
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


。
全卷积网络(FCN)是用于图片语义分割的一种卷积神经网络(CNN),由Jonathan Long,Evan Shelhamer 和Trevor Darrell提出,由此 开启了深度学习在语义分割中的应用 。语义分割是计算机视觉领域很重要的一个分支,在自动驾驶、地面检测等方面都起到很重要作用。与简单区分前景后景的图像分割技术不同,语义分割则不仅是区分每个像素的前后景,更需要将其所属类别预测出来, 属于像素层面的分类 , 是密集的目标识别 。传统用于语义分割的CNN网络每个像素点用包围其的对象或区域类别进行标注,无论是在分割速度还是分割精度层面都很不理想。FCN参考了CNN在图像分类领域成功的经验,是一种 端到端、像素到像素 的模型 ,在多个语义分割的指标中均达到了state-of-the-art.
CNN做图像分类甚至做目标检测的效果已经被证明并广泛应用,图像语义分割本质上也可以认为是稠密的目标识别(需要预测每个像素点的类别)。 对于一般的分类CNN网络,如VGG和Resnet,都会在网络的最后加入一些全连接层,经过softmax后就可以获得类别概率信息。但是这个概率信息是1维的,即只能标识整个图片的类别,不能标识每个像素点的类别,所以这种全连接方法不适用于图像分割.
传统的基于CNN的语义分割 方法是: 将 像素周围一个小区域 (如25*25)作为CNN输入,做训练和预测。 这种方法有几个缺点:
通常的识别网络,包括LeNet,AlexNet,以及后面更加优秀的网络结构,都是 输入固定大小 的图像,得到 非空间结构的输出 。但是,这些网络的全连接层也可以看做是覆盖整个图像区域的卷积核。 因此,可以将其转化为全卷积网络,那么可以 输入任意大小 的图像, 输出分类特征图 ,保留了 空间信息 .
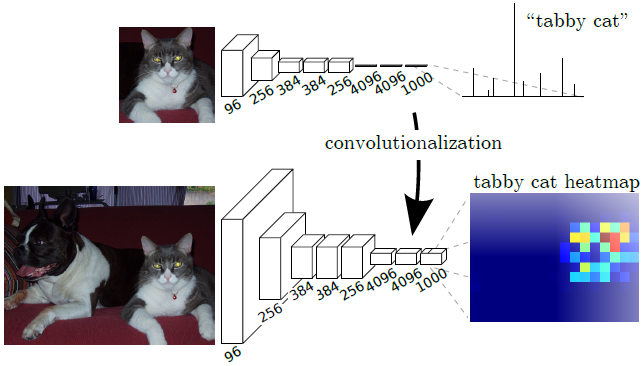
如何将全连接层转化为卷积层?
比如一个7×7×512的特征矩阵,首先将其展平(flatten)为1×1×25088的向量,再通过全连接层得到长度为4096的向量,总参数量为25088×4096=102760448。如果使用卷积(7×7,s1,4096)代替全连接层,输出也是长度为4096的向量,总参数量为7×7×512×4096=102760448。每一个卷积核有7×7×512=25088个参数,而全连接输出向量中的每一个值都是由25088个值乘上权重得来,计算过程是一样的,所以 4096个卷积核的参数可以由全连接层的4096个节点的参数 reshape 得到 .
卷积操作和池化操作会使得特征图的尺寸变小,为得到原图像大小的稠密像素预测,需要对得到的特征图进行上采样操作。可通过 双线性插值(Bilinear) 实现上采样,且双线性插值易于通过固定卷积核的 转置卷积 (transposed convolution) 实现,转置卷积即为反卷积(deconvolution)。在论文中,作者并没有固定卷积核,而是让卷积核变成可学习的参数。转置卷积操作过程如下:
示例 下面假设输入的特征图大小为2x2(假设输入输出都为单通道),通过转置卷积后得到4x4大小的特征图。这里使用的转置卷积核大小为k=3,stride=1,padding=0的情况(忽略偏执bias).

如果仅对最后一层的特征图进行上采样得到原图大小的分割,最终的分割效果往往并不理想。因为最后一层的特征图太小,这意味着过多细节的丢失。因此,通过跳级结构将 低层,精细层(fine layers) 与 高层,粗糙层(coarse layers) 结合,使得模型 兼顾局部预测以及全局结构 。下图不显示卷积层,因此VGG中只剩下5个池化层.
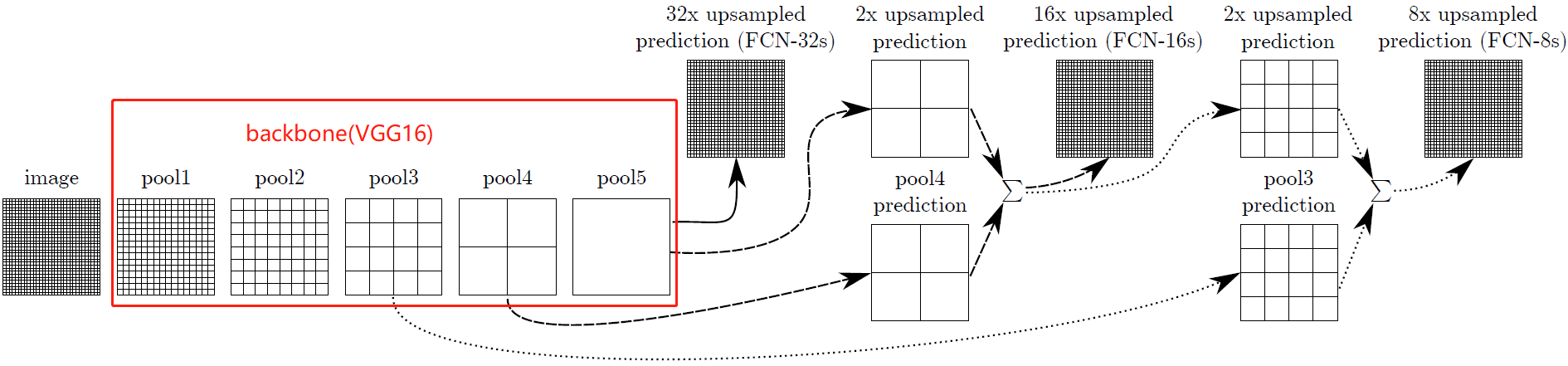
CNN的一大特点在于越深的网络感受野越大,其关于输入图片的全局信息也越多。图像语义分割要解决的两大问题是“ what ”和” where ”,即在 判断出图像中出现的物体类别 的前提下还要 定位物体的位置 ,深层次的CNN能很好解决“what”这个问题,但是由于网络层次的加深,也破坏了输入图片原始的空域信息而浅层次的CNN网络会更好的保持原始图片的空域信息,所以FCN的跳跃结构就是将CNN的浅层次网络和深层次网络结合.
FCN-32s 。

FCN-16s 。
对于FCN-16s,首先对pool5 feature进行2倍上采样获得2x upsampled feature,再把pool4 feature和2x upsampled feature逐点相加,然后对相加的feature进行16倍上采样,获得16x upsampled feature prediction.
FCN-8s 。
对于FCN-8s,首先进行pool4+2x upsampled feature逐点相加,然后又进行pool3+2x upsampled逐点相加,即进行更多次特征融合。得到平均IOU62.7,并且得到更好的细节(没有提升特别大)。随着与更低的层进行融合,但是并没有得到较大的改善,因此没有进行进一步的融合.

论文中使用21类的PASCAL VOC数据集,训练集提供原始图片和对应的ground truth,ground truth上每个像素点均有用颜色表示的标签。图片输入模型后得到原图宽高的输出,输出与ground truth计算 交叉熵损失 .
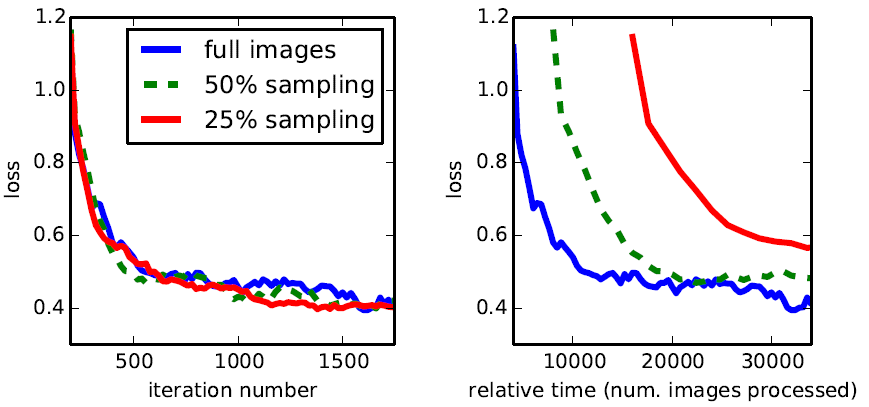
通常做语义分割的方法都是使用 Patchwise 训练,就是指将一张图片中的重要部分裁剪下来进行训练以避免整张照片直接进行训练所产生的信息冗余,这种方法有助于 快速收敛 。FCN如何模拟这样的随机选一些patchs组成minibatch的过程呢?答案是先对整个图像进行逐像素损失的计算,之后从图像上随机采一些点组成batch,而这个batch的损失就是已经计算出的这些点的损失的平均。这个过程作者称为“ loss sampling ”。因为是一次性计算出所有点的损失之后再采样,相比采样后再计算损失,loss sampling要更加高效。作者实验发现,全图训练和采样训练相比最终效果差不多,但全图训练更快收敛, 还是直接用整个图像的损失进行训练 .
当输入图像长度或宽度小于192时,下采样32倍后VGG16 backbone的输出小于7,但后面接FC6时卷积核大小为7,是没法进行卷积操作的。为了避免这个问题产生,FCN中的VGG16网络与原VGG16的一点不同是, FCN 在conv1_1层中设置了padding=100 来扩充图像 。由于(1)语义分割输入的图像一般不会太小(2)padding会导致计算量增大,后期还要 crop裁剪,所以没必要使用.
优化器 :Optimization SGD+Momentum(momentum=0.9,weight decay =5*0.0001或者2*0.0001); 。
批尺寸 :batch size=20; 。
学习率 :FCN-AlexNet,FCN-VGG16和FCN-GoogLeNet的学习率分别固定为0.001,0.0001,5*0.00001,或者为了偏移,学习率乘以2,训练过程对上述参数不是很敏感,但是对学习率很敏感。分类分数卷积层使用零初始化,随机初始化并没有改善。Dropout跟随之前的网络使用.
Metrics: 我们在语义分割和场景分割中评测了四个指标,比如像素精度,IOU。其中nij为第i类像素被预测为第j类像素的数量,ncl为总类别数量.

Fine-tuning : 我们对所有层进行微调,仅仅微调分类层,能达到前者70%的效果。从头开始训练网络是不可行的,VGG网络训练非常耗时(值得注意的是,VGG16是分阶段训练的,我们从完全的16层初始化开始的)。单GPU需要3天微调FCN-32s,在此基础上,FCN-16s和FCN-8s分别需要在增加一天.
Class Balancing :全卷积训练可以进行类平衡,比如损失添加权重或者损失采样(sampling loss)。尽管我们的数据并不是那么平衡(3/4是背景),但是我们发现类平衡不是很必要.
Shift-and-Stitch :发现上采样更有效,所以没有采用Shift-and-Stitch 。
Augmentation 数据集增强方式 :随机镜像,像素在每一个方向上随机偏移32像素,但是没有明显的提高.
More Training Data :PASCAL VOC 2011 Table1中使用,标注了1112张图片。Hariharan 收集8498张图,训练了SDS分割系统。提高了FCN-VGG16在验证集上3.4个百分点,Mean IU达到59.4. 。
。
。
。
。
。
参考:
1. 转置卷积(Transposed Convolution) 。
2. FCN网络结构详解(视频) 。
3. 深度学习论文翻译--Fully Convolutional Networks for Semantic Segmentation 。
4. 【图像分割 之 开山之作】 2015-FCN CVPR 。
5. FCN网络解析 。
6. FCN(全卷积神经网络)详解 。
7. FCN论文笔记 。
最后此篇关于【论文笔记】FCN全卷积网络的文章就讲到这里了,如果你想了解更多关于【论文笔记】FCN全卷积网络的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
我正在尝试为我的问题训练一个完全卷积的网络。我正在使用实现 https://github.com/shelhamer/fcn.berkeleyvision.org . 我有不同的图像大小。 我不确定如

我是一名优秀的程序员,十分优秀!