
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 28
28
 4
4


作者信息:
唐聪、王超凡,腾讯云原生产品中心技术专家,负责腾讯云大规模 TKE 集群和 etcd 控制面稳定性、性能和成本优化工作.
王子勇,腾讯云专家级工程师, 腾讯云计算产品技术服务专家团队负责人.
作为当前中国广泛使用的云视频会议产品,腾讯会议已服务超过 3 亿用户,能高并发支撑千万级用户同时开会。腾讯会议数百万核心服务都部署在腾讯云 TKE 上,通过全球多地域多集群部署实现高可用容灾。在去年用户使用最高峰期间,为了支撑更大规模的并发在线会议的人数,腾讯会议与 TKE 等各团队进行了一轮新的扩容.
然而,在这过程中,一个简单的 etcd 进程重启操作却触发了一个的诡异的 K8s 故障(不影响用户开会,影响新一轮后台扩容效率),本文介绍了我们是如何从问题现象、到问题分析、大胆猜测排除、再次复现、严谨验证、根治隐患的,从 Kubernetes 到 etcd 底层原理,从 TCP RFC 草案再到内核 TCP/IP 协议栈实现,一步步定位并解决问题的详细流程(最终定位到是特殊场景触发了内核 Bug).
希望通过本文,让大家对 etcd、Kubernetes 和内核的复杂问题定位有一个较为深入的了解,掌握相关方法论,同时也能让大家更好的了解和使用好 TKE,通过分享我们的故障处理过程,提升我们的透明度.
首先给大家简要介绍下腾讯会议的简要架构图和其使用的核心产品 TKE Serverless 架构图.
腾讯会议极简架构图如下
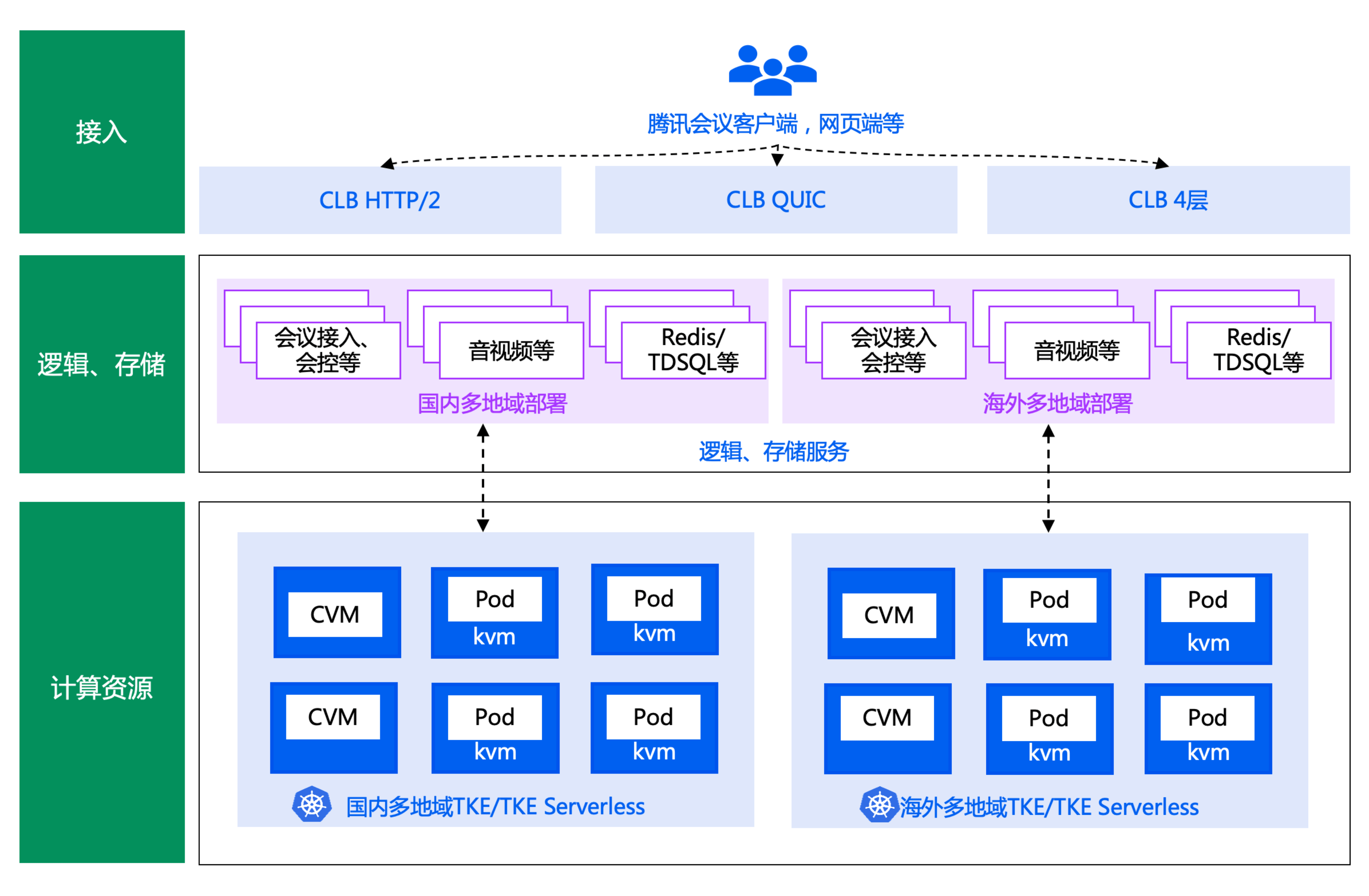
腾讯会议重度使用的 TKE Serverless 架构如下
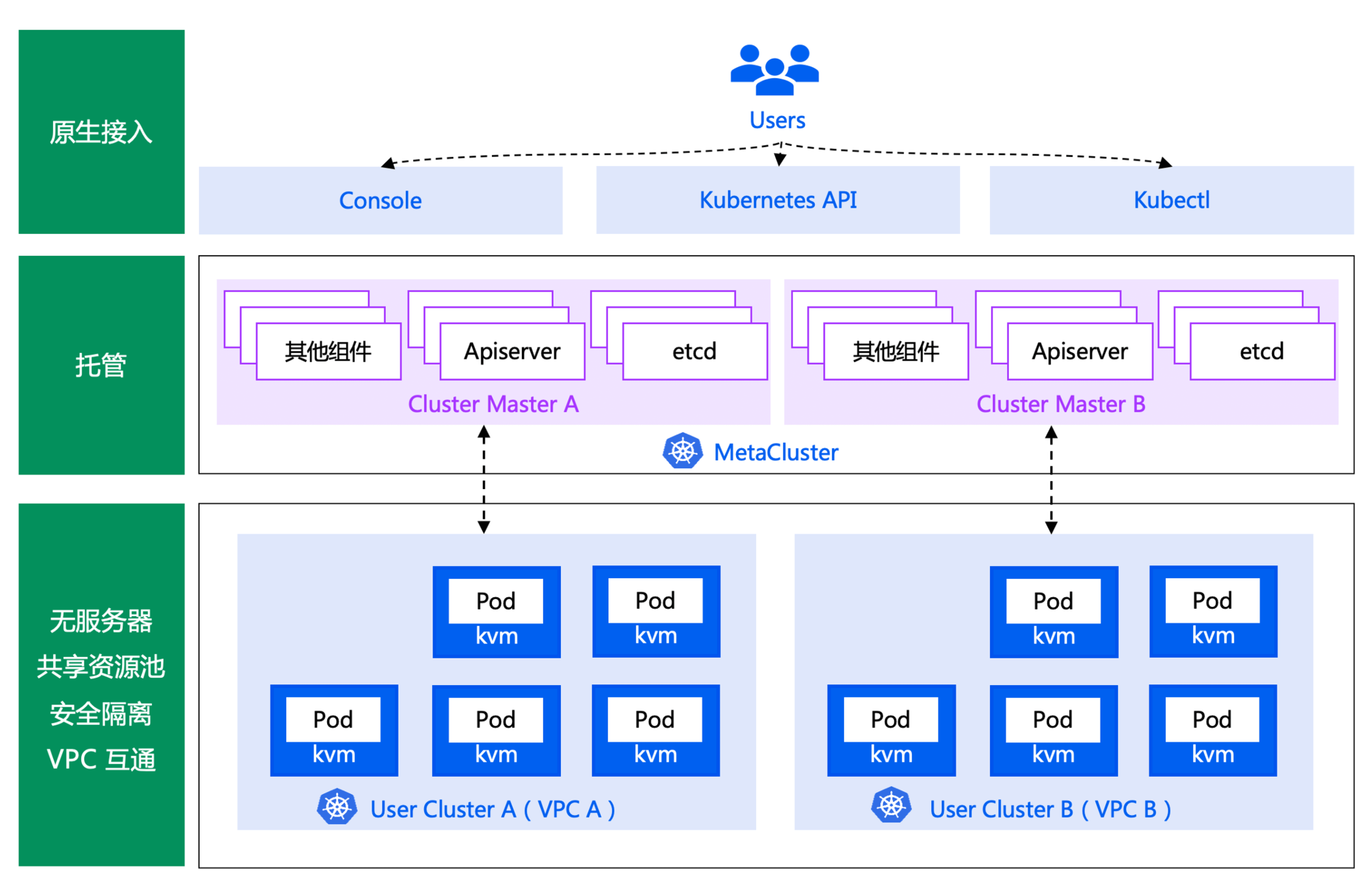
腾讯会议几乎全部业务都跑在 TKE Serverless 产品上,Master 组件部署在我们metacluster 中(K8s in K8s),超大集群可能有10多个 APIServer,etcd 由服务化的 etcd 平台提供,APIServer 访问 etcd 链路为 svc -> cluster-ip -> etcd endpoint。业务各个 Pod 独占一个轻量级的虚拟机,安全性、隔离性高,业务无需关心任何 Kubernetes Master、Node 问题,只需要专注业务领域的开发即可.
在一次资源扩容的过程中,腾讯会议的研发同学晚上突然在群里反馈他们上海一个最大集群出现了业务扩容失败,收到反馈后研发同学,第一时间查看后,还看到了如下异常
● 部分 Pod 无法创建、销毁 。
● 某类资源 Get、list 都是超时 。
● 个别组件出现了 Leader Election 错误 。
● 大部分组件正常,少部分控制器组件有如下 list pvc 资源超时日志 。
k8s.io/client-go/informers/factory.go:134: Failed to watch
*v1.PersistentVolumeClaim: failed to list
*v1.PersistentVolumeClaim: the server was unable to return a
response in the time allotted, but may still be processing the
request (get persistentvolumeclaims)
然而 APIServer 负载并不高,当时一线研发同学快速给出了一个控制面出现未知异常的结论。随后 TKE 团队快速进入攻艰模式,开始深入分析故障原因.
研发团队首先查看了此集群相关变更记录,发现此集群在几个小时之前,进行了重启 etcd 操作。变更原因是此集群规模很大,在之前的多次扩容后,db size 使用率已经接近 80%,为了避免 etcd db 在业务新一轮扩容过程中被写满,因此系统进行了一个经过审批流程后的,一个常规的调大 etcd db quota 操作,并且变更后系统自检 etcd 核心指标正常.
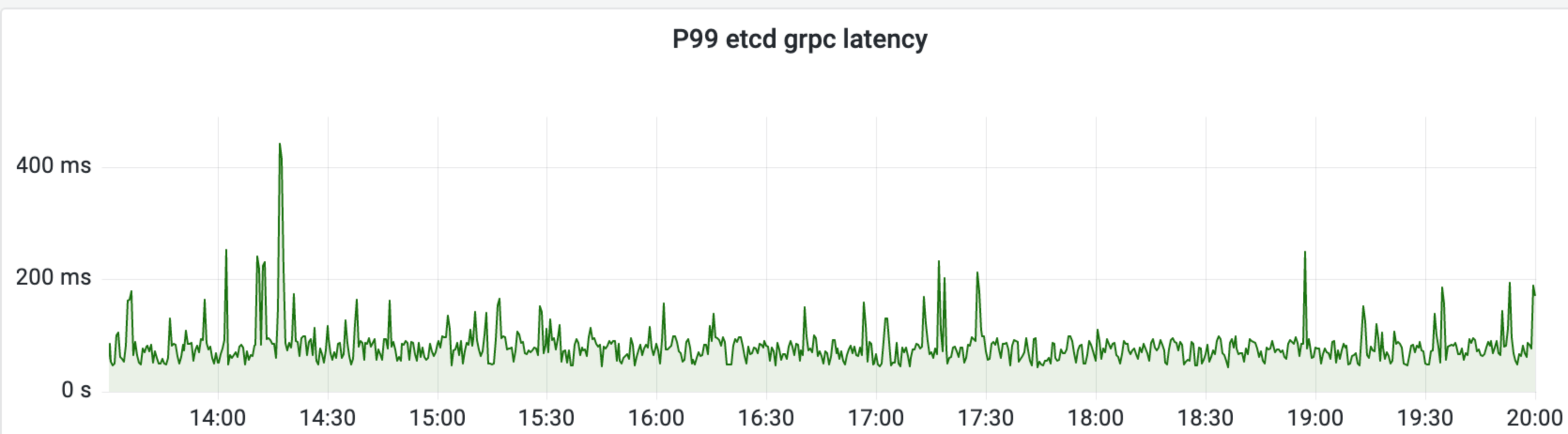
我们首先分析了 etcd 的接口延时、带宽、watch 监控等指标,如下图所示, etcd P99 延时毛刺也就 500ms,节点带宽最大的是平均 100MB/s 左右,初步看并未发现任何异常.
随后又回到 APIServer,一个在请求在 APIServer 内部经历的各个核心阶段(如下图所示)
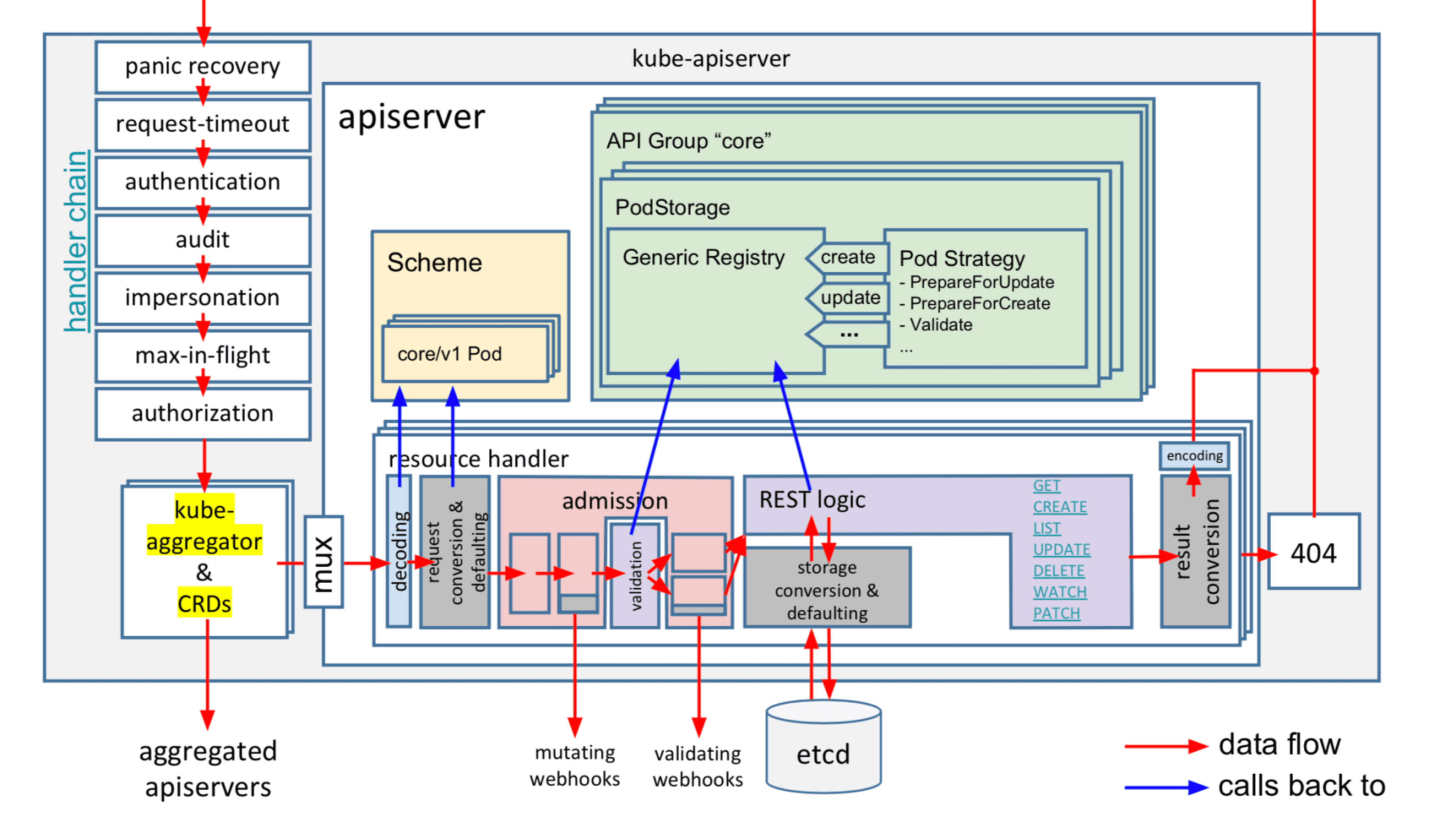
● 鉴权 (校验用户 token、证书是否正确) 。
● 审计 。
● 授权 (检查是否用户是否有权限访问对应资源) 。
● 限速模块 (1.20 后是优先级及公平管理) 。
● mutating webhook 。
● validating webhook 。
● storage/cache 。
● storage/etcd 。
请求在发往 APIServer 前,client 可能导致请求慢的原因: ● client-go 限速,client-go 默认 qps 5, 如果触发限速,则日志级别 4 以上(高版本 client-go 日志级别 3 以上)可以看到客户端日志中有打印 Throttling request took 相关日志 。
那到底是哪个阶段出现了问题,导致 list pvc 接口超时呢?
● 根据 client QPS 很高、并且通过 kubectl 连接异常实例也能复现,排除了 client-go 限速和 client 到 apiserver 网络连接问题 。
● 通过审计日志搜索到不少 PVC 资源的 Get 和 list 5XX 错误,聚集在其中一个实例 。
● 通过 APIServer Metrics 视图和 trace 日志排除 webhook 导致的超时等 。
● 基于 APIServer 访问 etcd 的 Metrics、Trace 日志确定了是 storage/etcd 模块耗时很长,但是只有一个 APIServer 实例、某类资源有问题 。
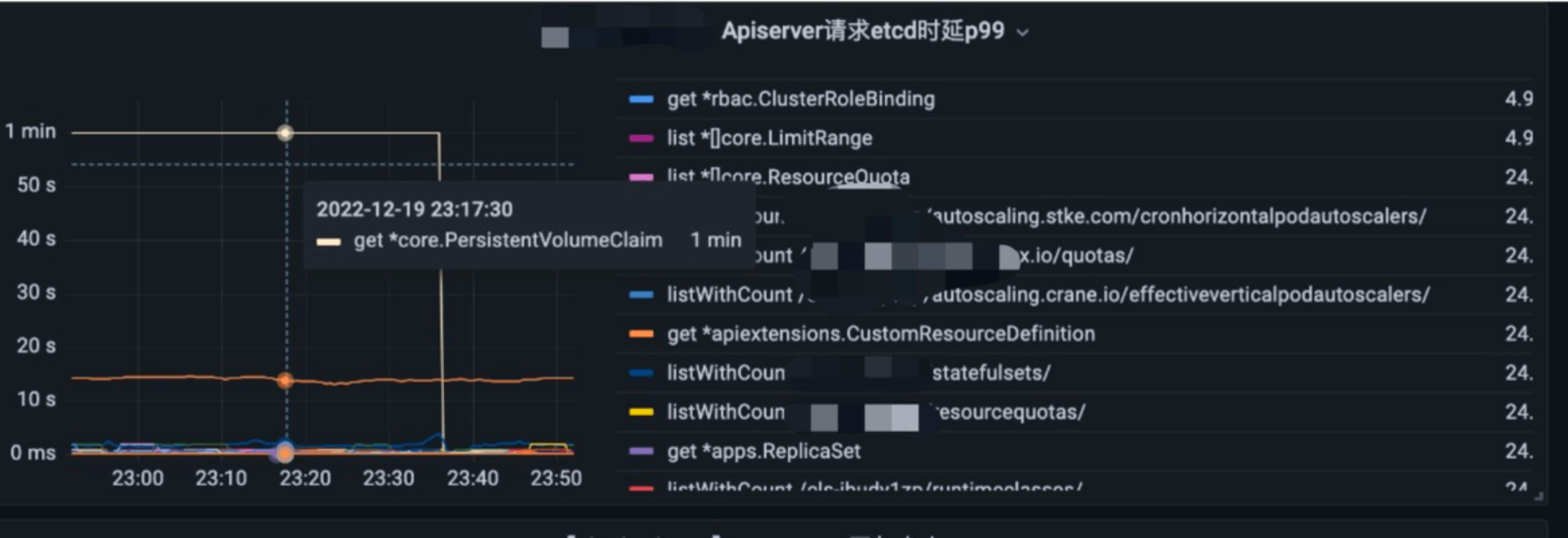
那为什么 etcd 侧看到的监控延时很低,而 APIServer 访问 etcd 延时很高,而且只是某类资源出现问题,不是所有资源呢?
首先,我们查看下 APIServer 的 etcd 延时统计上报代码 (以 Get 接口为例):

它统计的是整个 Get 请求(实际调用的是 etcd Range 接口)从 client 发出到收到结果的耗时, 包括了整个网络链路和 etcd RPC 逻辑处理耗时 .
而 etcd 的 P99 Range 延时是基于 gRPC 拦截器机制实现的,etcd 在启动 gRPC Server 的时候,会注册一个一元拦截器实现延时统计,在 RPC 请求入口和执行 RPC 逻辑完成时上报延时, 也就是它并不包括 RPC 请求在数据接收和发送过程中的耗时 ,相关逻辑封装在 monitor 函数中,简要逻辑如下所示
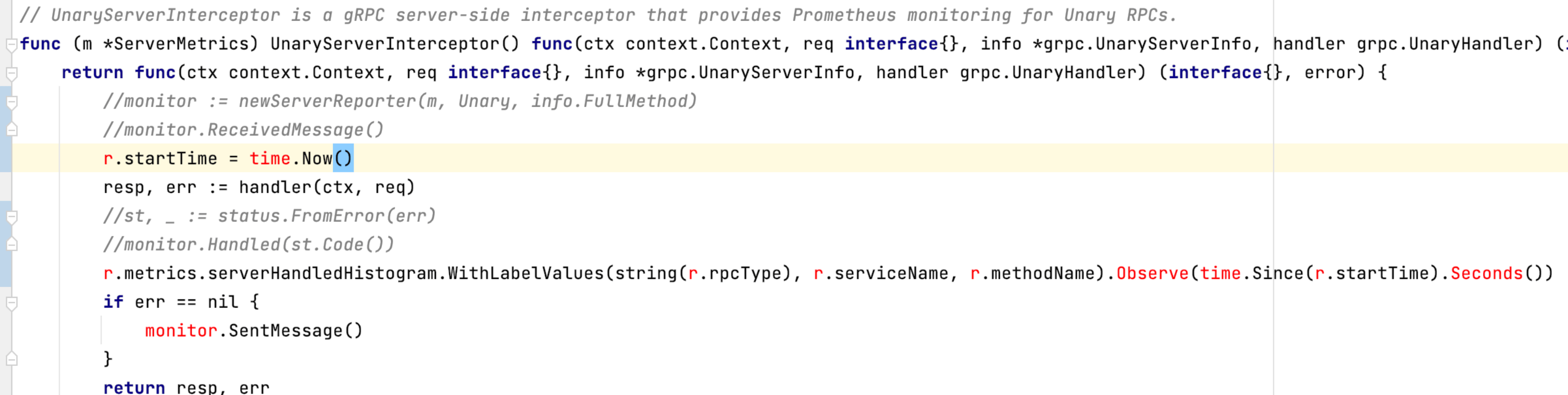
最后一个疑问为什么是某类资源出现问题?
APIServer 在启动的时候,会根据 Kubernetes 中的每个资源和版本创建一个独立etcd client,并根据配置决定是否开启 watch cache,每个 client 一般 1 个 TCP 连接,一个 APIServer 实例会高达上百个 etcd 连接。etcd client 与 etcd server 通信使用的是 gRPC 协议,而 gRPC 协议又是基于 HTTP/2 协议的.
PVC 资源超时,Pod、Node 等资源没超时,这说明是 PVC 资源对应的底层 TCP 连接/应用层 HTTP/2 连接出了问题.
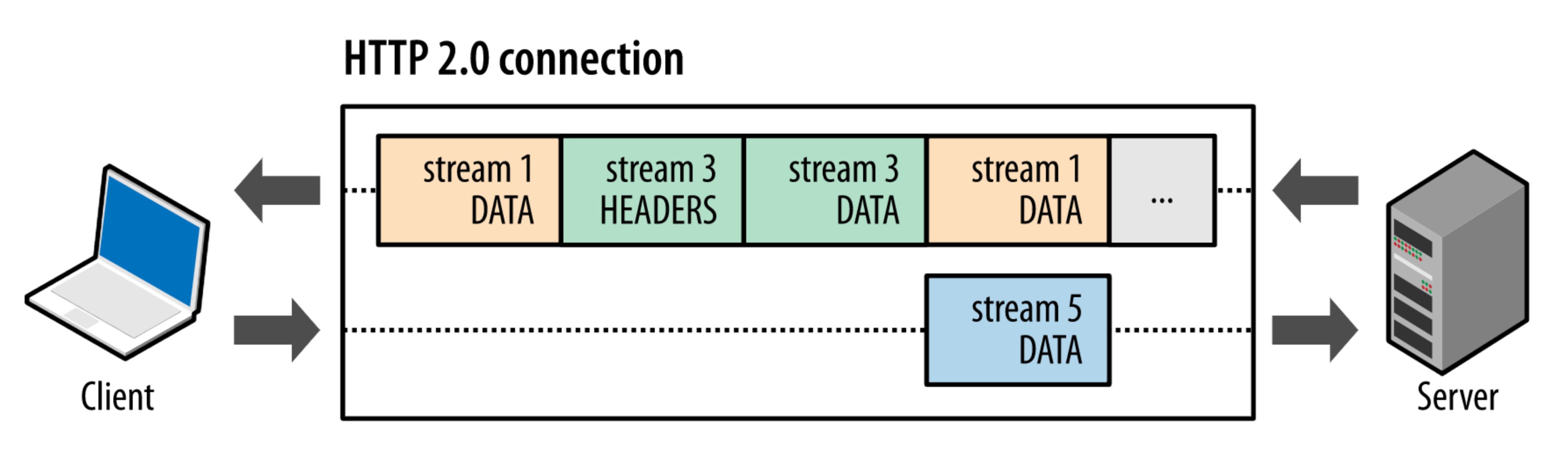
在 HTTP/2 协议中,消息被分解独立的帧(Frame),交错发送,帧是最小的数据单位。每个帧会标识属于哪个流(Stream),流由多个数据帧组成,每个流拥有一个唯一的 ID,一个数据流对应一个请求或响应包。如上图所示,client 正在向 server 发送数据流 5 的帧,同时 server 也正在向 client 发送数据流 1 和数据流 3 的一系列帧。一个连接上有并行的三个数据流,HTTP/2 可基于帧的流 ID 将并行、交错发送的帧重新组装成完整的消息.
也就是,通过 HTTP/2 的多路复用机制,一个 etcd HTTP/2 连接,可以满足高并发情况下各种 client 对 PVC 资源的查询、创建、删除、更新、Watch 请求.
那到底是这个连接出了什么问题呢?
明确是 APIServer 和 etcd 的网络链路出现了异常之后,我们又有了如下猜测:
● 异常实例 APIServer 所在节点出现异常 。
● etcd 集群 3 个节点底层网络异常 。
● etcd HTTP/2 连接最大并发流限制 (单 HTTP/2 连接最大同时打开的并发流是有限制的) 。
● TCP 连接触发了内核未知 bug,连接疑似 hang 住一样 。
● ..... 。
然而我们对 APIServer 和 etcd 节点进行了详细的系统诊断、网络诊断,除了发现 etcd 节点出现了少量毛刺丢包,并未发现其他明显问题,当前 etcd 节点也仅使用了 1/3 的节点带宽,但是请求依然巨慢,因此基本可以排除带宽超限导致的请求超时.
etcd HTTP/2 连接最大并发流限制的特点是此类资源含有较大的并发请求数、同时应有部分成功率,不应全部超时。然而通过我们一番深入排查,通过审计日志、Metrics 监控发现 PVC 资源的请求绝大部分都是 5XX 超时错误,几乎没有成功的,同时我们发现了一个 CR 资源也出现了连接异常,但是它的并发请求数很少。基于以上分析,etcd HTTP/2 连接最大并发流限制猜测也被排除.
问题再次陷入未知,此刻,就要寄出终极杀器——抓包大法,来分析到底整个 TCP 连接链路发生了什么.
要通过抓包来分析具体请求,首先我们就要面临一个问题,当前单个 APIServer 到 etcd 同时存在上百个连接,我们该如何缩小范围,定位到具体异常的 TCP 连接呢?要定位到具体的异常连接,主要会面临以下几个问题:
为了定位到具体的异常连接,我们做了以下几个尝试:
定位到异常连接后,接下来就是分析该连接具体为什么异常,通过分析我们发现 etcd 回给 APIServer 的包都很小,每个 TCP 包都是 100 字节以下:
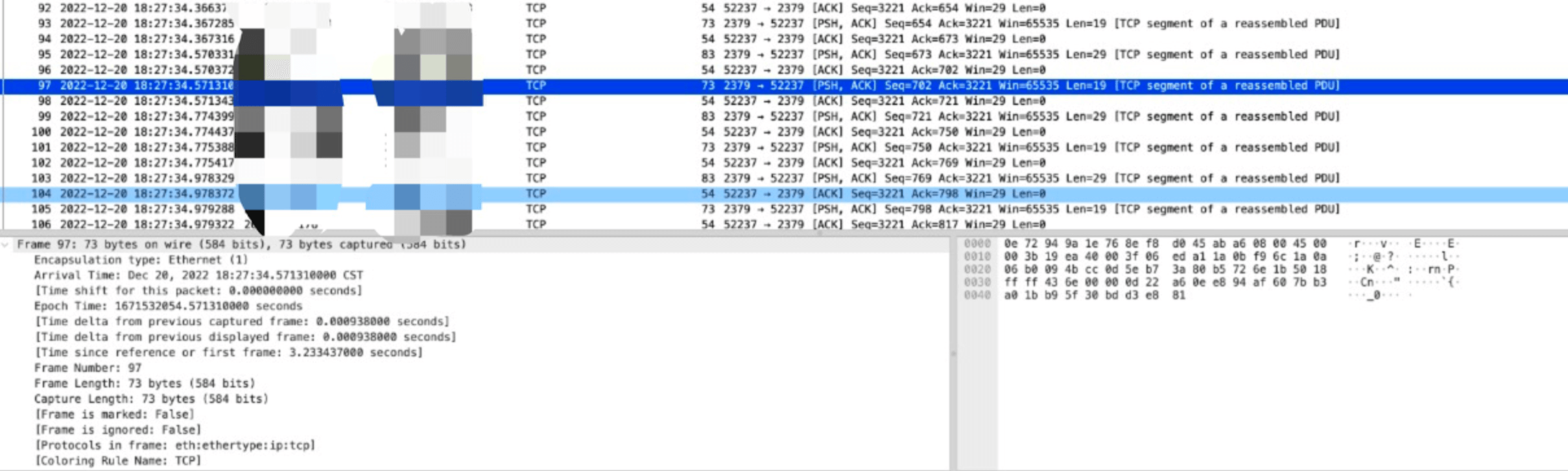
通过 ss 命令查看连接的 TCP 参数,发现 MSS 居然只有 48 个字节:
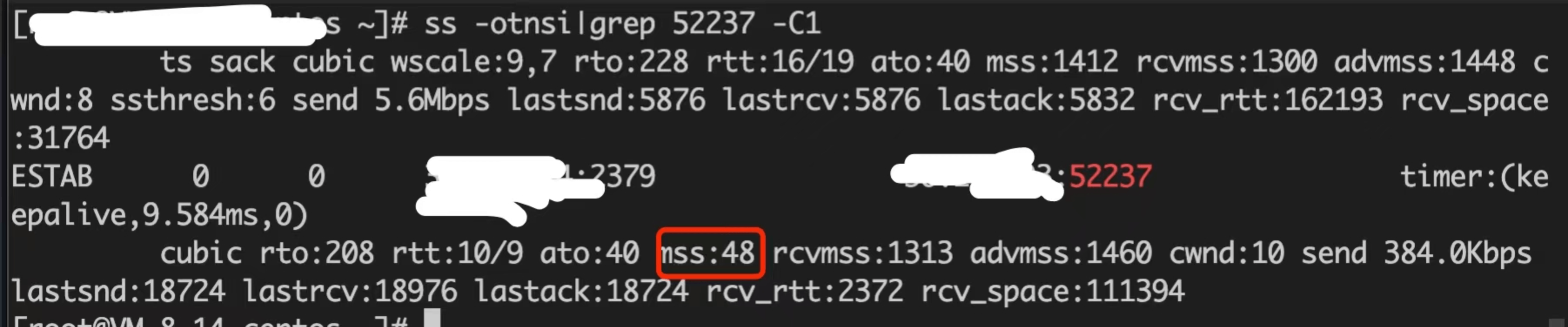
这里简单介绍下 TCP MSS(maximum segment size)参数, 中文名最大分段大小,单位是字节,它限制每次网络传输的数据包的大小,一个请求由多个数据包组成,MSS 不包括 TCP 和 IP 协议包头部分。TCP 中还有一个跟包大小的参数是 MTU(maximum transmission unit),中文名是最大传输单位,它是互联网设备(路由器等)可以接收的最大数据包的值,它包括 TCP 和 IP 包头,以及 MSS.
受限于 MTU 值大小(最大1500),MTU 减去 TCP 和 IP 包头,云底层网络转发所使用的协议包头,MSS 一般在1400左右。然而在我们这里,如下图所示,对 ss 统计分析可以看到,有 10 几个连接 MSS 只有 48 和 58。任意一个请求尤其是查询类的,都会导致请求被拆分成大量小包发送,应用层必定会出现各类超时错误,client 进而又会触发各种重试,最终整个连接出现完全不可用.
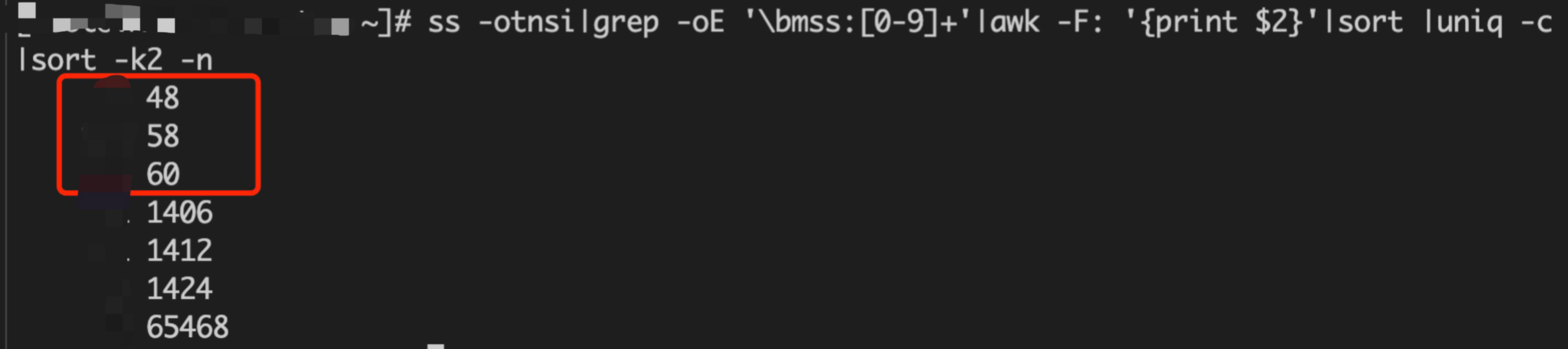
在确定是 MSS 值过小导致上层各种诡异超时现象之后,我们进一步思考,是什么地方改掉了 MSS。然而 MSS 协商是在三次握手中建立的,存量的异常连接比较难找到相关信息.
为了进一步搞清楚问题发生的根本原因,我们在风险可控的情况下,在业务低峰期,凌晨1点,主动又做了一次相似的变更,来尝试复现问题。从抓到的包看 TCP 的选项,发现 MSS 协商的都是比较大,没有特别小的情况:

仅 SYN, SYN+ack 包带有 MSS 选项,并且值都大于 1000, 排除底层网络设备篡改了 MSS 造成的问题.
那内核当中,什么地方会修改 MSS 的值?
假设一开始不了解内核代码,但是我们能知道这个 MSS 字段是通过 ss 命令输出的,那么可以从 ss 命令代码入手。该命令来自于 iproute2 这个包,搜索下 MSS 关键词, 可知在 ss 程序中,通过内核提供的 sock_diag netlink 接口, 查询到的信息。在tcp_show_info函数中做解析展示:
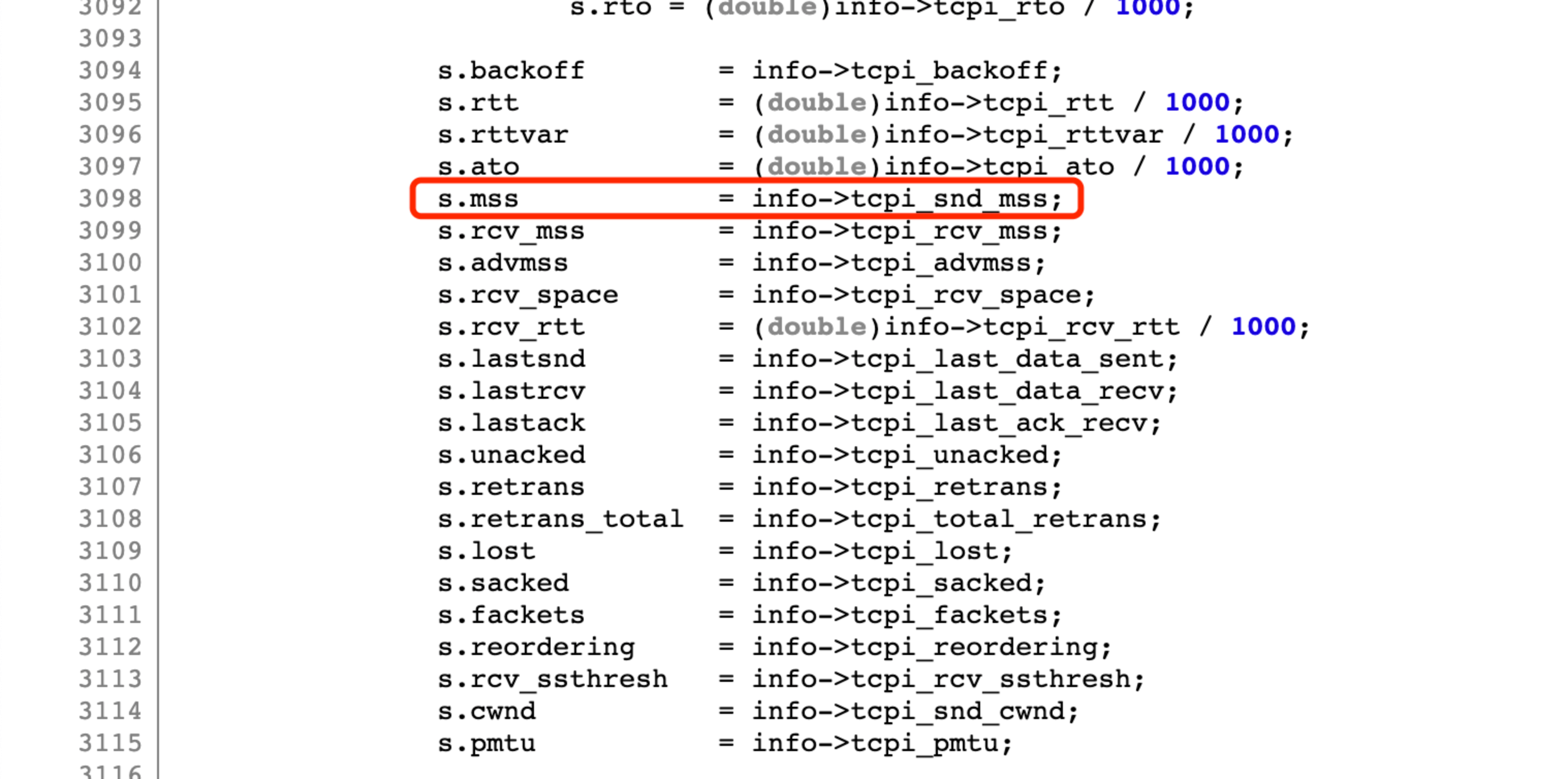
可知 MSS 字段来自内核的 tcpi_snd_mss.
之后,从内核里面查找该值赋值的地方:
2 2749 net/ipv4/tcp.c <<tcp_get_info>>
info->tcpi_snd_mss = tp->mss_cache;
继续找mss_cache的赋值位置:
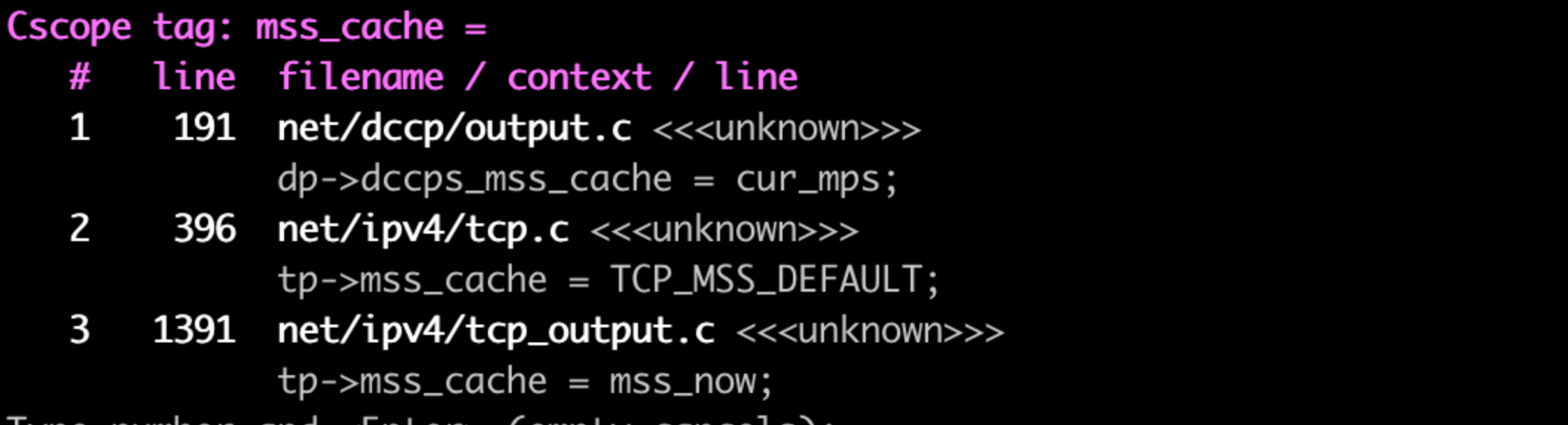
只有2处,第一处是tcp_init_sock中调用,当中的赋值是初始值 tcp_mss_DEFAULT 536U , 与抓到的现场不匹配,直接可忽略.
第二处:
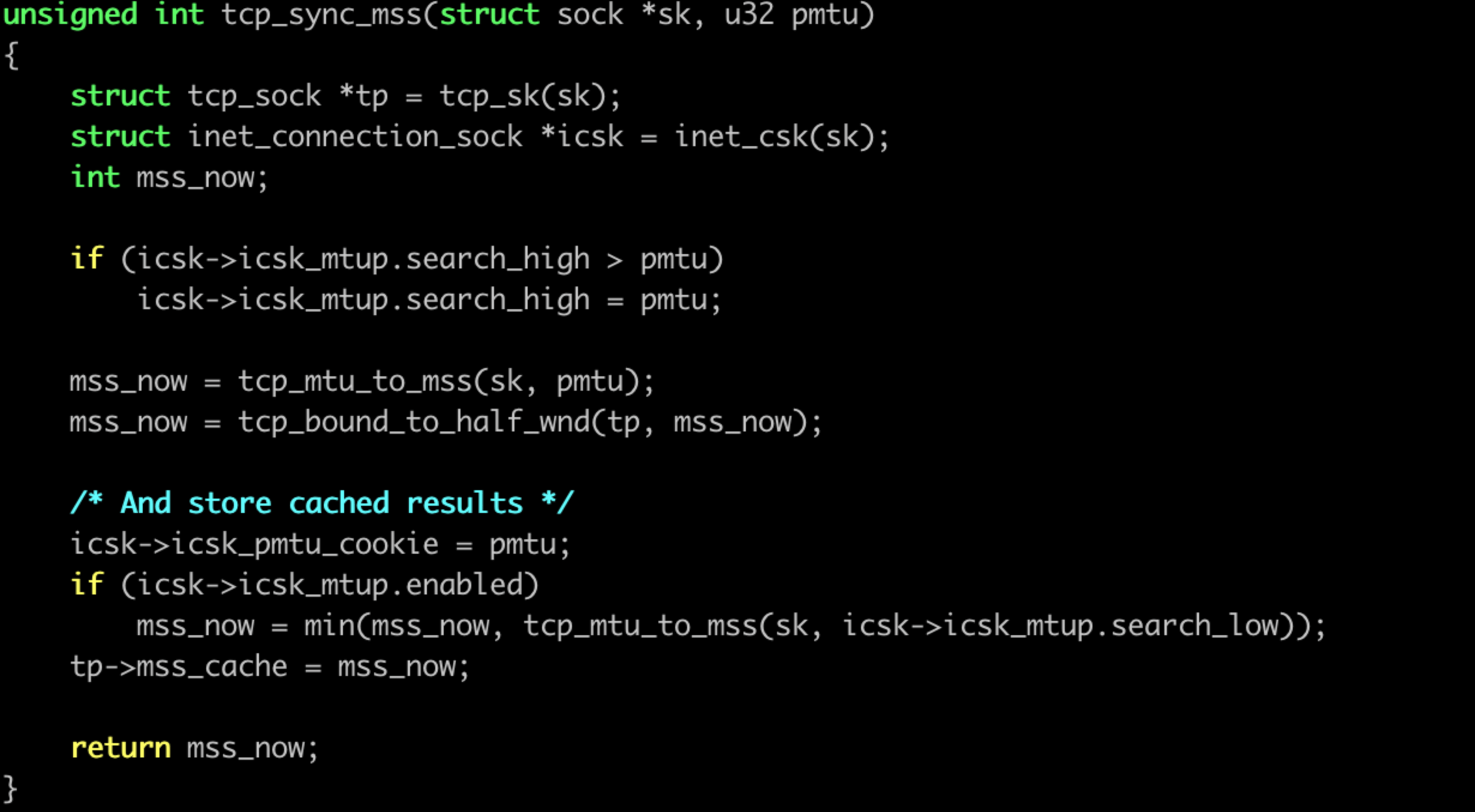
这里面可能 2 个地方会影响,一个是pmtu, 另外一个是 tcp_bound_to_half_wnd. 。
抓包里面没明显看到 MTU 异常造成的流异常反馈信息。聚焦在窗口部分:
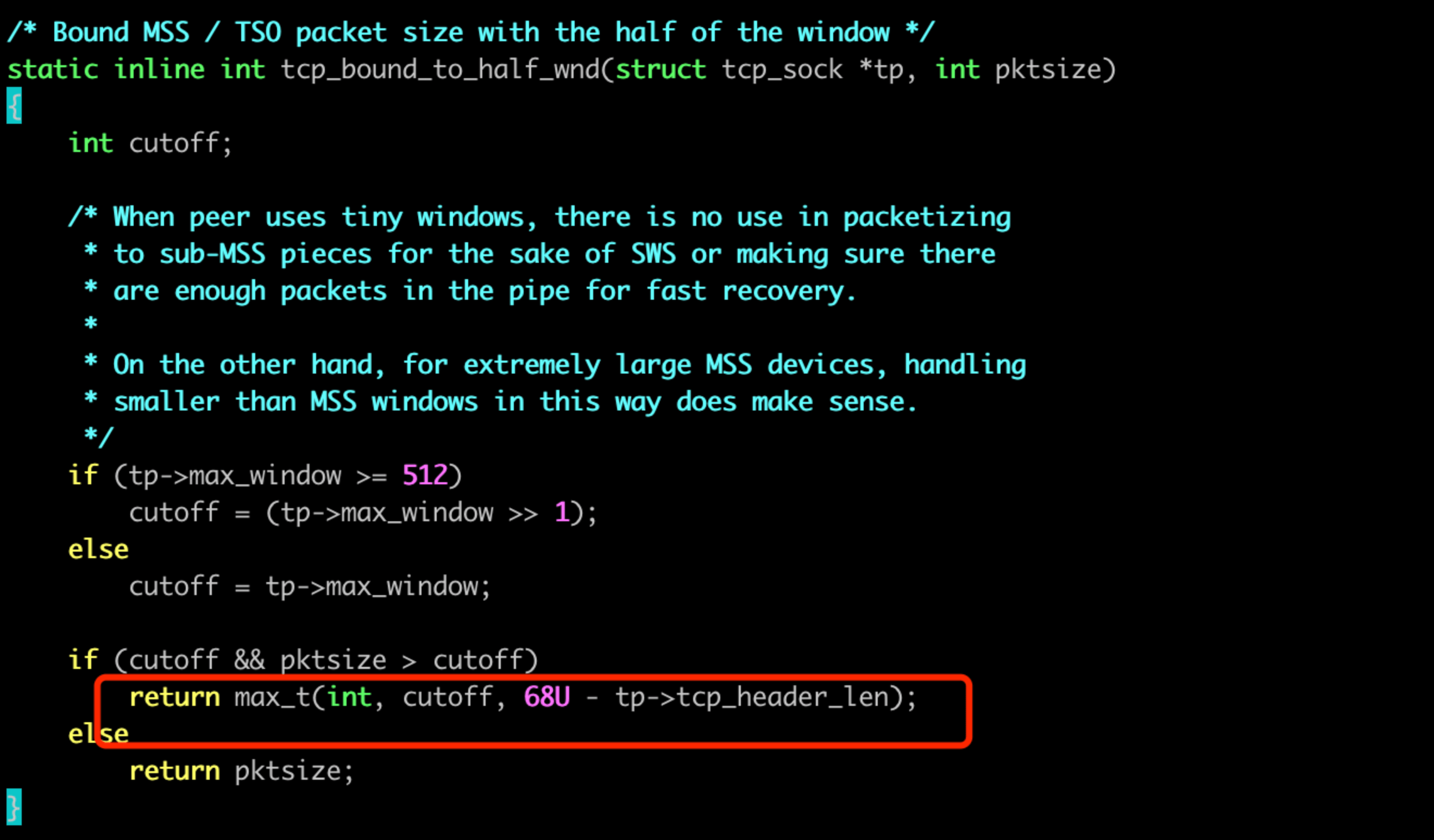
这里有个很可疑的地方。若是窗口很小,那么最后会取窗口与68字节 -tcp_header_len 的最大值,tcp_header_len 默认 20 字节的话,刚好是 48 字节。和咱们抓包看到的最小的 MSS 为 48 一致, 嫌疑很大.
那什么地方会修改最大窗口大小?
TCP 修改的地方并不多,tcp_rcv_synsent_state_process中收到 SYN 包修改(状态不符合我们当前的 case),另外主要的是在tcp_ack_update_window函数中,收 ack 之后去更新:
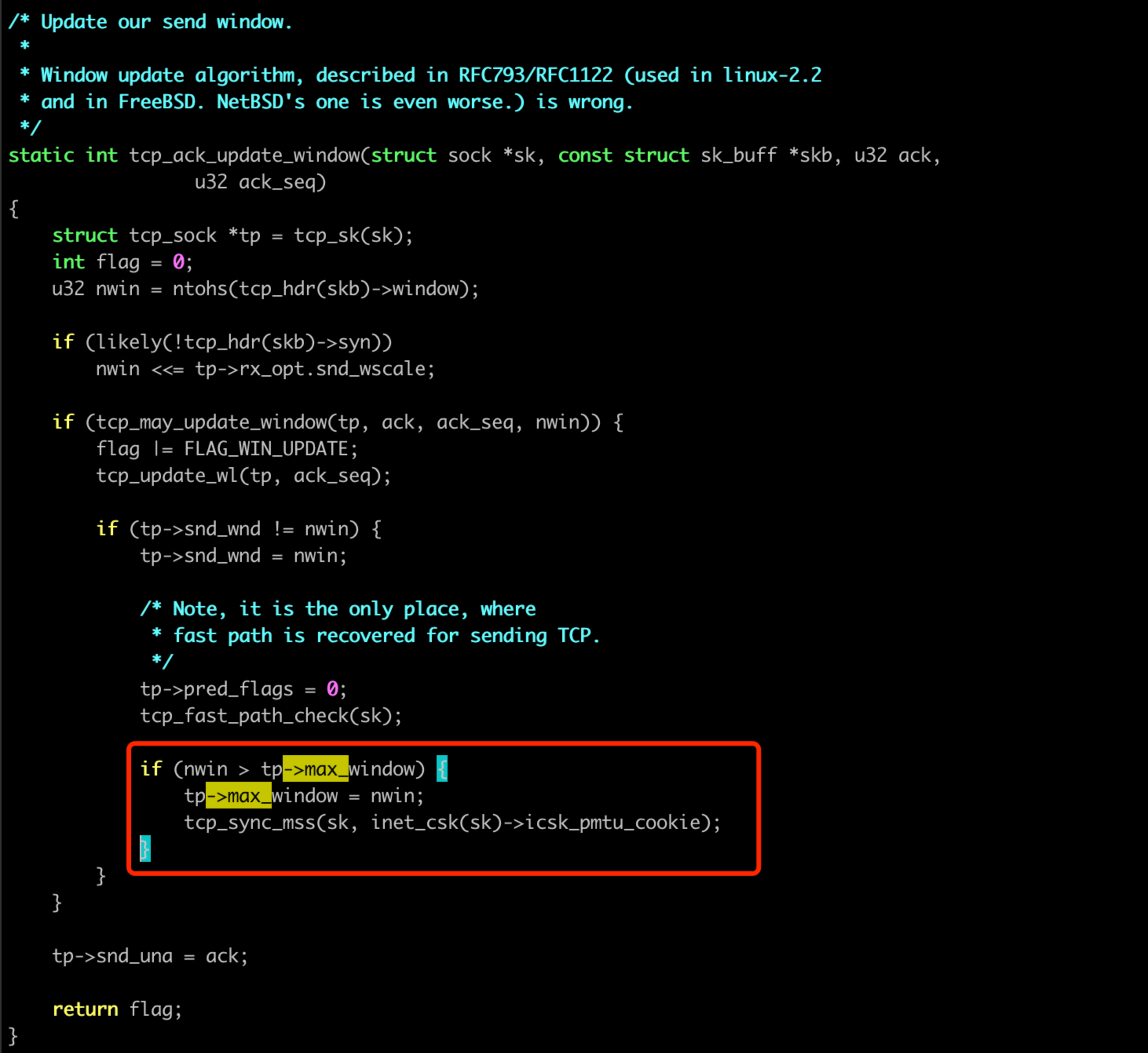
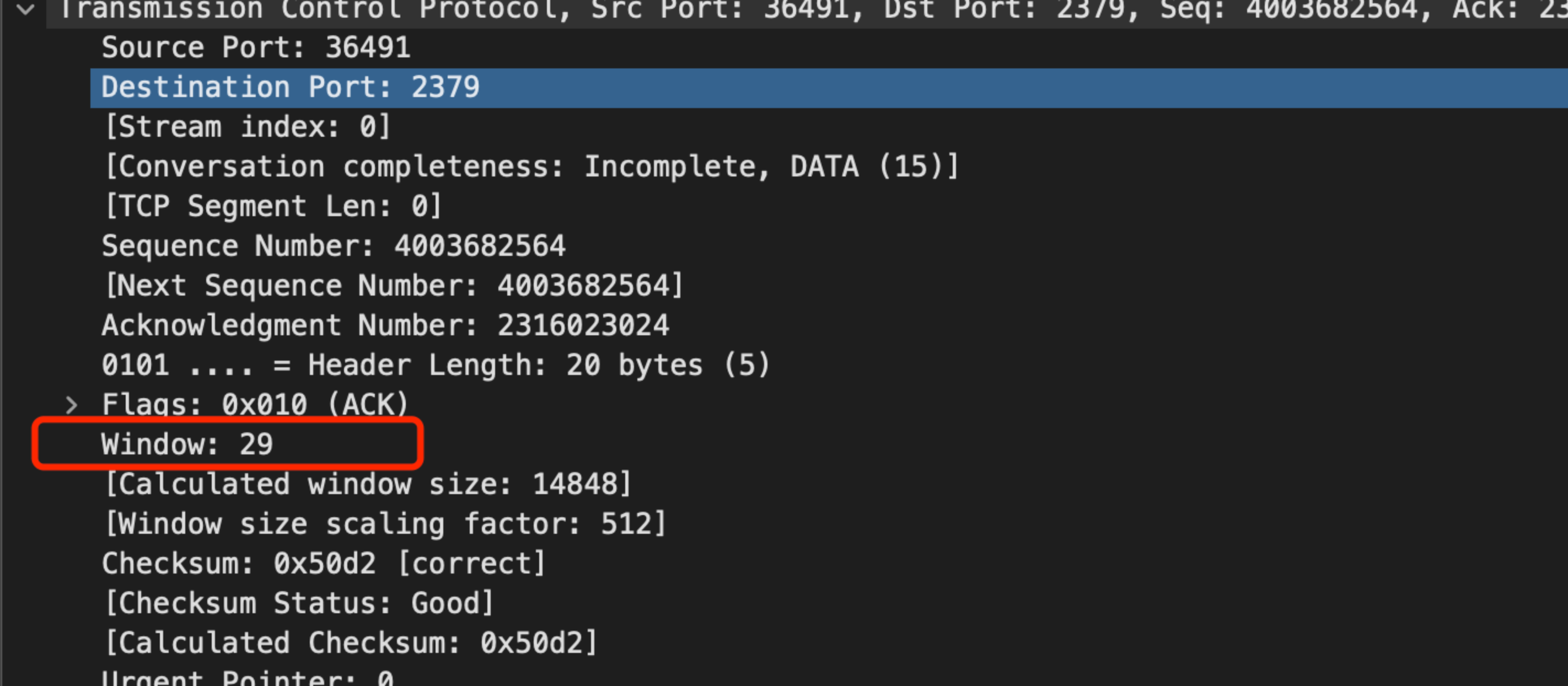
分析收到的 ack 包,我们能发现对方通告的窗口, 除了 SYN 之外,都是29字节:
SYN 包里面能看到放大因子是:
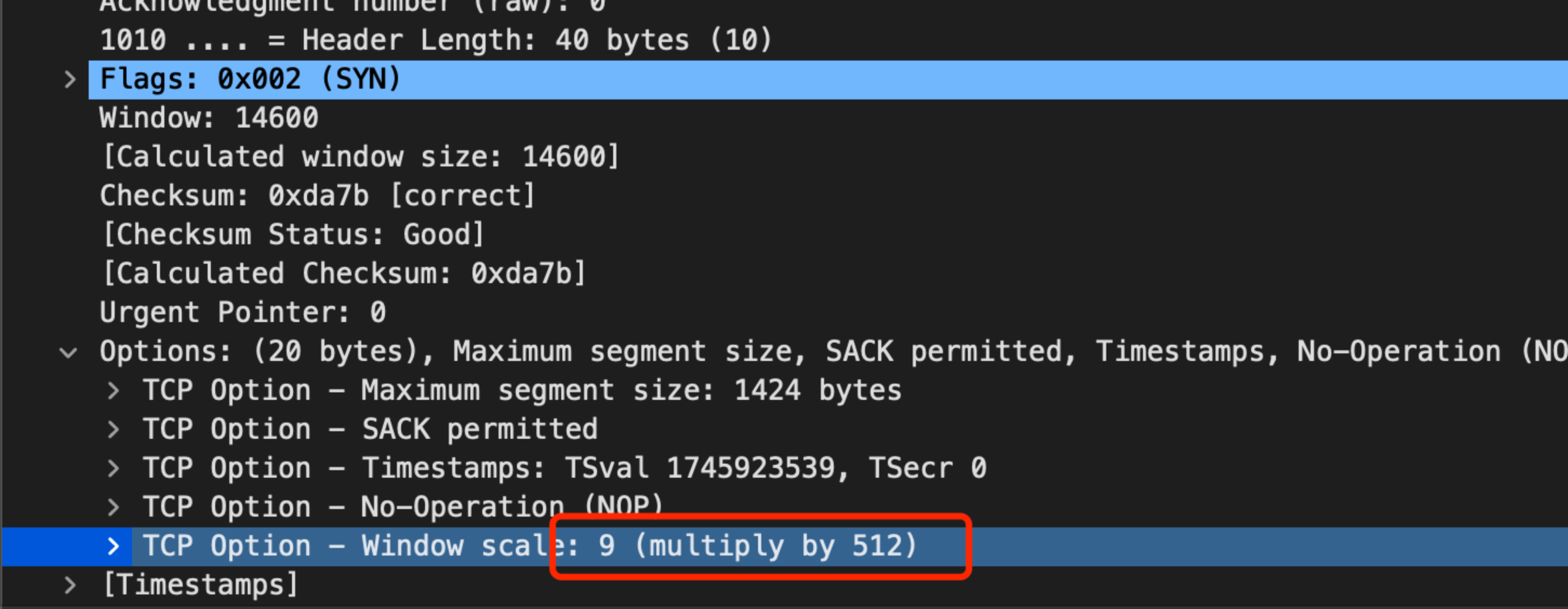
按理说,计算出来的窗口按照 。
if (likely(!tcp_hdr(skb)->syn))
nwin <<= tp->rx_opt.snd_wscale;
计算,应该是14848字节,但是从 MSS 的体现看,似乎这个 scale 丢失了。实际上,对比正常和异常的连接,发现确实 TCP 的 scale 选项在内核里面,真的丢了:

从 ss 里面对比正常和异常的连接看,不仅仅是 window scale 没了,连 timestamp, sack 选项也同时消失了!很神奇! 。
我们来看看 ss 里面获取的这些字段对应到内核的什么值:
ss 代码:

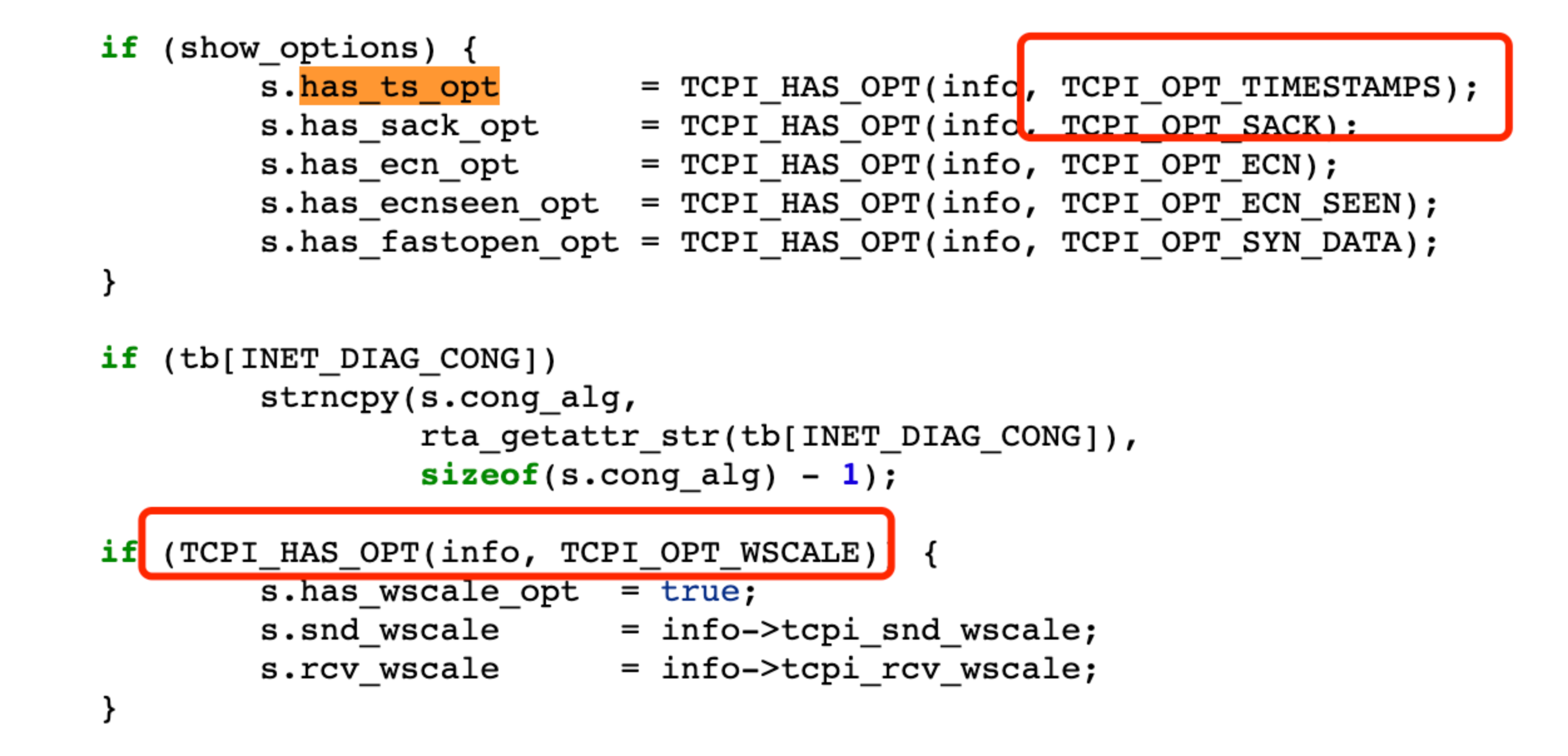
对应到内核 tcp_get_info 函数的信息:
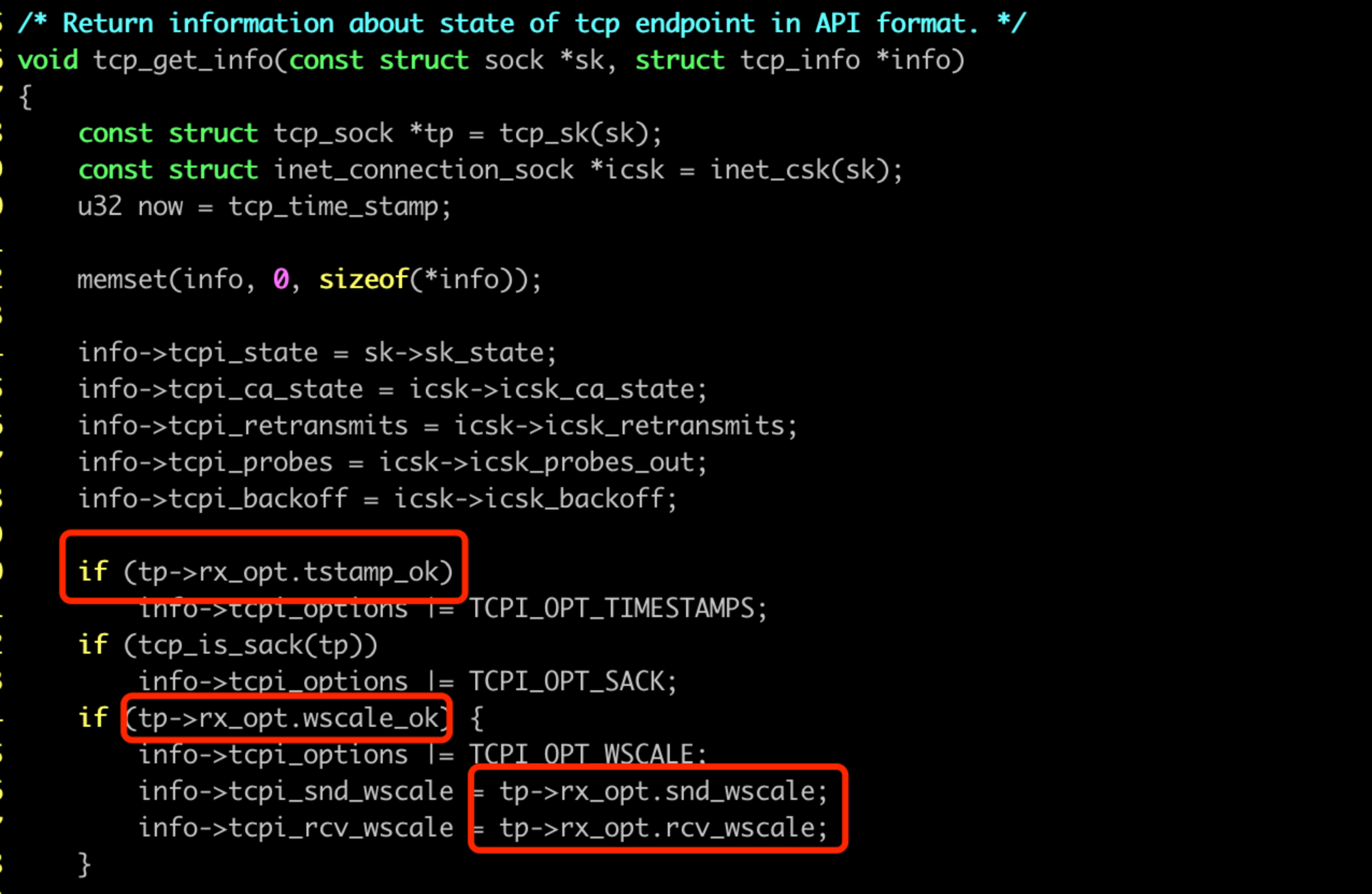
那内核什么地方会清空 window scale 选项?
搜索把 wscale_ok 改为 0 的地方,实际上并不多,我们可以比较轻易确定是 tcp_clear_options 函数干的:
static inline void tcp_clear_options(struct tcp_options_received *rx_opt)
{
rx_opt->tstamp_ok = rx_opt->sack_ok = 0;
rx_opt->wscale_ok = rx_opt->snd_wscale = 0;
}
他同时会清空 ts, sack, scale 选项, 和我们的场景再匹配不过.
搜索 tcp_clear_options 的调用方,主要在tcp_v4_conn_request和cookie_check_timestamp 两个地方,具体调用位置的逻辑都和 SYN cookie 特性有较强关联性.
if (want_cookie && !tmp_opt.saw_tstamp)
tcp_clear_options(&tmp_opt);
bool cookie_check_timestamp(struct tcp_options_received *tcp_opt,
struct net *net, bool *ecn_ok)
{
/* echoed timestamp, lowest bits contain options */
u32 options = tcp_opt->rcv_tsecr & TSMASK;
if (!tcp_opt->saw_tstamp) {
tcp_clear_options(tcp_opt);
return true;
}
两个条件都比较一致,看起来是 SYN cookie 生效的情况下,对方没有传递 timestamp 选项过来(实际上,按照 SYN cookie 的原理,发送给对端的回包中,会保存有编码进 tsval 字段低 6 位的选项信息),就会调用 tcp_clear_options, 清空窗口放大因子等选项.
从系统日志里面,我们也能观察到确实触发了 SYN cookie 逻辑:

所以,根因终于开始明确,etcd 重启,触发了大量 APIServer 瞬间到 etcd 的新建连接,短时间的大量新建连接触发了 SYN cookie 保护检查逻辑。但是因为客户端没有在后续包中将 timestamp 选项传过来,造成了窗口放大因子丢失,影响传输性能 。
客户端为什么不在每一个包都发送 timestamp,而是只在第一个 SYN 包发送?
首先,我们来看看 RFC 规范,协商了 TCP timestamp 选项后,是应该选择性的发?还是每一个都发?

答案是,后续每一个包 TCP 包都需要带上时间戳选项.
那么,我们的内核中为什么 SYN 包带了 TCP timestamp 选项,但是后续的包没有了呢?
搜索 tsval 关键词:

可以看到 tcp_syn_options 函数中,主动建连时候,会根据 sysctl_tcp_timestmps 配置选项决定是否开启时间戳选项.
查看客户端系统,该选项确实是打开的,符合预期:
net.ipv4.tcp_timestamps = 1
那为什么别的包都不带了呢?客户端角度,发了 SYN,带上时间戳选项,收到服务端 SYN+ack 以及时间戳,走到 tcp_rcv_synsent_state_process 函数中,调用 tcp_parse_options 解析 TCP 选项:
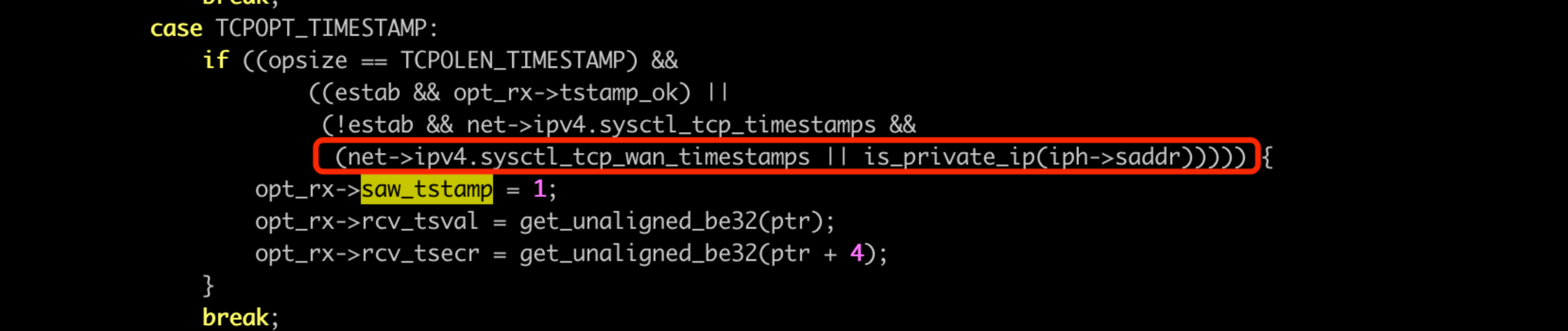
这里,就算服务端回包带了 TCP 时间戳选项,本机也要看两个 sysctl:
● sysctl_tcp_timestamps 这个比较好理解。内核标准的.
● sysctl_tcp_wan_timestamps 这个看起来是针对外网打开时间戳的选项?很诡异.
此处就会有坑了,如果 wan_timestamps 选项没打开,saw_tstamp 不会设置为1, 后续也就不会再发送 TCP 时间戳选项.
查看 wan_timestamps 设置,确实默认是关闭的:
net.ipv4.tcp_wan_timestamps = 0
所以这里真相也就明确了:因为 tcp_timestamps 选项打开,所以内核建连是会发送时间戳选项协商,同时因为 tcp_wan_timestamps 关闭,在使用非私有网段的情况下,会造成后续的包不带时间戳(云环境容器管控特殊网段的原因).
和 SYN cookie 的场景组合在一起,最终造成了 MSS 很小,性能较差的问题.
tcp_wan_timestamps 是内部的特性,是为了解决外网时间戳不正确而加的特性,TKE 团队发现该问题后已反馈给相关团队优化,当前已经优化完成.
本文问题表象,APIServer 资源请求慢,看似比较简单,实则在通过 APIServer Metrics 指标、etcd Metrics 指标、APIServer 和 etcd Trace 日志、审计日志、APIServer 和 etcd 源码深入分析后,排除了各种可疑原因,最后发现是一个非常底层的网络问题.
面对底层网络问题,在找到稳定复现的方法后,我们通过抓包神器 tcpdump,丰富强大的网络工具 iproute2 包(iproute2 包中的 ss 命令,能够获取 TCP 的很多底层信息,比如 rtt,窗口因子,重传次数等,对诊断问题很有帮助),再结合TCP RFC、linux 源码(代码面前无秘密,不管是用户态工具还是内核态),多团队的协作,成功破案.
通过此案例,更让我们深刻体会到,永远要对现网生产环境保持敬畏之心,任何操作都可能会引发不可预知的风险,监控系统不仅要检测变更服务核心指标,更要对主调方的核心指标进行深入检测.
参与本文问题定位的还有腾讯云网络专家赵奇园、内核专家杨玉玺.
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!! 。
最后此篇关于深度复盘-重启etcd引发的异常的文章就讲到这里了,如果你想了解更多关于深度复盘-重启etcd引发的异常的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
28
4
 0
0
我正在使用python 2.7 当我尝试在其上运行epsilon操作时出现此错误, 这是我的代码 import cv2 import numpy as np img = cv2.imread('img
1 很多程序员对互联网行业中广泛讨论的“35岁危机”表示不满,似乎所有的程序员都有着35岁的职业保质期。然而,随着AI技术的兴起,这场翻天覆地的技术革命正以更加残酷且直接的方式渗透到各行各业。程序员
我有一个包含多个子模块的项目,我想列出每个子模块的相对深度 该项目: main_project submodule1 submodule1\submodule1_1 submo
我有一张彩色图像及其深度图,它们都是由 Kinect 捕获的。我想将它投影到另一个位置(以查看它在另一个视角下的样子)。由于我没有 Kinect 的内在参数(相机参数);我该如何实现? P.S:我正在
给出了这三个网址: 1) https://example.com 2) https://example.com/app 3) https://example.com/app?param=hello 假
这个着色器(最后的代码)使用 raymarching 来渲染程序几何: 但是,在图像(上图)中,背景中的立方体应该部分遮挡粉红色实体;不是因为这个: struct fragmentOutput {
我希望能够在 ThreeJS 中创建一个房间。这是我到目前为止所拥有的: http://jsfiddle.net/7oyq4yqz/ var camera, scene, renderer, geom
我正在尝试通过编写小程序来学习 Haskell...所以我目前正在为简单表达式编写一个词法分析器/解析器。 (是的,我可以使用 Alex/Happy...但我想先学习核心语言)。 我的解析器本质上是一
我想使用像 [parse_ini_file][1] 这样的东西。 例如,我有一个 boot.ini 文件,我将加载该文件以进行进一步的处理: ;database connection sett
我正在使用 Mockito 来测试我的类(class)。我正在尝试使用深度 stub ,因为我没有办法在 Mockito 中的另一个模拟对象中注入(inject) Mock。 class MyServ
我试图在调整设备屏幕大小时重新排列布局,所以我这样做: if(screenOrientation == SCREEN_ORIENTATION_LANDSCAPE) { document
我正在 Ubuntu 上编写一个简单的 OpenGL 程序,它使用顶点数组绘制两个正方形(一个在另一个前面)。由于某种原因,GL_DEPTH_TEST 似乎不起作用。后面的物体出现在前面的物体前面
static FAST_FUNC int fileAction(const char *pathname, struct stat *sb UNUSED_PARAM, void *mo
我有这样的层次结构: namespace MyService{ class IBase { public: virtual ~IBase(){} protected: IPointer
我正在制作一个图片库,需要一些循环类别方面的帮助。下一个深度是图库配置文件中的已知设置,因此这不是关于无限深度循环的问题,而是循环已知深度并输出所有结果的最有效方法。 本质上,我想创建一个 包含系统中
如何以编程方式在树状结构上获取 n 深度迭代器?在根目录中我有 List 每个节点有 Map> n+1 深度。 我已修复 1 个深度: // DEPTH 1 nodeData.forEach(base
我正在构建一个包含大量自定义元素的 Polymer 单页界面。 现在我希望我的元素具有某种主样式,我可以在 index.html 或我的主要内容元素中定义它。可以这样想: index.html
我正在尝试每 25 秒连接到配对的蓝牙设备,通过 AlarmManager 安排,它会触发 WakefulBroadcastReceiver 以启动服务以进行连接。设备进入休眠状态后,前几个小时一切正
假设有一个有默认值的函数: int foo(int x=42); 如果这被其他人这样调用: int bar(int x=42) { return foo(x); } int moo(int x=42)
是否可以使用 Javascript 获取 url 深度(级别)? 如果我有这个网址:www.website.com/site/product/category/item -> depth=4www.w

我是一名优秀的程序员,十分优秀!