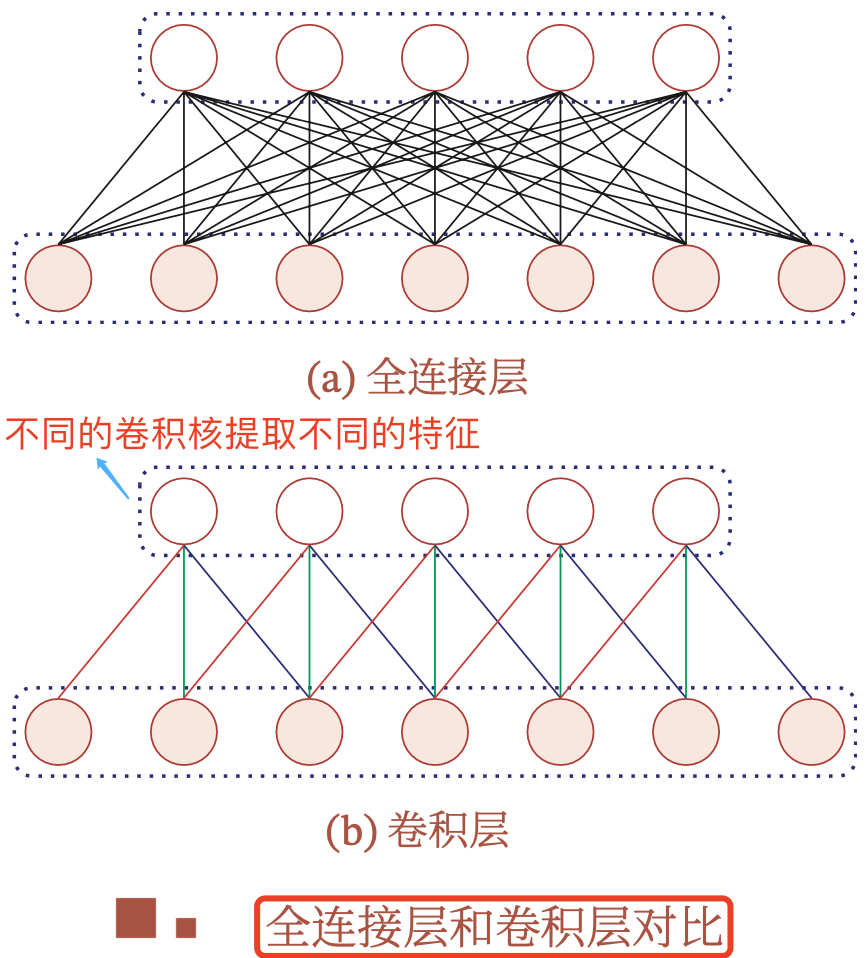
总而言之,卷积层的作用是提取一个局部区域的特征,不同的卷积核(滤波器)相当于不同的特征提取器。为了提高卷积网络的表示能力,可以在每一层使用多个不同的特征映射,即增加卷积核(滤波器)的数量,以更好地提取图像的特征.
前面章节内容中,卷积的输出形状只取决于输入形状和卷积核的形状。而神经网络中的卷积层,在卷积的标准定义基础上,还引入了卷积核的滑动步长和零填充来增加卷积的多样性,从而可以更灵活地进行特征抽取.
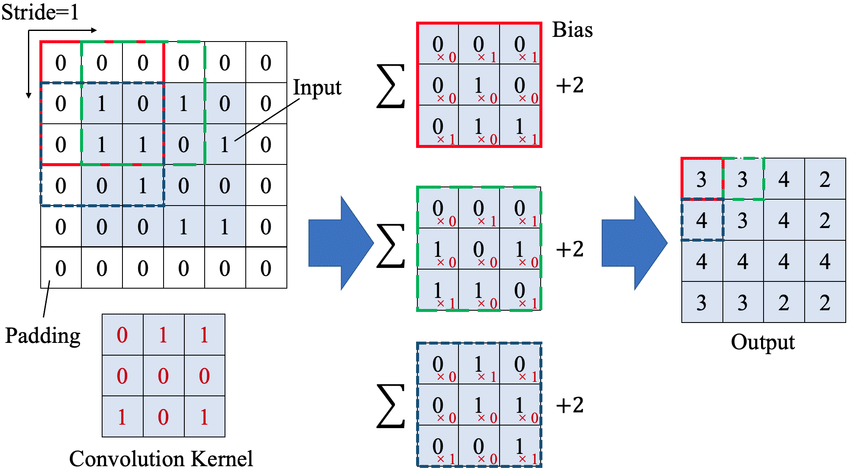
卷积层定义:每个卷积核( Kernel )在输入矩阵上滑动,并通过下述过程实现卷积计算
卷积层数值计算过程可视化如下图 1 所示:
来源论文 Improvement of Damage Segmentation Based on Pixel-Level Data Balance Using VGG-Unet .
注意,卷积层的输出 Feature map 的大小取决于输入的大小、Pad 数、卷积核大小和步长。在 Pytorch 框架中,图片( feature map )经卷积 Conv2D 后 输出大小计算公式 如下: \(\left \lfloor N = \frac{W-F+2P}{S}+1 \right \rfloor\) .
其中 \(\lfloor \rfloor\) 是向下取整符号,用于结果不是整数时进行向下取整( Pytorch 的 Conv2d 卷积函数的默认参数 ceil_mode = False ,即默认向下取整, dilation = 1 ),其他符号解释如下:
W×W (默认输入尺寸为正方形) Filter 大小 F×F S P N×N 上图1侧重于解释数值计算过程,而下图2则侧重于解释卷积层的五个核心概念的关系:
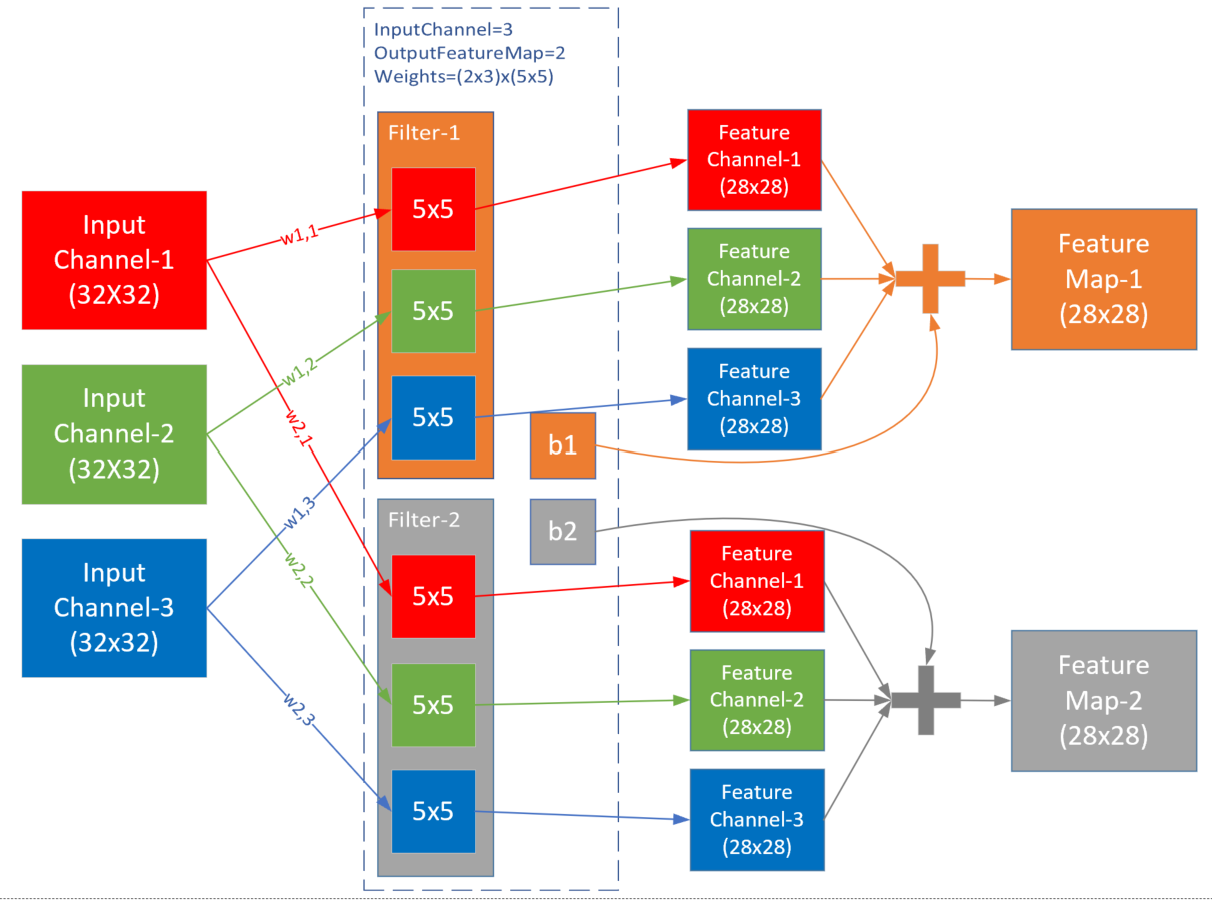
上图是三通道经过两组过滤器的卷积过程,在这个例子中,输入是三维数据 \(3\times 32 \times32\) ,经过权重参数尺寸为 \(2\times 3\times 5\times 5\) 的卷积层后,输出为三维 \(2\times 28\times 28\) ,维数并没有变化,只是每一维内部的尺寸有了变化,一般都是要向更小的尺寸变化,以便于简化计算.
假设三维卷积(也叫滤波器)尺寸为 \((c_{in}, k, k)\) ,一共有 \(c_{out}\) 个滤波器,即卷积层参数尺寸为 \((c_{out}, c_{in}, k, k)\) ,则标准卷积层有以下特点:
feature map 的数量等于滤波器数量 \(c_{out}\) ,即卷积层参数值确定后,feature map 的数量也确定,而不是根据前向计算自动计算出来; 注意 ,以上内容都描述的是 标准卷积 ,随着技术的发展,后续陆续提出了分组卷积、深度可分离卷积、空洞卷积等。详情可参考我之前的文章- MobileNetv1论文详解 .
Pytorch 框架中对应的卷积层 api 如下:
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
主要参数解释:
in_channels ( int ) – 输入信号的通道。 out_channels ( int ) – 卷积产生的通道。 kerner_size ( int or tuple ) - 卷积核的尺寸。 stride ( int or tuple , optional ) - 卷积步长,默认值为 1 。 padding ( int or tuple , optional ) - 输入的每一条边补充 0 的层数,默认不填充。 dilation ( int or tuple , optional ) – 卷积核元素之间的间距,默认取值 1 。 groups ( int , optional ) – 从输入通道到输出通道的阻塞连接数。 bias ( bool , optional ) - 如果 bias=True ,添加偏置。 示例代码:
###### Pytorch卷积层输出大小验证
import torch
import torch.nn as nn
import torch.autograd as autograd
# With square kernels and equal stride
# output_shape: height = (50-3)/2+1 = 24.5,卷积向下取整,所以 height=24.
m = nn.Conv2d(16, 33, 3, stride=2)
# # non-square kernels and unequal stride and with padding
# m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2)) # 输出shape: torch.Size([20, 33, 28, 100])
# # non-square kernels and unequal stride and with padding and dilation
# m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1)) # 输出shape: torch.Size([20, 33, 26, 100])
input = autograd.Variable(torch.randn(20, 16, 50, 100))
output = m(input)
print(output.shape) # 输出shape: torch.Size([20, 16, 24, 49])
卷积神经网络一般由卷积层、汇聚层和全连接层构成.
通常当我们处理图像时,我们希望逐渐降低隐藏表示的空间分辨率、聚集信息,这样随着我们在神经网络中层叠的上升,每个神经元对其敏感的感受野(输入)就越大.
汇聚层(Pooling Layer)也叫子采样层(Subsampling Layer),其作用不仅是进降低卷积层对位置的敏感性,同时降低对空间降采样表示的敏感性.
与卷积层类似,汇聚层运算符由一个固定形状的窗口组成,该窗口根据其步幅大小在输入的所有区域上滑动,为固定形状窗口(有时称为汇聚窗口)遍历的每个位置计算一个输出。然而,不同于卷积层中的输入与卷积核之间的互相关计算, 汇聚层不包含参数 。相反,池运算是确定性的,我们通常计算汇聚窗口中所有元素的最大值或平均值。这些操作分别称为 最大汇聚层 (maximum pooling)和 平均汇聚层 (average pooling).
在这两种情况下,与互相关运算符一样,汇聚窗口从输入张量的左上⻆开始,从左往右、从上往下的在输入张量内滑动。在汇聚窗口到达的每个位置,它计算该窗口中输入子张量的最大值或平均值。计算最大值或平均值是取决于使用了最大汇聚层还是平均汇聚层.
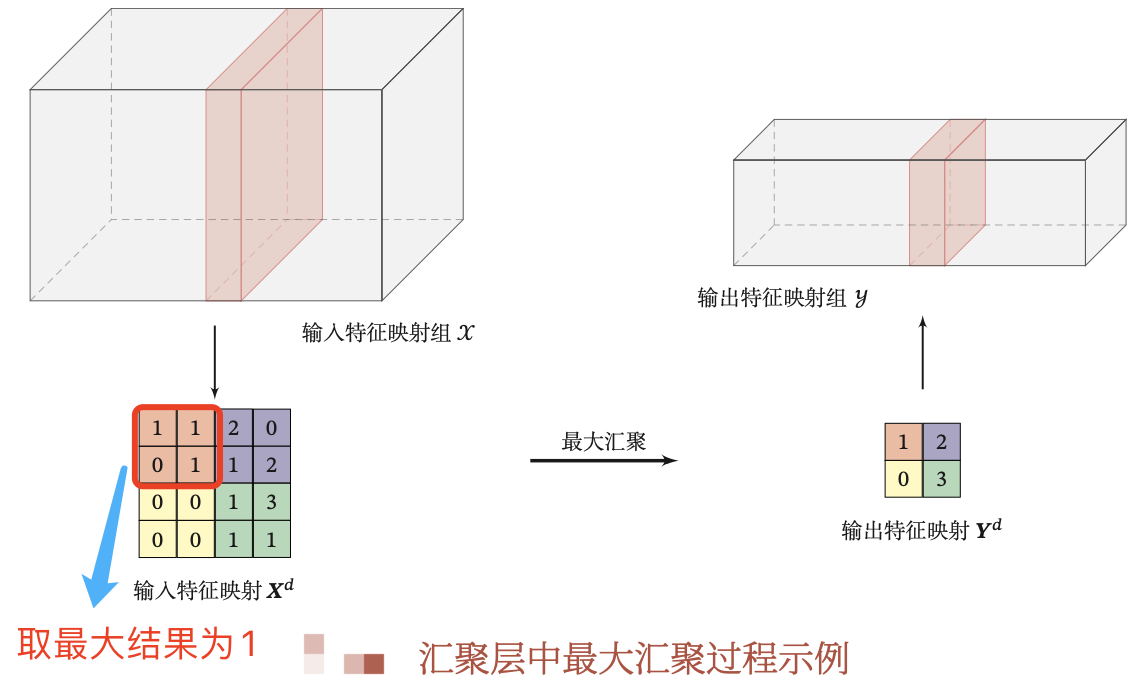
值得注意的是,与卷积层一样,汇聚层也可以通过改变填充和步幅以获得所需的输出形状.
Pytorch 框架中对应的聚合层 api 如下:
class torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
主要参数解释 :
kernel_size ( int or tuple ): max pooling 的窗口大小。 stride ( int or tuple , optional): max pooling 的窗口移动的步长。默认值是 kernel_size`。 padding ( int or tuple , optional ): 默认值为 0 ,即不填充像素 。输入的每一条边补充 0 的层数。 dilation :滑动窗中各元素之间的距离。 ceil_mode :默认值为 False ,即上述公式默认向下取整,如果设为 True ,计算输出信号大小的时候,公式会使用向上取整。 Pytorch 中池化层默认 ceil mode = false ,而 Caffe 只实现了 ceil mode= true 的计算方式.
示例代码:
import torch
import torch.nn as nn
import torch.autograd as autograd
# 大小为3,步幅为2的正方形窗口池
m = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# pool of non-square window
input = autograd.Variable(torch.randn(20, 16, 50, 32))
output = m(input)
print(output.shape) # torch.Size([20, 16, 25, 16])
一个典型的卷积网络结构是由卷积层、汇聚层、全连接层交叉堆叠而成。如下图所示:
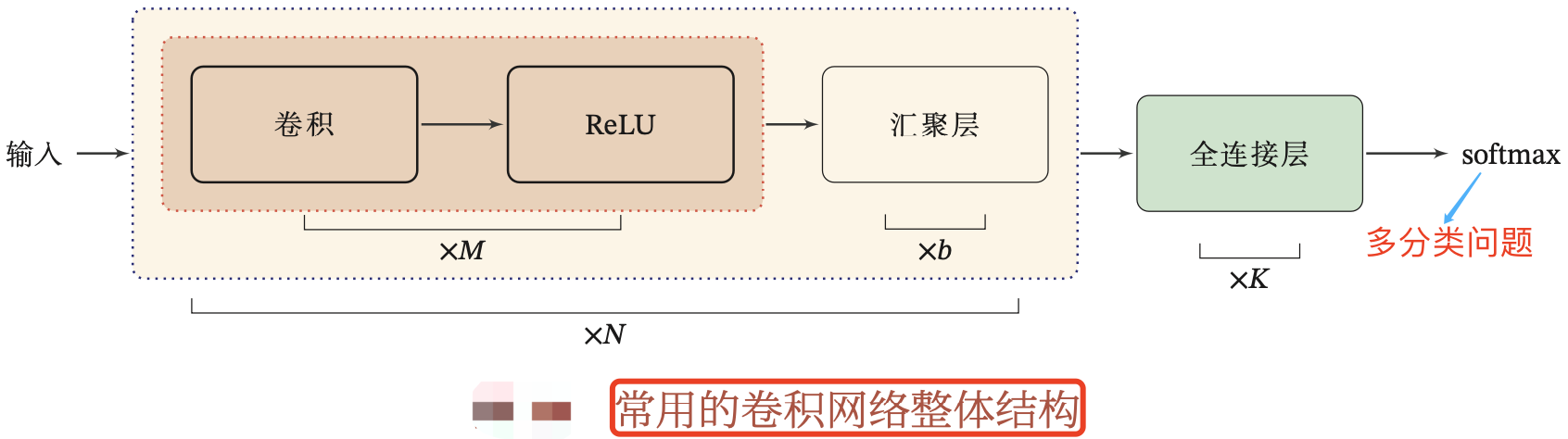
一个简单的 CNN 网络连接图如下所示.
经典 CNN 网络的总结,可参考我之前写的文章- 经典 backbone 网络总结 .
目前,卷积网络的整体结构趋向于使用更小的卷积核(比如 \(1 \times 1\) 和 \(3 \times 3\) ) 以及更深的结构(比如层数大于 50)。另外,由于卷积层的操作性越来越灵活(同样可完成减少特征图分辨率),汇聚层的作用越来越小,因此目前的卷积神经网络逐渐趋向于全卷积网络.
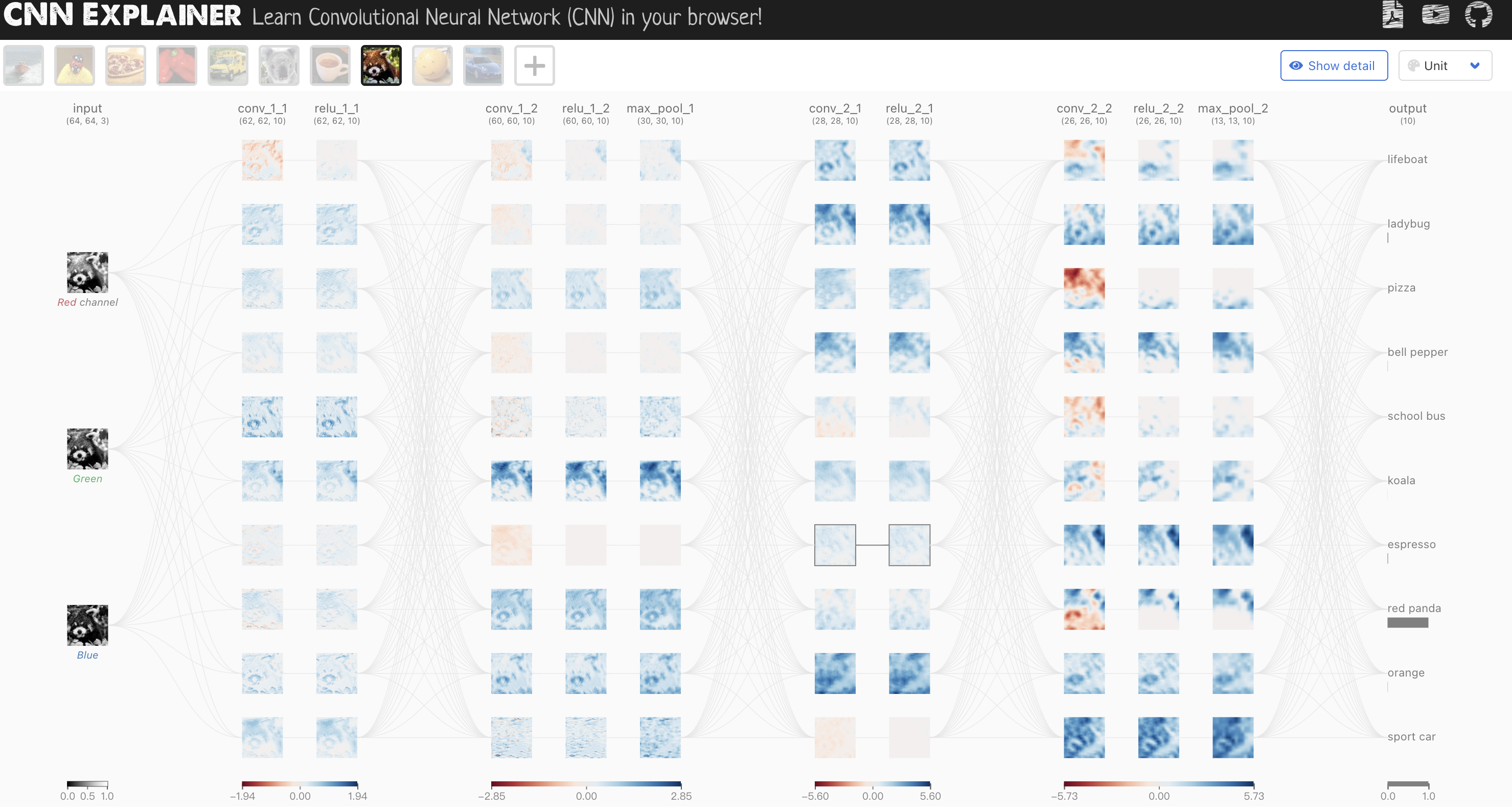
另外,可通过这个 网站 可视化 cnn 的全部过程.
最后此篇关于神经网络基础部件-卷积层详解的文章就讲到这里了,如果你想了解更多关于神经网络基础部件-卷积层详解的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
我想向一些用户公开一个 Web 部件,但不是所有用户。如何在“添加 Web 部件”弹出窗口中显示或隐藏 Web 部件?我想通过代码来做到这一点,我希望使用 SharePoint 角色来实现这一点。 最
我无法创建两个以上的 StatusBar 部分: HWND hStatusBar = CreateWindowEx(0, STATUSCLASSNAME, "", WS_CHILD | WS_VISI
使用 SharePoint 2007,如何在编辑页面模式下允许将 CEWP 添加到“添加 Web 部件”对话框的选择菜单?目前,我只能添加公告、日历、链接、共享文档、任务,但我无法添加 CEWP。我可
哪个 Web 部件以及如何配置它以查看来自不同网站集的列表? 请注意,我不想查看页面,而是查看列表。例如,在单独的网站集下查看来自不同团队网站的公告。 预先感谢您的帮助。 最佳答案 Data Form
以下是我在 FeatureDeactivation 事件处理程序中添加的代码片段。我无法获得删除 System.Web.UI.WebControls.WebParts 类型的 webpart 的解决方
我一直在尝试跟踪来自以下方面的信息: Long URL clipped to stop breaking the page 和 http://msdn.microsoft.com/en-us/libr
我想创建一个自定义 Web 部件,它具有 1 个以上的筛选器 Web 部件,并且可以在运行时/设计时连接到报表查看器 Web 部件(集成模式)。 我为此搜索了很多,但找不到一种方法来让单个 Web 部
我正在尝试创建一个 Web 部件,使用户无需离开 AllItems.aspx 页面即可编辑项目。 Web 部件应具有与 EditForm.aspx 页面类似的功能。 我已经使用 ConnectionC
这些年发布的许多应用程序都有新的 GUI 部件。iTunes 或 Twitter.app 中垂直布局的最小、最大和关闭按钮(但最新的具有默认布局),Safari 和终端中的选项卡控件,GarageBa
在具有数据库依赖性的 WSS3 或 MOSS2007 中部署 Web 部件的最佳方法是什么? .wsp 是否应该包含创建数据库的代码,我应该将 .wsp 封装在另一个处理数据库创建的安装程序中,还是应
我在我们位于 http://sharepoint:12345 的 moss 服务器上创建了一个新的共享点站点并毫无问题地向其添加了 CQWP。 我有一个指向同一台服务器的域名。所以我指向了http:/
在官方 Office 2007 站点中有许多对筛选器 Web 部件的引用。当我尝试添加其中之一时,我的 Sharepoint 中的 Web 部件列表没有显示任何筛选器 Web 部件。 如果有人遇到相同
我被要求在 Sharepoint 中创建一个 Web 部件,列出用户在网站集中访问的最后 10 个文档。 我的客户想要一种快速的方式让用户访问文档,这样他们就不必翻遍文件夹结构来查找文档,因为大多数时
我需要使用 C# 以编程方式将 SharePoint Web 部件“站点用户”添加到页面。 我知道如何添加 Web 部件,但如何从 Share Point 获取“站点用户”Web 部件?我不知道如何实
我正在使用 MEF 在我的应用程序中加载插件。一切正常,但我希望在将新部件放入我的应用程序文件夹时发现它们。这可能吗? DirectoryCatalog 有一个 Changed 事件,但我不确定它是如
我有一个 Winforms 桌面应用程序正在加载具有相同接口(interface)类型的多个 MEF 部件。 问题:当我尝试加载多个相同类型时,出现以下异常: 组成保持不变。由于以下错误,更改被拒绝:
我有一个内容查询 Web 部件,它按内容类型对网站集进行查询。我已按内容类型对其进行了分组,因此我有: -- Agenda (Content Type) ----Agenda #1 ----Agend
考虑以下 SharePoint 站点层次结构: - Site Collection - Site1 - Subsite1 - AnotherSubsite1
好吧,在我的 SharePoint (2013) 网站中,我制作了一个简单的 JavaScript Web 部件,每五分钟刷新一次页面。我去调整时间,在刷新前输入等待时间的地方退格,然后不假思索地退出
我不知道 Sharepoint 脚本,我的同事也不知道 JavaScript。他使用了他在 http://www.wonderlaura.com/Lists/Posts/Post.aspx?ID=22

我是一名优秀的程序员,十分优秀!