
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 24
24
 4
4


《Terraform 101 从入门到实践》这本小册在 南瓜慢说官方网站 和 GitHub 两个地方同步更新,书中的示例代码也是放在GitHub上,方便大家参考查看.
军书十二卷,卷卷有爷名.
Terraform的主要作用是管理云平台上的资源,通过声明式的HCL配置来映射资源,如果云平台上没有资源则需要创建,如果有则不用。那Terraform要实现这个功能有多种方式.
一种是每次执行apply命令时都调用API接口检查一下远程的云资源是否与配置文件一致,如果没有则创建,如果有但不同则需要修改,如果有且相同则不用变更。这种机制能保证云平台的资源与HCL配置是一致的。缺点也是非常明显的,每次都需要调用API去检查远程资源,效率很低,特别是当资源特别多的场景.
另一种方式是每次变更资源的时候,都会创建一个映射文件,它保存云平台资源的状态。这样每次执行 apply 命令时,只需要检查HCL配置与映射文件的差异即可.
Terraform选择的是第二种方式,通过映射文件来保存资源状态,在Terraform的世界里叫状态文件。Terraform这样做是基于以下考虑:
讲到这里,已经回答了之前在第一章留下的思考题:
如果再次执行apply会不会再次创建一个文件呢?还是创建失败,因为文件已存在?为什么?
答案:不会创建,因为通过状态文件记录了变更,Terraform判断不再需要创建了.
为了更多注意力放在状态管理上,我们还是使用最简单的例子 local_file ,具体代码如下:
resource "local_file" "terraform-introduction" {
content = "https://www.pkslow.com"
filename = "${path.root}/terraform-guides-by-pkslow.txt"
}
我们以实际操作及现象来讲解状态文件的作用和工作原理:
| 操作 | 现象及说明 |
|---|---|
| terraform apply | 生成资源:第一次生成 |
| terraform apply | 没有变化:状态文件生成,不需要再创建 |
| terraform destroy | 删除资源:根据状态文件的内容删除 |
| terraform apply | 生成资源:状态显示没有资源,再次生成 |
| 删除状态文件 | 没有变化 |
| terraform apply | 生成资源:没有状态文件,直接生成资源和状态文件(插件做了容错处理,已存在也会新生成覆盖) |
| 删除状态文件 | 没有变化 |
| terraform destroy | 无法删除资源,没有资源存在的状态 |
我们一直在讲状态文件,我们先来看一下它的真面目。首先它的默认文件名是 terraform.tfstate ,默认会放在当前目录下。它是以 json 格式存储的信息,示例中的内容如下:
{
"version": 4,
"terraform_version": "1.0.11",
"serial": 1,
"lineage": "acb408bb-2a95-65fd-02e6-c23487f7a3f6",
"outputs": {},
"resources": [
{
"mode": "managed",
"type": "local_file",
"name": "test-file",
"provider": "provider[\"registry.terraform.io/hashicorp/local\"]",
"instances": [
{
"schema_version": 0,
"attributes": {
"content": "https://www.pkslow.com",
"content_base64": null,
"directory_permission": "0777",
"file_permission": "0777",
"filename": "./terraform-guides-by-pkslow.txt",
"id": "6db7ad1bbf57df0c859cd5fc62ff5408515b5fc1",
"sensitive_content": null,
"source": null
},
"sensitive_attributes": [],
"private": "bnVsbA=="
}
]
}
]
}
可以看到它记录了Terraform的版本信息,还有资源的详细信息:包括类型、名字、插件、属性等。有这些信息便可直接从状态文件里解析出具体的资源.
可以通过 terraform state 做一些状态管理:
显示状态列表:
$ terraform state list
local_file.test-file
查看具体资源的状态信息:
$ terraform state show local_file.test-file
# local_file.test-file:
resource "local_file" "test-file" {
content = "https://www.pkslow.com"
directory_permission = "0777"
file_permission = "0777"
filename = "./terraform-guides-by-pkslow.txt"
id = "6db7ad1bbf57df0c859cd5fc62ff5408515b5fc1"
}
显示当前状态信息:
$ terraform state pull
重命名:
$ terraform state mv local_file.test-file local_file.pkslow-file
Move "local_file.test-file" to "local_file.pkslow-file"
Successfully moved 1 object(s).
$ terraform state list
local_file.pkslow-file
要注意这里只是修改状态文件的名字,代码里的HCL并不会修改.
删除状态里的资源:
$ terraform state rm local_file.pkslow-file
Removed local_file.pkslow-file
Successfully removed 1 resource instance(s).
状态文件默认是在本地目录上的 terraform.tfstate 文件,在团队使用中,每个人的电脑环境独立的,那么需要保证每个人当前的状态文件都是最新且与现实资源真实对应,简直是天方夜谭。而状态不一致所带的灾难也是极其可怕的。所以,状态文件最好是要存储在一个独立的大家可共同访问的位置。对于状态的管理的配置,Terraform称之为 Backends .
Backend 是两种模式,分别是 local 和 remote 。 local 模式很好理解,就是使用本地路径来存储状态文件。配置示例如下:
terraform {
backend "local" {
path = "pkslow.tfstate"
}
}
通过这样配置后,不再使用默认的 terraform.tfstate 文件,而是使用自定义的文件名 pkslow.tfstate .
对于 remote 模式,则有多种配置方式,Terraform支持的有:
等,能满足主流云平台的需求。每一个配置可以参考官网,在本地我采用数据库postgresql的方式,让大家都能快速实验.
我通过Docker的方式启动PostgreSQL,命令如下:
$ docker run -itd \
--name terraform-postgres \
-e POSTGRES_DB=terraform \
-e POSTGRES_USER=pkslow \
-e POSTGRES_PASSWORD=pkslow \
-p 5432:5432 \
postgres:13
在 terraform 块中配置 backend ,这里指定数据库连接信息即可,更多参数请参考: https://www.terraform.io/language/settings/backends/pg 。
terraform {
backend "pg" {
conn_str = "postgres://pkslow:pkslow@localhost:5432/terraform?sslmode=disable"
}
}
当然,把敏感信息直接放在代码中并不合适,可以直接在命令行中传入参数:
terraform init -backend-config="conn_str=postgres://pkslow:pkslow@localhost:5432/terraform?sslmode=disable"
执行init和apply之后,连接数据库查看,会创建一个叫 terraform_remote_state 的Schema,在该Schema下有一张states表来存储对应的状态信息,如下:
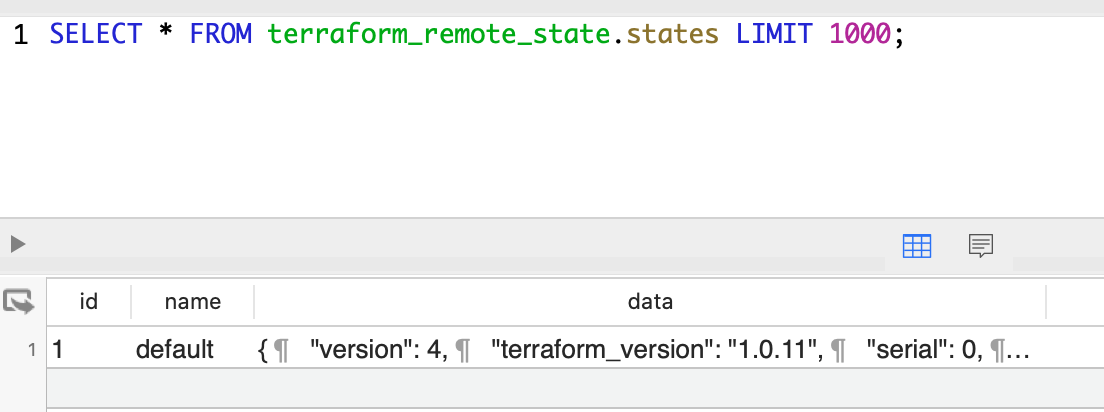
表中字段name是namespace,而data是具体的状态信息,如下:
{
"version": 4,
"terraform_version": "1.0.11",
"serial": 0,
"lineage": "de390d13-d0e0-44dc-8738-d95b6d8f1868",
"outputs": {},
"resources": [
{
"mode": "managed",
"type": "local_file",
"name": "test-file",
"provider": "provider[\"registry.terraform.io/hashicorp/local\"]",
"instances": [
{
"schema_version": 0,
"attributes": {
"content": "https://www.pkslow.com",
"content_base64": null,
"directory_permission": "0777",
"file_permission": "0777",
"filename": "./terraform-guides-by-pkslow.txt",
"id": "6db7ad1bbf57df0c859cd5fc62ff5408515b5fc1",
"sensitive_content": null,
"source": null
},
"sensitive_attributes": [],
"private": "bnVsbA=="
}
]
}
]
}
如果我们用Terraform代码生成了dev环境,但现在需要uat环境,该如何处理呢?
首先,不同环境的变量一般是不一样的,我们需要定义各种的变量文件如 dev.tfvars 、 uat.tfvars 和 prod.tfvars 等。但只有各自变量是不够的,因为还有状态。状态也必须要隔离,而 Workspace 就是Terraform用来隔离状态的方式。默认的工作区为 default ,如果没有指定,则表示工作于 default 工作区中。而当指定了工作区,状态文件就会与工作区绑定.
创建一个工作区并切换:
$ terraform workspace new pkslow
切换到已存在的工作区:
$ terraform workspace select pkslow
而当我们处于某个工作区时,是可以获取工作区的名字的,引用为: ${terraform.workspace} ,示例如下:
resource "aws_instance" "example" {
count = "${terraform.workspace == "default" ? 5 : 1}"
# ... other arguments
}
之前讲过默认的状态文件名为 terraform.tfstate ;而在多工作区的情况下(只要你创建了一个非默认工作区),状态文件就会存在 terraform.tfstate.d 目录下。而在远程状态的情况下,也会有一个映射,Key为工作区名,Value一般是状态内容.
本地状态文件都是明文存储状态信息的,所以要保护好自己的状态文件。对于远程状态文件,有些存储方案是支持加密的,会对敏感数据( sensitive )进行加密.
本地状态文件下不需要状态锁,因为只有一个人在变更。而远程状态的情况下,就可能出现竞争了。比如一个人在apply,而另一个人在destroy,那就乱了。而状态锁可以确保远程状态文件只能被一个人使用。但不是所有远程状态的方式都支持锁的,一般常用的都会支持,如GCS、S3等.
所以,每当我们在执行变更时,Terraform总会先尝试去拿锁,如果拿锁失败,就该命令失败。可以强制解锁,但要非常小心,一般只建议在自己明确知道安全的时候才使用,比如死锁了.
既然远程状态文件是可以共享的,那状态信息也是可以共享的。这样会带来的一个好处是,即使两个根模块,也是可以共享信息的。比如我们在根模块A创建了一个数据库,而根模块B需要用到数据库的信息如IP,这样通过远程状态文件就可以共享给根模块B了.
注意这里我强调的是根模块,因为如果A和B在同一个根模块下,那就不需要通过远程状态的方式来共享状态了.
远程状态的示例:
data "terraform_remote_state" "vpc" {
backend = "remote"
config = {
organization = "hashicorp"
workspaces = {
name = "vpc-prod"
}
}
}
resource "aws_instance" "foo" {
# ...
subnet_id = data.terraform_remote_state.vpc.outputs.subnet_id
}
本地状态的示例:
data "terraform_remote_state" "vpc" {
backend = "local"
config = {
path = "..."
}
}
resource "aws_instance" "foo" {
# ...
subnet_id = data.terraform_remote_state.vpc.outputs.subnet_id
}
要注意的是,只有根模块的输出变量才能被共享,子模块是不能被获取的.
最后此篇关于《Terraform101从入门到实践》第四章States状态管理的文章就讲到这里了,如果你想了解更多关于《Terraform101从入门到实践》第四章States状态管理的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
24
4
 0
0
Hive —— 入门 Hive介绍 Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一
HBase —— 入门 HBase介绍 HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”
零:前端目前形势 前端的发展史 HTML(5)、CSS(3)、JavaScript(ES5、ES6):编写一个个的页面 -> 给后端(PHP、Python、Go、Java) ->
在本教程中,您将了解在计算机上运行 JavaScript 的不同方法。 JavaScript 是一种流行的编程语言,具有广泛的应用程序。 JavaScript 以前主要用于使网页具有交
我曾经是一个对编程一窍不通的小白,但因为对互联网世界的好奇心和求知欲的驱使,我踏入了编程的殿堂。在学习的过程中,我发现了一门神奇的编程语言——Python。Python有着简洁、易读的语法,让初学者能
嗨,亲爱的读者们! 今天我要给大家分享一些关于Python爬虫的小案例。你是否曾为了获取特定网页上的数据而烦恼过?或者是否好奇如何从网页中提取信息以供自己使用?那么,这篇文章将会给你一些启示和灵感。
关闭。这个问题是opinion-based 。目前不接受答案。 想要改进这个问题吗?更新问题,以便 editing this post 可以用事实和引文来回答它。 . 已关闭 8 年前。 Improv
我想创建一个像https://apprtc.appspot.com/?r=04188292这样的应用程序。我对 webrtc 了解一点,但无法掌握 google app-engine。如何为 java
我刚刚开始使用 Python 并编写了一个简单的周边程序。但是,每当我在终端中键入 python perimeter.py 时,都会收到以下错误,我不知道如何解决。 >>> python perime
Redis有5个基本数据结构,string、list、hash、set和zset。它们是日常开发中使用频率非常高应用最为广泛的数据结构,把这5个数据结构都吃透了,你就掌握了Redis应用知识的一半了
创建发布web项目 具体步骤: 1.在开发工具中创建一个dynamic web project helloword 2.在webContent中创建index.html文件 3.发布web应用到
如果你在 Ubuntu 上使用终端的时间很长,你可能会希望调整终端的字体和大小以获取一种良好的体验。 更改字体是一种最简单但最直观的 Linux 的终端自定义 的方法。让我
1. 前言 ADODB 是 Active Data Objects Data Base 的简称,它是一种 PHP 存取数据库的函式组件。现在 SFS3 系统 (校园自由软件交流网学务系统) 计划的
我对 neo4j 完全陌生,我很抱歉提出这样一个基本问题。我已经安装了neo4j,我正在使用shell“localhost:7474/webadmin/#/console/” 我正在寻找一个很好的例子
我正在阅读 ios 4 的核心音频,目的是构建一个小测试应用程序。 在这一点上,我对所有 api 的研究感到非常困惑。理想情况下,我想知道如何从两个 mp3 中提取一些样本到数组中。 然后在回调循环中
关闭。这个问题不符合Stack Overflow guidelines .它目前不接受答案。 要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于 Stack Overflow 来说是无关紧要的,因
我下载了 GNUStep并安装了它,但是我不确定在哪里可以找到 IDE。有谁知道什么程序可以用作 GNUStep IDE/从哪里获取它们?否则,有没有人知道有关如何创建和编译基本 GNUStep 程序
我正在尝试开始使用 Apache Solr,但有些事情我不清楚。通读tutorial ,我已经设置了一个正在运行的 Solr 实例。我感到困惑的是 Solr 的所有配置(架构等)都是 XML 格式的。
请问有没有关于如何开始使用 BruTile 的文档? 我目前正在使用 SharpMap,我需要预缓存切片以加快进程 最佳答案 我今天正在研究这个:)Mapsui项目site严重依赖 SharpMap
尽我所能,我无法让 CEDET 做任何事情。 Emacs 24.3。我下载了最新的 CEDET 快照。我从他的底部(不是这样)Gentle Introduction 中获取了 Alex Ott 的设置

我是一名优秀的程序员,十分优秀!