
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 27
27
 4
4


作者:vivo 互联网服务器团队- Wu Qinghua 。
本文从目前业界实现Jenkins的高可用的实现方案,分析各方案的优缺点,引入vivo目前使用的Jenkins高可用方案,以及目前Jenkins资源的调度方案的设计实践和目前的落地运行效果.
现在的企业很多都在用Jenkins做持续集成,各个业务端都依靠Jenkins,vivo Devops也是使用Jenkins来进行持续构建,部署Jenkins服务时如何保障服务的高可用变得尤为重要.
下面是目前Jenkins存在的 一些问题 .
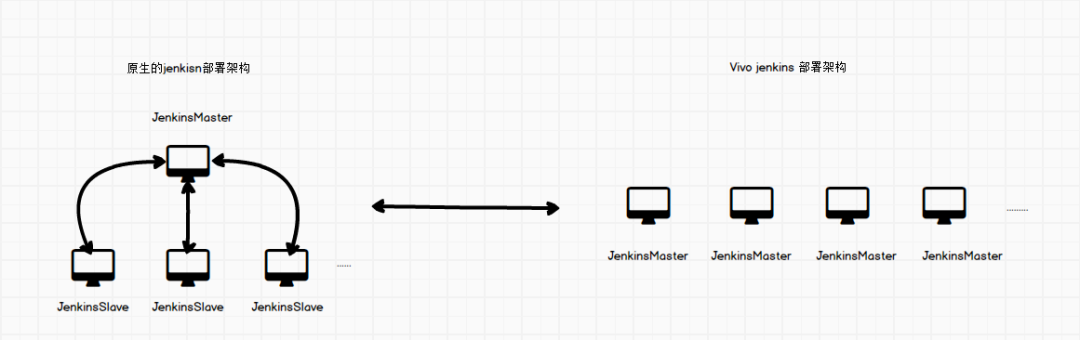
Jenkins本身是单体的,即只能有一个Jenkins Master。虽然你也可以在多台机器上部署多个Jenkins Master,但这些Master之间没有联系,都是各自把任务交给手下的slave去执行,没有任何交集。也许某个master下的slave很忙,而另一个master下的slave却很闲,资源得不到充分利用.
当其中一个slave宕机之后,该slave上的运行的job任务没有版本重新进行分配,需要用户重新执行。并且slave节点离线之后没有通知管理员.
当系统业务量比较大的时候业务请求集中在Jenkins Master上,会对Jenkins造成压力,甚至的造成Jenkins服务不可用.
当有job任务在jenkins Master上队列排队的时候,Jenkins Master宕机后,队列任务不可持久化.
Jenkins Workspace没有自动清理功能,会导致磁盘空间不足,任务执行不了的情况.
基于以上情况,vivo Devops对Jenkins的部署架构进行优化搭建,并且配套了一套Jenkins资源调度系统用于管理Jenkins资源.
目前业界也包含一些Jenkins 高可用的设计方式,但是并不能完全的满足解决上述问题,比如:
这是OpenStack团队使用的方案。这个方案使用了gearman, gearman是个任务分发框架.
需要在每个Master上安装好gearman的插件,并配置好能连接到gearman server,同时在每个Master必须建立相同的job.
之后运行任务的流程如下:
gearman worker运行在各个Jenkins Master中等待gearman server分发任务; 。
gearman client向gearman server发出运行job的请求; 。
gearman server通知各个gearman worker有任务拉,第一个闲着的worker会接受任务,如果所有的worker都忙,则放入gearman的任务队列,得worker空闲时再分配; 。
gearman worker闲下来后会从任务队列里取job来执行,执行完之后,将结果发回给gearman server,
gearman server将结果返回给 gearman client.
优点:
这样各个salver资源可以得到充分利用,某个master挂掉另外的master可以继续服务.
弊端:
每个master的slave必须配置一致,否则会造成job调度错误,同时会造成一些资源的浪费。当一个master出现问题,该master的任务不会进行自动重新分配.
目前Jenkins的配置文件都是直接在硬盘上以文件形式存储的,你在JENKINS_HOME的个文件夹下能看到各种.xml文件。有些公司在Jenkins上进行二次开发,将Jenkins的数据存储方式改为数据库存储,这样前端可以起多个Jenkins服务,后端连相同的数据库即可。数据库也有比较成熟的高可用方案.
优点: 可以达到Jenkins的高可用也就是某个master挂掉另外的master可以继续服务.
弊端: 需要对Jenkins进行二次开发,使用数据库会降低读取资源效率下降.
平时让Jenkins A机器提供服务,并使用SCM Sync configuration plugin保存数据,JenkinsA机器修改配置后触发Jenkins B更新配置,一旦Jenkins A出现问题挂掉后,切换到备机Jenkins B上.
优点: 可以达到Jenkins的高可用,当master宕机后会进行切换到备机上.
弊端: 会有一批Jenkins备机存在资源浪费,切换master时间过长,会导致有段时间Jenkins服务不可用.
由于目前业界的一些实现还不能完全的满足我们目前的需求,所以我们进行了vivo jenkins scheduler系统的设计与实现。该系统需要达到如下的目的:
提升整个构建服务可靠性时长.
保证jenkins集群的高可用,解决目前master-slave的单点问题,保证整个构建服务的可靠性时长.
降低灾难时服务恢复时长.
①提供精准流控方式,在jenkins构建出现请求量过高的时候可以进行流控和持久化操作,减少对目前系统的冲击.
②当系统压力减少后,放开流控可以快速的对堆积的请求进行分配执行.
有效分配任务至各个子节点, 保证资源的有效利用.
能保证灾难时的及时切换任务至可用节点上 ,同时能快速的通知管理员进行处理.
能进行数据的可视化分析 ,能提供一系列帮助改善开发效率的视图,比如构建时长报表、构建量报表等.
该系统我们从两大部分进行了设计,首先,我们不采用原生的Jenkins部署方案,而是采用全master的方式。第二,设计并开发了一套用于管理Jenkins集群的调度系统.
不采用目前单master的搭建方案,采用多master的搭建方案,master下不进行挂载slave机器,任务直接有master进行处理,master之间的关系、任务分配、离线、插件安装等由调度系统进行管理。这样由于vivo Jenkins Scheduler系统为高可用的,解决了目前Jenkins的单点问题.
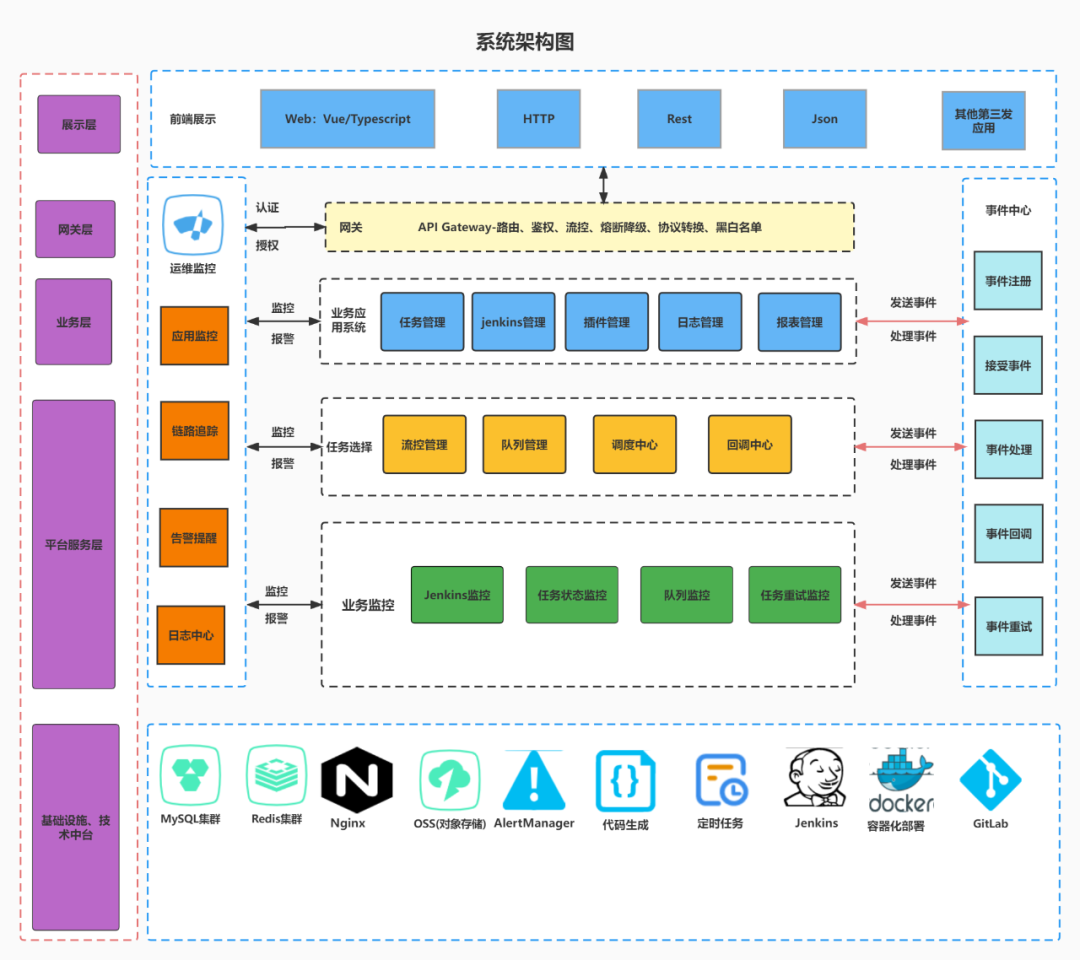
主要提供系统的外部请求,网关系统,功能包含:
权限校验: 校验用户发送集群管理系统的请求的权限.
智能路由: 接收外部一切请求,并转发到后端的外服上去.
限流: 与监控线程配合(当构建请求达到某个阈值时),进行限流操作.
API日志统一收集: 类似于一个aspect切面,记录接口的进入和出去时的相关日志.
数据处理: 对请求的参数进行数据的转换处理.
是整个系统通信调用的主要模块,采用的是Spring的Event机制实现,主要核心事件如下:
Jenkins注册事件 。
(EVENT_REGIST_JENKINS) :
Jenkins启动后,通过自定的插件会向系统发送注册请求时,系统接收到后会触发Jenkins管理模块将Jenkins的信息注册至调度系统中.
Jenkins宕机事件 。
(EVENT_DOWN_JENKINS) : 。
监控管理轮询检查Jenkins状态,当发现有Jenkins宕机的情况会触发该事件,Jenkins管理模块处理将Jenkins的信息状态设置为不可用状态,从而是任务不能分配至该台jenkins.
任务从分配事件 (EVENT_JOB_REDO) : 。
当Jenkins宕机后,如果该台jenkins上存在未执行完的任务时候,由job监控模块触发,job管理莫管处理,会对该Jenkins上未执行的job进行重新分配.
任务接受事件 (EVENT_JOB_RECIVE)
当job管理模块接受到创建请求,会触发该事件,由job管理模块放入Redis执行队列.
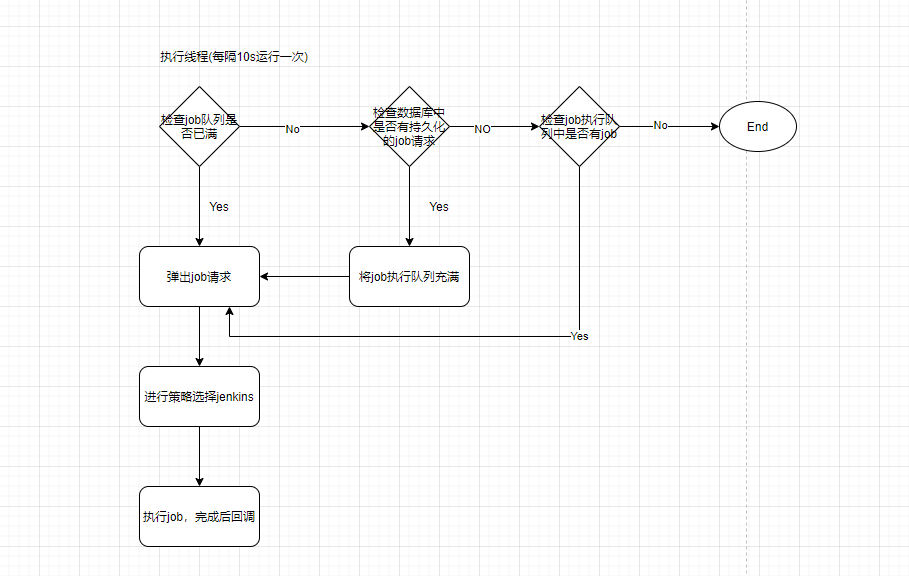
任务执行事件 (EVENT_JOB_EXECUTE) : 。
job管理模块中的执行线程(10s执行一次,会从Redis队列中弹出任务),弹出任务后触发该事件,由调度中心选取合适的jenkins进行执行.
是整个系统的核心模块,主要的功能是进行执行job时候能选取合适的jenkins进行处理任务,包含两个核心算法:
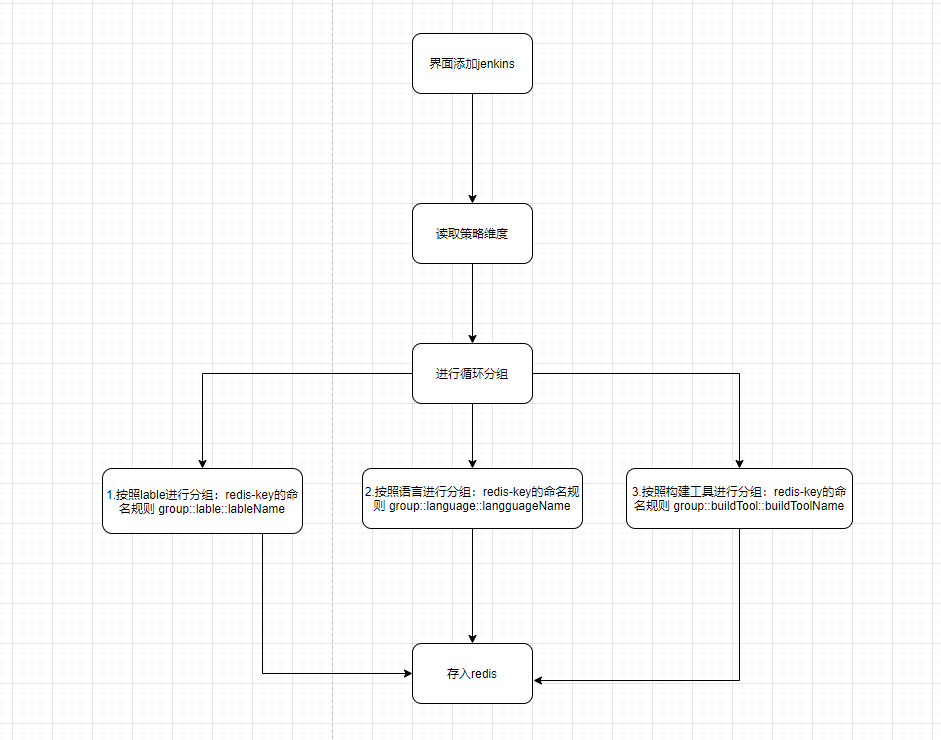
每台Jenkins都可以使用标签的方式,打上多个标签,比如Jenkins可以构建Java程序,使用的构建工具可以是maven和gradle,这个时候我们就可以给其打上Java、maven、gradle三个标签.
标签的维度主要有以下几个:
标签配置: 判断构建配置是否配置了标签,根据标签选择对应标签的Jenkins,比如配置了(docker等).
构建语言: 根据构建配置的语言,比如Java、C++、Python、Go等.
构建工具和版本: 比如Maven、gradle、Ant,Cmark、Blade等.
JDK版本: 比如JDK7、JDK8等.
Go语言版本: 比如1.15.x.、1.16.x等.
GCC版本: 如6.x、4.x等.
Python版本: 2.x、3.x等.
是否存活: 判断Jenkins是否存活,如果宕机直接过滤.
(可选策略)选择执行过该job的Jenkins,减少下载代码的过程: (第一次构建还是会比较慢,可以采用预执行的方式,在配置构建配置的时候,就预先执行一次,这样在用户执行的时候就使用该job执行过得workspace,减少代码下载的时间).
(可选策略)根据job的构建的平均构建时长 ,如果构建时长达到某个配置阈值时,优先选择构建器空闲多的Jenkins进行执行,并指出Jenkins的锁定功能。其他的job不允许分配上来.
。
如果我们给Jenkins打上标签,那么我们就可以使用标签为维度将Jenkins进行分组,并且存入至Redis中缓存,方便后续选取Jenkins用来执行任务:
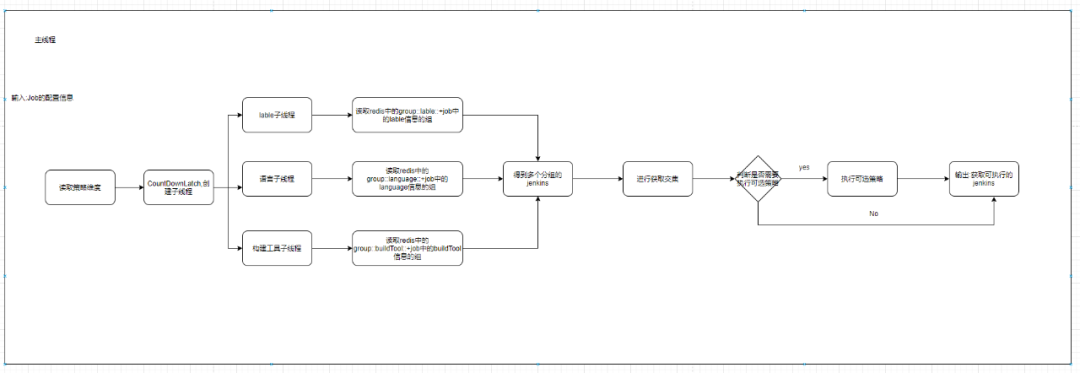
当Jenkins分组好了后,我们接受到执行的job的信息就可以使用Jenkins选取算法进行快速的选取合适的Jenkins进行处理job,如下图所示.
。
其中label子线程、语言子线程……就是我们上面的Jenkins分组的维度,有多少维度,那么这里就会有多少子线程处理.
。
构建任务进入主线程,然后主线程会按照分组维度分组操作并进行过滤,然后获取到每个分组中合适的Jenkins,再进行取交集(这个时候就获取到可以执行该构建任务的Jenkins了),在判断是否需要经过可选策略,最终得到Jenkins.
。
调度系统中的的任务接受采用的是队列的方式实现,当系统请求量达到阀后,系统将不会进入Redis队列,会将请求持久化至MySQL。后续如果有请求过来,job管理模块会检查数据库MySQL中是否有请求,如果有请求,会将请求放入Redis队列,如果没有请求就会将当前请求放入Redis队列,具体流程如下
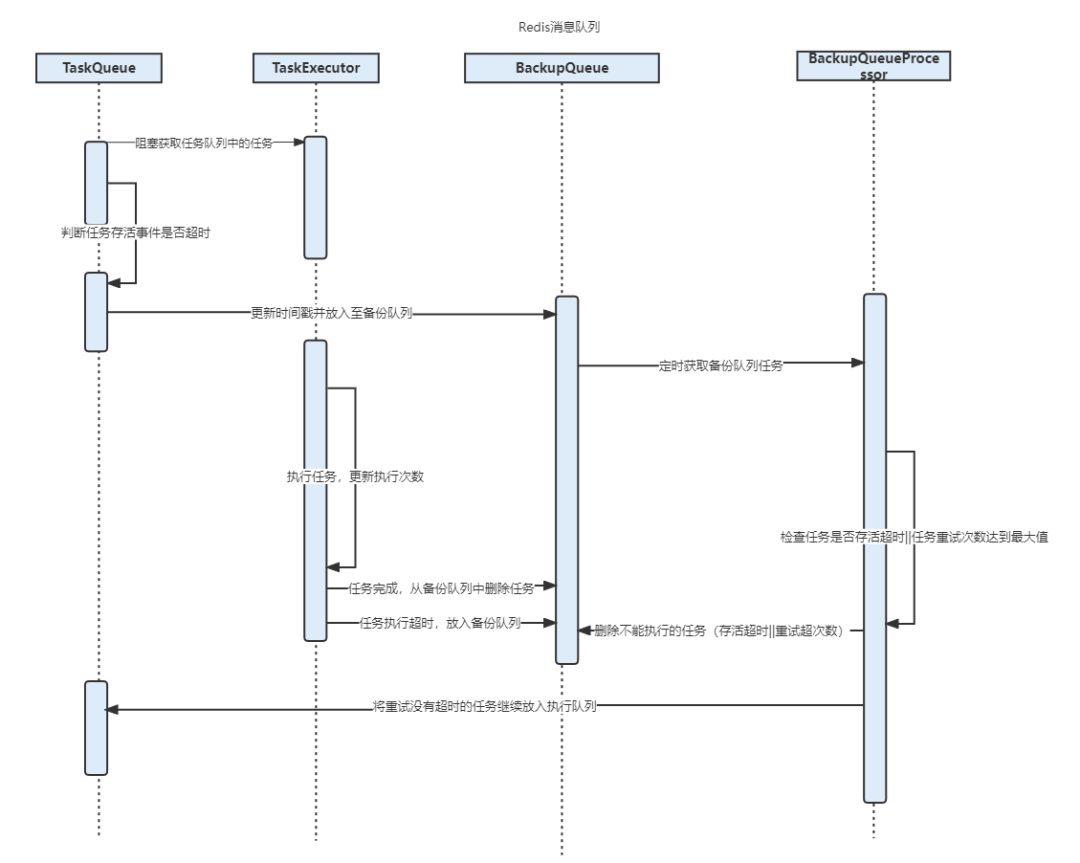
其中基于Redis实现的消息队列的时序图如下
该模块主要是监控任务的状态,当任务开始执行、中断执行、执行成功、执行失败的时候进行通知业务并存储数据,用于保存构建记录,方便后续数据的统计,用来完成数据的可视化.
目前该系统已经投入生产环境运行,Jenkins任务已采用调度系统进行调度执行,运行稳定,运行效果.
。
。
随着vivo Jenkins 调度系统的功能慢慢完善,Jenkins的机器也越来越多,目前还大多数运行在虚拟机上,从资源利用率和业务发布效率来看,未来的业务发布形态将会是以容器为主。目前公司也在大力发展k8s的容器生态建设, 。
所以我们希望将Jenkins工具后期进行容器化、池化,在提高资源利用率和发布效率的同时也可以为用户提供可靠的、简洁的、稳定调度执行.
最后此篇关于vivo自研Jenkins资源调度系统设计与实践的文章就讲到这里了,如果你想了解更多关于vivo自研Jenkins资源调度系统设计与实践的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
27
4
 0
0
我想创建一个 Jenkins 工作来启动其他 Jenkins 工作。这很容易,因为 Jenkins 模板项目插件允许我们创建“使用另一个项目的构建器”类型的构建步骤。然而,让我的情况更难的是我必须在其
我有一个简单的Windows批处理命令(robocopy),该命令返回零错误,但在Jenkins中始终被标记为失败。我想知道为什么? D:\ Jenkins \ jobs \ Jenkins Conf
我有两个 Jenkins 工作 - Jenkins Job1 和 Jenkins Job2。 我有多个应用程序并使用相同的 Jenkins 来构建应用程序。如果相同的应用程序在 Jenkins 中运行
我找不到这两者之间的区别。这些是相同的还是不同的。 最佳答案 第一个区别是支持(正如其他人所提到的)。 CloudBees 提供企业级支持以及经过全面审查和测试的 Jenkins 版本,该版本将在各种
是否可以指定在多次触发作业(A)的情况下,将先前的作业从队列中删除,并且如果有足够的可用插槽,则仅将最新的作业留在队列中或启动? 提前致谢! 最佳答案 您可以使用通过Groovy Script Plu
我有2位Jenkins主持人,并且希望First Jenkins在第一个结果的基础上基于“SUCCESS”触发远程Jenkins上的工作。 我看过各种插件,但它们似乎都表明一个Jenkins主机,可以
我的 jenkinsfile 有几个参数,每次我更新参数(例如删除或添加新输入)并将更改提交到我的 SCM 时,我没有在 jenkins 中看到相应更新的作业输入屏幕,我必须运行执行,取消它,然后查看
有没有办法在构建完成后触发相同的工作。我有一项工作需要运行,直到我手动中止它。有没有办法做到这一点? 最佳答案 最简单的方法是添加一个构建相同项目的后期构建步骤。将“构建后操作”-“构建其他项目”-“
我在 Linux 家中的特定用户下有工作/.jenkins 文件夹。我想与另一个用户一起启动 Jenkins,但重新使用另一个用户的 .jenkins 文件夹。我怎样才能做到这一点? Jenkins
我是 Jenkins 的新手,我不确定这是否可行,但我想设置一个 Web 界面,人们可以在其中单击“开始作业”,这将告诉 Jenkins 开始特定的构建作业。 Jenkins 是否有允许此类操作的网络
如何获取 Jenkins 凭证变量,即“mysqlpassword”,可供 Jenkins 声明性管道的所有阶段访问? 下面的代码片段工作正常并打印我的凭据。 node { stage('Gett
如何获取 Jenkins 凭证变量,即“mysqlpassword”,可供 Jenkins 声明性管道的所有阶段访问? 下面的代码片段工作正常并打印我的凭据。 node { stage('Gett
如何将构建参数从一个项目传递到另一个项目? 我们在 Jenkins 用户界面中是否有任何配置,可以在完成一个构建项目后将构建参数传递给另一个项目? 我能够触发另一个项目,但无法传递构建参数。我们是否有
我正在 Jenkins 中构建一个项目,并希望在它之后立即启动测试,请稍候 直到测试完成,然后运行另一个作业来分析结果。测试系统是一个封闭的系统(我不能修改它)所以为了检查测试是否完成我需要每 X 秒
我创建了一个测试 jenkins 作业管道。此作业具有字符串参数 - 'testVar' Jenkins文件代码: println("env.TESTVAR=" + env.TESTVAR) prin
我的 Jenkins 工作“构建”配置有 3 执行 shell - 构建任务 2 构建后操作 有没有办法获取每个构建任务和构建后操作的运行时间? 最佳答案 不直接,这就是为什么: 我使用 a Jenk
是否有任何适用于 Jenkins 的插件可以为 Jenkins 提供键值存储选项?功能接近的插件是凭据插件。目标是拥有一个存储全局配置参数的插件,并且此参数可用于 Jenkins 作业。 最佳答案 转
默认情况下,Jenkins 是否会保留每个构建中生成的所有构建和工件。或者它会在一段时间后删除它们。我知道我可以配置“丢弃旧版本”选项,但我想知道 Jenkins 的默认行为。 最佳答案 默认是保留所
Jenkins 构建中的每个文件参数“帮助文本”, Accepts a file submission from a browser as a build parameter. The uploade
情况:我在我的虚拟服务器上安装了 Jenkins 并设置了一个“自由式管道”。我通过 webhook push 将它连接到我的 github,它可以工作(当我推送到存储库时,在 jenkins 中启动

我是一名优秀的程序员,十分优秀!