
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 27
27
 4
4


论文内容: Amazon Aurora: Design Considerations for HighThroughput Cloud-Native Relational Databases 。
里面介绍了一种云原生的关系型数据库 Aurora 的体系结构,以及导致该体系结构的设计考虑因素。我觉得和普通的传统 mysql 的数据库架构模型,最显著的不同是将 redo processing(重做处理)推到一个多租户向外扩展的存储服务,这是为Aurora专门构建的。文中描述这样做如何不仅减少网络流量,而且还允许快速崩溃恢复,在不丢失数据的情况下故障转移到副本,以及容错、自修复存储.
首先我们先从简单的传统数据库如何一步一步的演变到 Aurora 的架构的.
。
1、EBS的由来和Aurora的背景历史 。
在云服务中,其实服务器最早的时候就是一个操作系统再挂载一个模拟的硬盘 disk volum。类似于这样下面的结构,这样做是避免了单机的故障,因为如果硬盘是直接在云服务器上的,如果此机器故障,那么直接全部数据不可用,并且就算有数据备份机制,在故障和恢复期间也会导致缺失一段时间的数据.
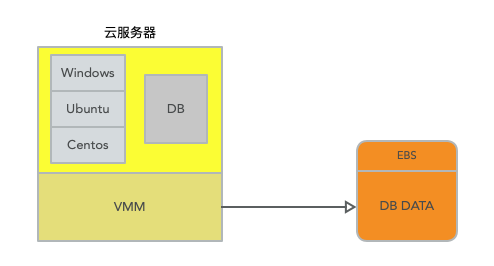
在云服务中挂载一个硬盘,并且同时也是容错的且支持持久化存储的服务,这个服务就是EBS。EBS全称是Elastic Block Store。从云服务器实例来看,EBS就是一个硬盘,你可以像一个普通的硬盘一样去格式化它,就像一个类似于ext3格式的文件系统或者任何其他你喜欢的Linux文件系统。但是在实现上,EBS底层是一对互为副本的存储服务器。随着EBS的推出,你可以租用一个EBS volume。一个EBS volume看起来就像是一个普通的硬盘一样,但却是由一对互为副本EBS服务器实现,每个EBS服务器本地有一个硬盘。所以,现在你运行了一个数据库,相应的EC2实例将一个EBS volume挂载成自己的硬盘。当数据库执行写磁盘操作时,数据会通过网络送到EBS服务器.
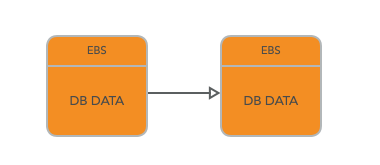
但是明显的,单单一块 EBS 是不足以提供令人满意的数据一致性,和故障恢复容错,所以在 EBS 中都是使用 chain Replication(链式复制)来保证一致性的,具体的可以看上一期的关于 zookeeper 的文章,里面有详细的描述.
。
。
这两个EBS服务器会使用Chain Replication 进行复制。所以写请求首先会写到第一个EBS服务器,之后写到第二个EBS服务器,然后从第二个EBS服务器,EC2实例可以得到回复。当读数据的时候,因为这是一个Chain Replication,EC2实例会从第二个EBS服务器读取数据.

。
。
所以现在,运行在EC2实例上的数据库有了可用性。因为现在有了一个存储系统可以在服务器宕机之后,仍然能持有数据。如果数据库所在的服务器挂了,你可以启动另一个EC2实例,并为其挂载同一个EBS volume,再启动数据库。新的数据库可以看到所有前一个数据库留下来的数据,就像你把硬盘从一个机器拔下来,再插入到另一个机器一样。所以EBS非常适合需要长期保存数据的场景,比如说数据库。 。
尽管 EBS 做到了上层DB操作和数据底层的结构,用论文中的描述来说就是,尽管每个实例仍然包含传统内核的大部分组件(查询处理器、事务、锁定、缓冲区缓存、访问方法和撤销管理),但一些功能(重做日志、持久存储、崩溃恢复和备份/恢复)被卸载到存储服务中,为这改进提供了基础.
那么,问题来了,这样的架构有什么问题吗?它仍然有自己所存在的问题的.
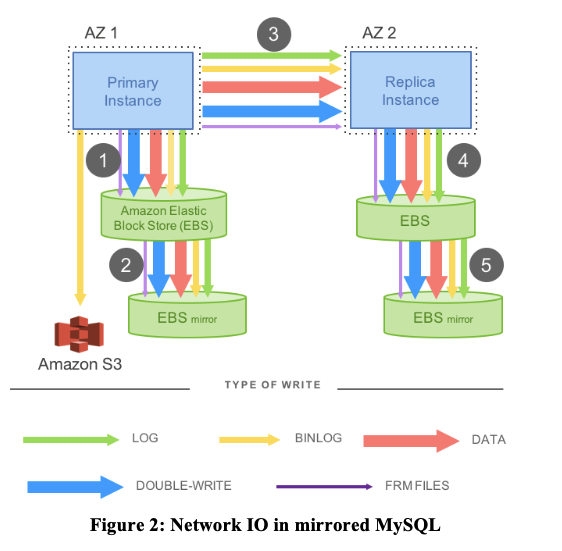
因为 chain replication 的结构导致了如果不放在同一个 AZ 分区中,那么性能会非常低,响应跨区了必定会请求时间增加。放在同一个 AZ 中,又会导致如果一个机房出现灾害,数据库的容错几乎为零。在此基础上对存储结构进行了改进,如下.
。
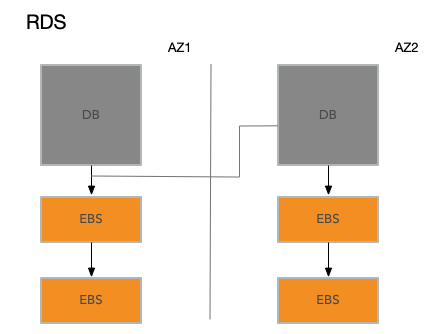
数据库中事务的一致性保证是通过 log 来进行保存的,也就是说即使 EBS 的存储系统出现了落盘故障,那么 DB 也能通过 log 的重做机制来恢复故障前的事务,并且决定是否提交或撤销,这叫做故障可恢复事务(Crash Recoverable Transaction)。所以在 mysql 基础上,结合Amazon自己的基础设施,Amazon为其云用户开发了改进版的数据库,叫做RDS(Relational Database Service)。尽管论文不怎么讨论RDS,但是论文中的图2基本上是对RDS的描述。RDS是第一次尝试将数据库在多个AZ之间做复制,这样就算整个数据中心挂了,你还是可以从另一个AZ重新获得数据而不丢失任何写操作。 对于RDS来说,有且仅有一个EC2实例作为数据库。这个数据库将它的data page和WAL Log存储在EBS,而不是对应服务器的本地硬盘。当数据库执行了写Log或者写page操作时,这些写请求实际上通过网络发送到了EBS服务器。所有这些服务器都在一个AZ中.
每一次数据库软件执行一个写操作,Amazon会自动的,对数据库无感知的,将写操作拷贝发送到另一个数据中心的AZ中。从论文的图2来看,可以发现这是另一个EC2实例,它的工作就是执行与主数据库相同的操作。所以,AZ2的副数据库会将这些写操作拷贝AZ2对应的EBS服务器.
。
在RDS的架构中,也就是上图中,每一次写操作,例如数据库追加日志或者写磁盘的page,数据除了发送给AZ1的两个EBS副本之外,还需要通过网络发送到位于AZ2的副数据库。副数据库接下来会将数据再发送给AZ2的两个独立的EBS副本。之后,AZ2的副数据库会将写入成功的回复返回给AZ1的主数据库,主数据库看到这个回复之后,才会认为写操作完成了。 RDS这种架构提供了更好的容错性。因为现在在一个其他的AZ中,有了数据库的一份完整的实时的拷贝。这个拷贝可以看到所有最新的写请求。即使AZ1发生火灾都烧掉了,你可以在AZ2的一个新的实例中继续运行数据库,而不丢失任何数据 。
。
2、将 redo log 放在存储层完成 。
在论文中,上面描述的主备 MySQL 模型是不可取的,不仅因为数据是如何写入的,还因为数据写入的内容。首先,在图一的步骤1、3和5是顺序的和同步的,但是从库的数据延迟是必然的,因为许多写操作是顺序的。如果出现网络抖动,那么主备的数据延迟会被放大,因为即使是在异步写操作中,也必须等待最慢的操作,使系统受制于 MySQL 用于主从同步中的网络IO。从分布式系统的角度来看,上面的架构模型需要四个 EBS 都确认写仲裁commit之后数据才得以保证,这样容易受到失败和异常值性能的影响。其次,OLTP应用程序的用户操作会导致许多不同类型的写操作,这些写操作通常以多种方式表示相同的信息——例如,为了防止存储基础设施中的分页撕裂,会对双写缓冲区进行写操作。如果是单单的日志同步,不同单机没有办法保证是可以共享内存的,那么双写缓冲区进行写操作类似的操作可能会导致数据短暂的不一致,虽然通过日志可以保证数据最终一致性.
所以 Aurora 提出的解决方案就是 Offloading Redo Processing to Storage,将 redo log 交给存储层进行同步.
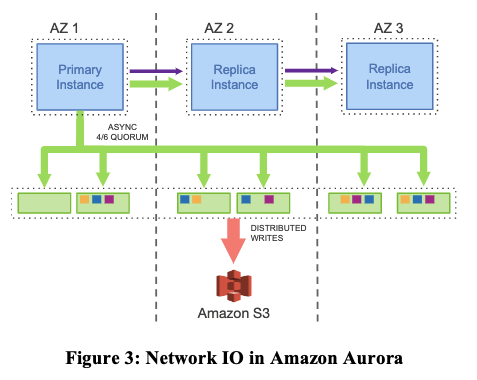
。
相比于上面的图1,这里简化了在云服务实例中生成 data page 也就是数据页生成所需要的 Double-write 和 FRM files,只有 redo log 的存储,不用考虑在每一层 EBS 中都通过网络io去同步除 log 之外的数据。没有页面从数据库层写入,没有用于后台写入,没有用于检查点,也没有用于缓存取出.
从之前的简单数据库模型可以看出,每一条Log条目只有几十个字节那么多,也就是存一下旧的数值,新的数值,所以Log条目非常小。然而,当一个数据库要写本地磁盘时,它更新的是data page,这里的数据是巨大的,虽然在论文里没有说,但是我认为至少是8k字节那么多。所以,对于每一次事务,需要通过网络发送多个8k字节的page数据。而Aurora只是向更多的副本发送了少量的Log条目。因为Log条目的大小比8K字节小得多,所以在网络性能上这里就胜出了。这是Aurora的第一个特点,只发送Log条目(包括 binglog 和 redolog).
EBS是一个非常通用的存储系统,它模拟了磁盘,只需要支持读写数据块。EBS不理解除了数据块以外的其他任何事物。而这里的存储系统理解使用它的数据库的Log。所以这里,Aurora将通用的存储去掉了,取而代之的是一个应用定制的(Application-Specific)存储系统.
另一件重要的事情是,Aurora并不需要6个副本都确认了写入才能继续执行操作。相应的,只要Quorum形成了,也就是任意4个副本确认写入了,数据库就可以继续执行操作。所以,当我们想要执行写入操作时,如果有一个AZ下线了,或者AZ的网络连接太慢了,或者只是服务器响应太慢了,Aurora可以忽略最慢的两个服务器,或者已经挂掉的两个服务器,它只需要6个服务器中的任意4个确认写入,就可以继续执行。所以这里的Quorum是Aurora使用的另一个聪明的方法。通过这种方法,Aurora可以有更多的副本,更多的AZ,但是又不用付出大的性能代价,因为它永远也不用等待所有的副本,只需要等待6个服务器中最快的4个服务器即可.
Quorum系统要求,任意你要发送写请求的W个服务器,必须与任意接收读请求的R个服务器有重叠。这意味着,R加上W必须大于N( 至少满足R + W = N + 1 ),这样任意W个服务器至少与任意R个服务器有一个重合.
假设有三台服务器,并且每个服务器只保存一个对象:
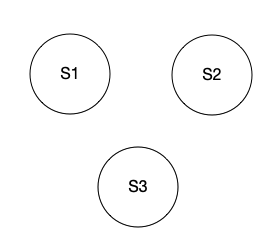
。
我们发送了一个写请求,想将我们的对象设置成23。为了能够执行写请求,我们需要至少将写请求发送到W个服务器。我们假设在这个系统中,R和W都是2,N是3。为了执行一个写请求,我们需要将新的数值23发送到至少2个服务器上。所以,或许我们的写请求发送到了S1和S3。所以,它们现在知道了我们对象的数值是23.

。
如果某人发起读请求,读请求会至少检查R个服务器。在这个配置中,R也是2。这里的R个服务器可能包含了并没有看到之前写请求的服务器(S2),但同时也至少还需要一个其他服务器来凑齐2个服务器。这意味着,任何读请求都至少会包含一个看到了之前写请求的服务器.
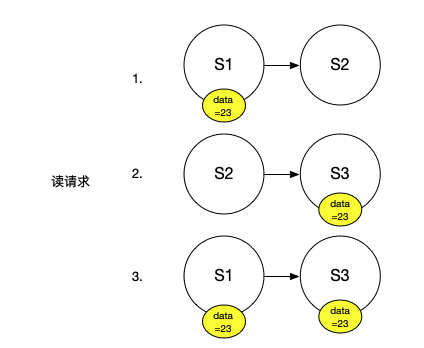
。
这是Quorum系统的要求,Read Quorum必须至少与Write Quorum有一个服务器是重合的。所以任何读请求可以从至少一个看见了之前写请求的服务器得到回复.
这里还有一个关键的点,客户端读请求可能会得到R个不同的结果,现在的问题是,客户端如何知道从R个服务器得到的R个结果中,哪一个是正确的呢?通过不同结果出现的次数来投票(Vote)在这是不起作用的,因为我们只能确保Read Quorum必须至少与Write Quorum有一个服务器是重合的,这意味着客户端向R个服务器发送读请求,可能只有一个服务器返回了正确的结果。对于一个有6个副本的系统,可能Read Quorum是4,那么你可能得到了4个回复,但是只有一个与之前写请求重合的服务器能将正确的结果返回,所以这里不能使用投票。在Quorum系统中使用的是版本号(Version)。所以,每一次执行写请求,你需要将新的数值与一个增加的版本号绑定。之后,客户端发送读请求,从Read Quorum得到了一些回复,客户端可以直接使用其中的最高版本号的数值.
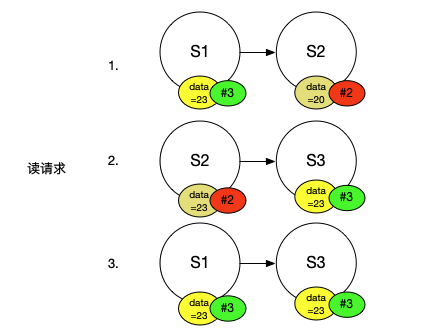
。
假设刚刚的例子中,S2有一个旧的数值20。每一个服务器都有一个版本号,S1和S3是版本3,因为它们看到了相同的写请求,所以它们的版本号是相同的。同时我们假设没有看到前一个写请求的S2的版本号是2。之后客户端从S2和S3读取数据,得到了两个不同结果,它们有着不同的版本号,客户端会挑选版本号最高的结果.
相比Chain Replication,这里的优势是可以轻易的剔除暂时故障、失联或者慢的服务器。实际上,这里是这样工作的,当你执行写请求时,你会将新的数值和对应的版本号给所有N个服务器,但是只会等待W个服务器确认。类似的,对于读请求,你可以将读请求发送给所有的服务器,但是只等待R个服务器返回结果。因为你只需要等待R个服务器,这意味着在最快的R个服务器返回了之后,你就可以不用再等待慢服务器或者故障服务器超时.
除此之外,Quorum系统可以调整读写的性能。通过调整Read Quorum和Write Quorum,可以使得系统更好的支持读请求或者写请求。对于前面的例子,我们可以假设Write Quorum是3,每一个写请求必须被所有的3个服务器所确认。这样的话,Read Quorum可以只是1。所以,如果你想要提升读请求的性能,在一个3个服务器的Quorum系统中,你可以设置R为1,W为3,这样读请求会快得多,因为它只需要等待一个服务器的结果,但是代价是写请求执行的比较慢。如果你想要提升写请求的性能,可以设置R为3,W为1,这意味着可能只有1个服务器有最新的数值,但是因为客户端会咨询3个服务器,3个服务器其中一个肯定包含了最新的数值.
当R为1,W为3时,写请求就不再是容错的了,同样,当R为3,W为1时,读请求不再是容错的,因为对于读请求,所有的服务器都必须在线才能执行成功。所以在实际场景中,你不会想要这么配置,你或许会与Aurora一样,使用更多的服务器,将N变大,然后再权衡Read Quorum和Write Quorum.
在 Aurora 的 Quorum 系统中,N=6,W=4,R=3。W等于4意味着,当一个AZ彻底下线时,剩下2个AZ中的4个服务器仍然能完成写请求。R等于3意味着,当一个AZ和一个其他AZ的服务器下线时,剩下的3个服务器仍然可以完成读请求。当3个服务器下线了,系统仍然支持读请求,仍然可以返回当前的状态,但是却不能支持写请求。所以,当3个服务器挂了,现在的Quorum系统有足够的服务器支持读请求,并据此重建更多的副本,但是在新的副本创建出来替代旧的副本之前,系统不能支持写请求。同时,Quorum系统可以剔除暂时的慢副本.

。
在论文中说明了这样做带来的提升,相对于传统 mysql 镜像,事务执行提高了了35倍。得到这样的提升,文中解释有几点:
。
3、Aurora 的读写存储器 。
Aurora中的写请求并不是像一个经典的Quorum系统一样直接更新数据。对于Aurora来说,它的写请求从来不会覆盖任何数据,它的写请求只会在当前Log中追加条目( Append Entries )。所以,Aurora使用Quorum只是在数据库执行事务并发出新的Log记录时,确保Log记录至少出现在4个存储服务器上,之后才能提交事务。所以,Aurora 的Write Quorum的实际意义是,每个新的Log记录必须至少追加在4个存储服务器中,之后才可以认为写请求完成了。当Aurora执行到事务的结束,并且在回复给客户端说事务已经提交之前,Aurora必须等待Write Quorum的确认,也就是4个存储服务器的确认,组成事务的每一条Log都成功写入了.
这里的存储服务器接收Log条目,这是它们看到的写请求。它们并没有从数据库服务器获得到新的data page,它们得到的只是用来描述data page更新的Log条目.
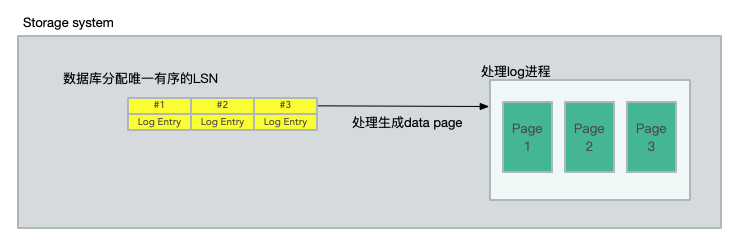
每个事务生成自己的重做日志记录。数据库为每条日志记录分配一个唯一的有序LSN,但有一个约束,即LSN分配的值不能大于当前 VDL 和一个称为LSN分配限制(LAL)的常量(当前设置为1000万)的总和。这个限制可以确保数据库不会比存储系统超前太多,并在存储或网络无法跟上的情况下,抑制传入的写操作.

。
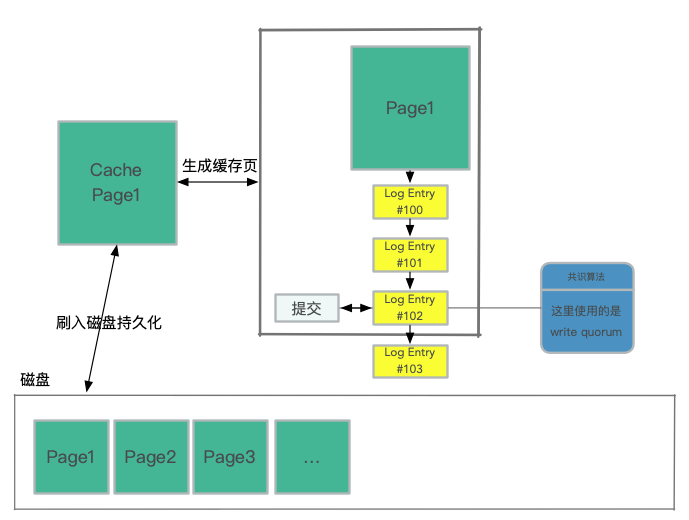
在内部实际上也是类似于脏写,当一个 log 的 LSN 进行共识算法存储在大多数节点上后,就可以将此日志应用到 page cache 上了。 这个日志点称之为 Consistency Point LSNs.(CPL) 。
。
这里的刷入磁盘持久化是异步执行的,cache page 就是最新建立的 page,所有添加的日志条目都会找到对应的 page 来生成对应的最新的 page,哪怕是当系统持久化page之前存储系统 crash 了,它也能依据 log 来自动恢复 page。这里称存储系统中持久化的最大的 LSN 为 Volume Durable LSN(VDL), 在图中就是 #102 .
在提交 commit 时,事务提交是异步完成。当客户端提交事务时,处理提交请求的线程通过将其“commit LSN”记录为等待提交的单独事务列表的一部分,从而将事务放到一边,然后继续执行其他工作。与WAL协议等价的协议基于完成提交,当且仅当最新的VDL大于或等于事务的提交LSN。随着VDL的增加,数据库会识别等待提交的符合条件的事务,并使用专用线程向等待的客户端发送提交确认。工作线程不会暂停提交,它们只是拉出其他挂起的请求并继续处理.
。
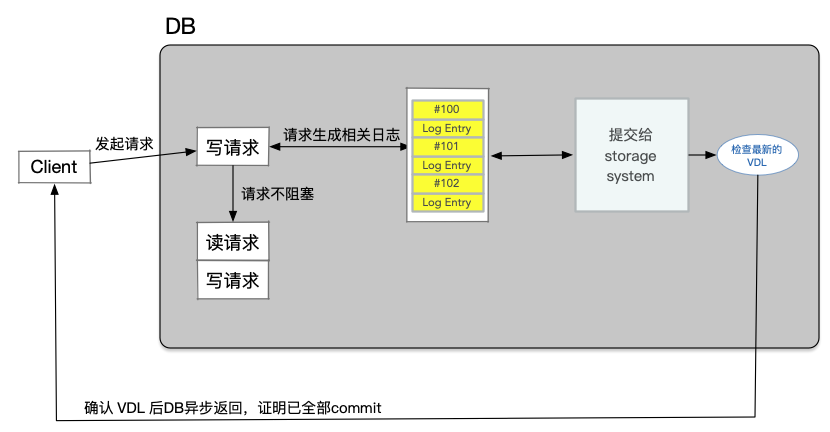
在数据库服务器写入的是Log条目,但是读取的是page。这也是与Quorum系统不一样的地方。Quorum系统通常读写的数据都是相同的。除此之外,在一个普通的操作中,数据库服务器可以避免触发Quorum Read。数据库服务器会记录每一个存储服务器接收了多少Log。所以,首先,Log条目都有类似12345这样的编号,当数据库服务器发送一条新的Log条目给所有的存储服务器,存储服务器接收到它们会返回说,我收到了第79号和之前所有的Log。数据库服务器会记录这里的数字,或者说记录每个存储服务器收到的最高连续的Log条目号。这样的话,当一个数据库服务器需要执行读操作,它只会挑选拥有最新Log的存储服务器,然后只向那个服务器发送读取page的请求。所以,数据库服务器执行了Quorum Write,但是却没有执行Quorum Read。因为它知道哪些存储服务器有最新的数据,然后可以直接从其中一个读取数据。这样的代价小得多,因为这里只读了一个副本,而不用读取Quorum数量的副本.

。
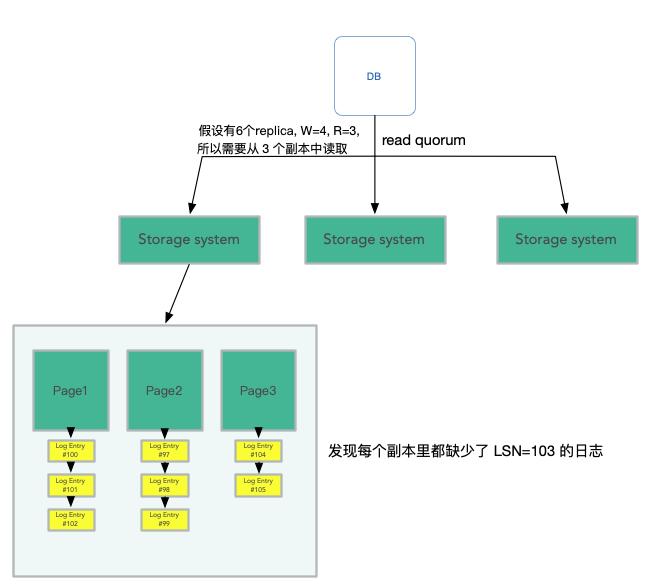
假设数据库服务器运行在某个EC2实例,如果相应的硬件故障了,数据库服务器也会随之崩溃。在Amazon的基础设施有一些监控系统可以检测到Aurora数据库服务器崩溃,之后Amazon会自动的启动一个EC2实例,在这个实例上启动数据库软件,并告诉新启动的数据库:你的数据存放在那6个存储服务器中,请清除存储在这些副本中的任何未完成的事务,之后再继续工作。这时,Aurora会使用Quorum的逻辑来执行读请求。因为之前数据库服务器故障的时候,它极有可能处于执行某些事务的中间过程。所以当它故障了,它的状态极有可能是它完成并提交了一些事务,并且相应的Log条目存放于Quorum系统。同时,它还在执行某些其他事务的过程中,这些事务也有一部分Log条目存放在Quorum系统中,但是因为数据库服务器在执行这些事务的过程中崩溃了,这些事务永远也不可能完成。对于这些未完成的事务,我们可能会有这样一种场景,第一个副本有第101个Log条目,第二个副本有第102个Log条目,第三个副本有第104个Log条目,但是没有一个副本持有第103个Log条目。 。
。
所以故障之后,新的数据库服务器需要恢复,它会执行Quorum Read,找到第一个缺失的Log序号,所以会找到 LSN=103 的日志缺失了。 。
这时,数据库服务器会给所有的存储服务器发送消息说:请丢弃103及之后的所有Log条目。103及之后的Log条目必然不会包含已提交的事务,因为我们知道只有当一个事务的所有Log条目存在于Write Quorum时,这个事务才会被commit,所以对于已经commit的事务我们肯定可以看到相应的Log。这里我们只会丢弃未commit事务对应的Log条目.
。
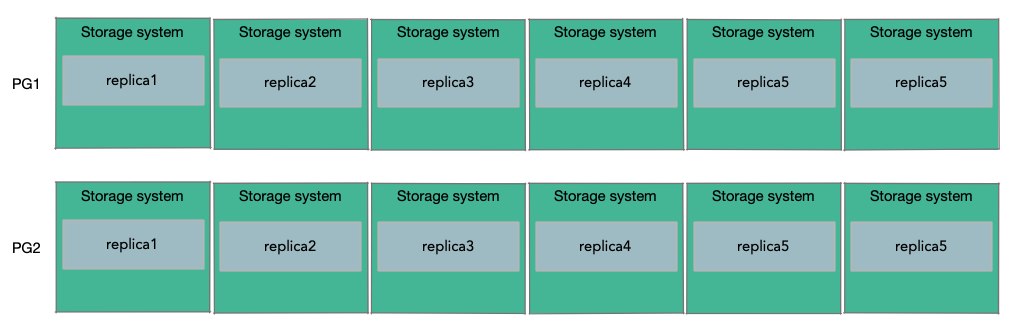
3、数据分片(Protection Group) 。
为了能支持超过10TB数据的大型数据库。Amazon的做法是将数据库的数据,分割存储到多组存储服务器上,假设每一组都是6个副本,分割出来的每一份数据是10GB。所以,如果一个数据库需要20GB的数据,那么这个数据库会使用2个PG(Protection Group),其中一半的10GB数据在一个PG中,包含了6个存储服务器作为副本,另一半的10GB数据存储在另一个PG中,这个PG可能包含了不同的6个存储服务器作为副本.
。
Sharding之后,Log该如何处理就不是那么直观了。如果有多个Protection Group,该如何分割Log呢?答案是,当Aurora需要发送一个Log条目时,它会查看Log所修改的数据,并找到存储了这个数据的Protection Group,并把Log条目只发送给这个Protection Group对应的6个存储服务器。这意味着,每个Protection Group只存储了部分data page和所有与这些data page关联的Log条目。所以每个Protection Group存储了所有data page的一个子集,以及这些data page相关的Log条目.
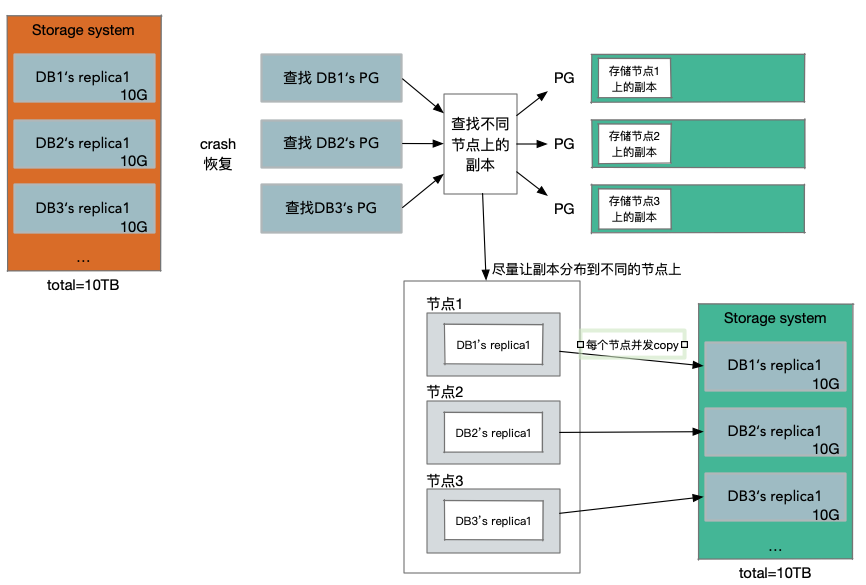
如果其中一个存储服务器挂了,我们期望尽可能快的用一个新的副本替代它。因为如果4个副本挂了,我们将不再拥有Read Quorum,我们也因此不能创建一个新的副本。所以我们想要在一个副本挂了以后,尽可能快的生成一个新的副本。表面上看,每个存储服务器存放了某个数据库的某个某个Protection Group对应的10GB数据,但实际上每个存储服务器可能有1-2块几TB的磁盘,上面存储了属于数百个Aurora实例的10GB数据块。所以在存储服务器上,可能总共会有10TB的数据,当它故障时,它带走的不仅是一个数据库的10GB数据,同时也带走了其他数百个数据库的10GB数据。所以生成的新副本,不是仅仅要恢复一个数据库的10GB数据,而是要恢复存储在原来服务器上的整个10TB的数据.

。
当节点副本挂了的情况,这里应该避免的是通过一个存储服务节点,去拷贝所有的数据到新的副本节点上.
对于所有的Protection Group对应的数据块,都会有类似的副本。这种模式下,如果一个存储服务器挂了,假设上面有100个数据块,现在的替换策略是:找到100个不同的存储服务器,其中的每一个会被分配一个数据块,也就是说这100个存储服务器,每一个都会加入到一个新的Protection Group中。所以相当于,每一个存储服务器只需要负责恢复10GB的数据。所以在创建新副本的时候,我们有了100个存储服务器.
。
假设有足够多的服务器,这里的服务器大概率不会有重合,同时假设我们有足够的带宽,现在我们可以以100的并发,并行的拷贝1TB的数据,这只需要10秒左右。如果只在两个服务器之间拷贝,正常拷贝1TB数据需要1000秒左右.
这就是Aurora使用的副本恢复策略,它意味着,如果一个服务器挂了,它可以并行的,快速的在数百台服务器上恢复。如果大量的服务器挂了,可能不能正常工作,但是如果只有一个服务器挂了,Aurora可以非常快的重新生成副本.
最后此篇关于从Cloud-NativeRelationalDB看数据库设计的文章就讲到这里了,如果你想了解更多关于从Cloud-NativeRelationalDB看数据库设计的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
27
4
 0
0
我有一个 Cloud Run 服务,它通过 SQLAlchemy 访问 Cloud SQL 实例.但是,在 Cloud Run 的日志中,我看到 CloudSQL connection failed.
关闭。这个问题是opinion-based .它目前不接受答案。 想改善这个问题吗?更新问题,以便可以通过 editing this post 用事实和引文回答问题. 4年前关闭。 Improve t
在将 docker 容器镜像部署到 Cloud Run 时,我可以选择一个区域,这很好。 Cloud Run 将构建委托(delegate)给 Cloud Build,后者显然会创建两个存储桶来实现这
我正在尝试将 Cloud Functions 用作由 PubSub 触发的异步后台工作程序,并进行更长时间的工作(以分钟为单位)。完整代码在这里https://github.com/zdenulo/c
这是/etc/cloud/cloud.cfg的内容Ubuntu云16.04镜像: # The top level settings are used as module # and system co
如何从 Google Cloud Function 启动 Cloud Dataflow 作业?我想使用 Google Cloud Functions 作为启用跨服务组合的机制。 最佳答案 我已经包含了
我想使用 Cloud Shell 在我的第二代 Cloud Sql 实例上运行数据库迁移。 我找到了一个 example in the docs关于如何使用 gcloud 进行连接.但是当我运行命令时
我正在尝试使用 Google Cloud PubSub和我的 Google Cloud Dataproc群集,我收到如下身份验证范围错误: { "code" : 403, "errors" :
这是我的用例。 我已经有一个以私有(private)模式部署的 Cloud Run 服务。 (与云功能相同的问题) 我正在开发使用此 Cloud Run 的新服务。我在应用程序中使用默认凭据进行身份验
如何连接到 Cloud SQL 上的数据库,而无需在容器中添加我的凭据文件? 最佳答案 使用 UNIX 域套接字 (Java) 从云运行(完全托管)连接到云 SQL At this time Clou
我有一个google-cloud-ml作业,需要从gs存储桶加载numpy .npz文件。我遵循了this example上关于如何从gs加载.npy文件的操作,但是由于.npz文件已压缩,因此它对我
我想创建链接到另一个项目中的 Cloud Source Repository 的 Cloud Build 触发器。但是当我在应该选择存储库的步骤中时,列表是空的。我尝试了不同的许可,但没有运气。谁能告
向 Twilio 发送 SMS 时,Twilio 会向指定的 URL 发送多个请求,以通过 Webhook 提供该 SMS 传送的状态。我想让这个回调异步,所以我开发了一个 Cloud Functio
我需要更改我的项目 ID,因为要验证的 Firebase 身份验证链接在链接上显示了项目 ID,并且由于品牌 reshape ,项目名称已更改。根据我发现的信息,更改项目 ID 似乎不太可能。我正在考
用于部署我的 Angular 应用程序的 CI/CD 管道已关闭,但我看到 Google Cloud Run 在容器镜像更新后没有部署新修订版。 我已将 Cloud Build 设置为在 GitHub
报价https://cloud.google.com/load-balancing/docs/https/setting-up-https-serverless#enabling While Goog
Cloud Spanner 提供了两种不同的 API。 Cloud Spanner 读取与 Cloud Spanner SQL API 之间有什么区别? 最佳答案 在幕后,它们都使用相同的执行机制,因
我是 GCP 堆栈的新手,所以我对用于存储数据的 GCP 技术数量感到非常困惑: https://cloud.google.com/products/storage 虽然上面的文章中没有提到googl
我发现 Google Cloud Functions 的网络出站费用令人惊讶,我正在尝试了解发生这种情况的原因以及如何避免这种情况。 Stackdriver 监控表明有问题的函数是我的 ingest
我使用 Prisma使用 Cloud Run 和 Cloud SQL。在向 prisma.schema 提供 DATABASE_URL 后,它会在运行时抛出一个错误。 Can't reach data

我是一名优秀的程序员,十分优秀!