
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


负载均衡,英文名称为Load Balance,其含义就是指将负载(工作任务)进行平衡、分摊到多个操作单元上进行运行 。
以下为几种负载均衡策略介绍 。
大家很多时候说到随机的负载均衡都会想到 Round Robin, 其实 Round Robin并非随机, 。
Random 这种是真正意义上随机,根据随机算法随意分配请求到服务器.
优点:
缺点:
如上述,其实轮询是平均策略,并非随机策略, 。
它的具体策略内容如下:
负载均衡负责者有一份 服务器列表, 。
它会将其做排序,形成固定的 1 到 N 的顺序列表排队, 。
每次请求都会队列依次选择一位没有轮到的服务器同志接受 请求任务, 。
当整个队列都接受过任务后,就会从头开始新一轮的任务排队.
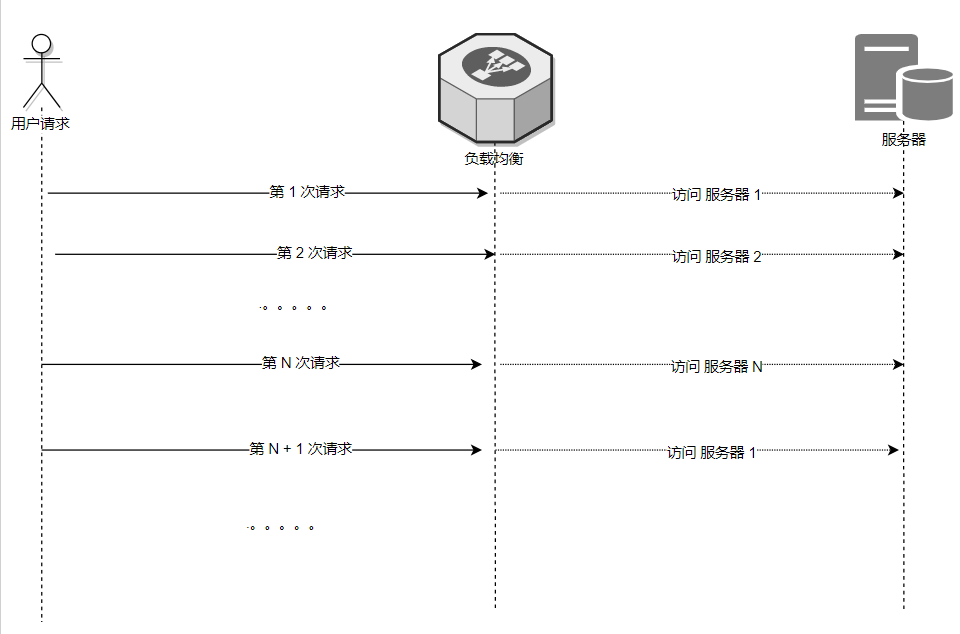
而大家为什么很多时候又说它是随机策略呢?
主要是对请求的client 来说, 这一次和下一次请求的服务器并不一定是同一个服务器,所以像是随机.
优点:
缺点:
从名字我们就能很轻松明白了, 。
它的策略非常简单: 就是每次取连接计数最小的那个服务器使用 。
优点:
缺点:
其他的负载均衡策略都适合于无状态服务, 。
只有 Hash 是专门解决有状态服务的负载均衡问题的.
它的具体策略就以其中简单的做法作为说明:
比如 ip 或者 url hash, 会用 ip 或者 url 的string 根据 hash 算法 算出固定的整型数值, 。
然后用该整型数值 根据 服务器数量 取模运算 得出对应哪一台机器, 。
从而形成 粘机 的效果 。
优点:
缺点:
印象中好像该方式最早见于 Finagle(Twitter的客户端RPC库) 中.
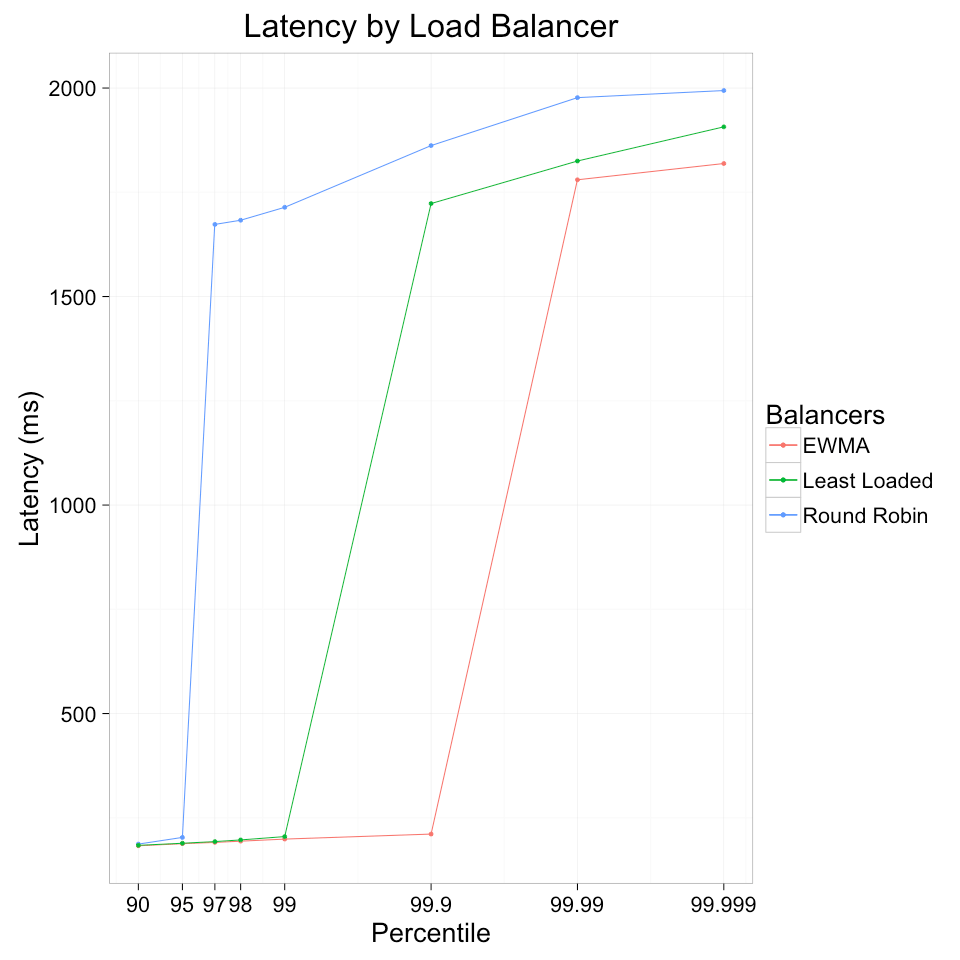
理论上来说服务器 在cpu 算力不足,网卡负荷过大,端口不足等等各种情况下,响应的时间都会存在明显变长的情况 。
那么响应的延迟变化就可以一定程度上用来评价服务器的负载以及服务器自身情况, 。
EWMA 的思想就是衡量请求延迟变化来动态优化负载均衡效果.
简单来说,EWMA就是 保持每个服务器请求的往返时间的移动平均值,以未完成请求的数量加权,并将流量分配给成本函数最小的服务器.
一般来说,还会使用P2C策略结合 EWMA使用,以避免同一时间集中命中同一台服务器。 (P2C 就是随机选取两台服务器,比较他们俩的EWMA值,取最小的那一个) 。
linkerd 做过一个负载均衡的测验,其结果 (当然并不一定代表实际效果) 。
优点:
缺点:
严格来说,权重很少作为单独的负载均衡策略, 。
一般都是与上述各种负载均衡策略进行组合.
权重的目的主要是解决 我们在已知或者能预估出服务器的负载能力的情况下, 我们如何更好的预设资源的分配.
所以现在一般这些负载均衡算法都会提供 权重参数以便大家预设负载比例, 。
甚至一些还尝试用机器学习等手段动态调整权重参数等,以便更快调整资源负载情况 。
篇幅关系,这里不解释每一个怎么实现了,只介绍 轮循(Round Robin) 。
以下内容更新到 openresty-dev-1.rockspec 。
-- 依赖包
dependencies = {
"lua-resty-balancer >= 0.04",
}
然后执行 。
luarocks install openresty-dev-1.rockspec --tree=deps --only-deps --local
具体demo 代码如下:
worker_processes 1; #nginx worker 数量
error_log logs/error.log; #指定错误日志文件路径
events {
worker_connections 1024;
}
http {
log_format main '$remote_addr [$time_local] $status $request_time $upstream_status $upstream_addr $upstream_response_time';
access_log logs/access.log main buffer=16384 flush=3; #access_log 文件配置
lua_package_path "$prefix/deps/share/lua/5.1/?.lua;$prefix/deps/share/lua/5.1/?/init.lua;$prefix/?.lua;$prefix/?/init.lua;;./?.lua;/usr/local/openresty/luajit/share/luajit-2.1.0-beta3/?.lua;/usr/local/share/lua/5.1/?.lua;/usr/local/share/lua/5.1/?/init.lua;/usr/local/openresty/luajit/share/lua/5.1/?.lua;/usr/local/openresty/luajit/share/lua/5.1/?/init.lua;";
lua_package_cpath "$prefix/deps/lib64/lua/5.1/?.so;$prefix/deps/lib/lua/5.1/?.so;;./?.so;/usr/local/lib/lua/5.1/?.so;/usr/local/openresty/luajit/lib/lua/5.1/?.so;/usr/local/lib/lua/5.1/loadall.so;";
# 开启 lua code 缓存
lua_code_cache on;
upstream nature_upstream {
server 127.0.0.1:6699; #upstream 配置为 hello world 服务
# 一样的balancer
balancer_by_lua_block {
local balancer = require "ngx.balancer"
local upstream = ngx.ctx.api_ctx.upstream
local ok, err = balancer.set_current_peer(upstream.host, upstream.port)
if not ok then
ngx.log(ngx.ERR, "failed to set the current peer: ", err)
return ngx.exit(ngx.ERROR)
end
}
}
init_by_lua_block {
-- 初始化 lb
local roundrobin = require("resty.roundrobin")
local nodes = {k1 = {host = '127.0.0.1', port = 6698}, k2 = {host = '127.0.0.1', port = 6699}}
local ns = {}
for k, v in pairs(nodes) do
-- 初始化 weight
ns[k] = 1
end
local picker = roundrobin:new(ns)
-- 初始化路由
local radix = require("resty.radixtree")
local r = radix.new({
{paths = {'/aa/d'}, metadata = picker},
})
-- 匹配路由
router_match = function()
local p, err = r:match(ngx.var.uri, {})
if err then
log.error(err)
end
-- 执行 roundrobin lb 选择
local k, err = p:find()
if not k then
return nil, err
end
return nodes[k]
end
}
server {
#监听端口,若你的8699端口已经被占用,则需要修改
listen 8699 reuseport;
location / {
# 在access阶段匹配路由
access_by_lua_block {
local upstream = router_match()
if upstream then
ngx.ctx.api_ctx = { upstream = upstream }
else
ngx.exit(404)
end
}
proxy_http_version 1.1;
proxy_pass http://nature_upstream; #转发到 upstream
}
}
#为了大家方便理解和测试,我们引入一个hello world 服务
server {
#监听端口,若你的6699端口已经被占用,则需要修改
listen 6699;
location / {
default_type text/html;
content_by_lua_block {
ngx.say("HelloWorld")
}
}
}
}
启动服务并测试 。
$ openresty -p ~/openresty-test -c openresty.conf #启动
$ curl --request GET 'http://127.0.0.1:8699/aa/d' #第一次
<html>
<head><title>502 Bad Gateway</title></head>
<body>
<center><h1>502 Bad Gateway</h1></center>
</body>
</html>
$ curl --request GET 'http://127.0.0.1:8699/aa/d' #第二次
HelloWorld
$ curl --request GET 'http://127.0.0.1:8699/aa/d' #第三次
<html>
<head><title>502 Bad Gateway</title></head>
<body>
<center><h1>502 Bad Gateway</h1></center>
</body>
</html>
$ curl --request GET 'http://127.0.0.1:8699/aa/d' #第四次
HelloWorld
可以看到 一次失败一次成功轮着来,证明 lb 起效 。
所有这里介绍的lb实现都可以参考 nature 中的例子 。
最后此篇关于构建apigateway之负载均衡的文章就讲到这里了,如果你想了解更多关于构建apigateway之负载均衡的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
在 Web 应用程序架构设计期间,我必须从概念上计算我的服务器之一可以服务多少个当前客户端。然后我可以预算它。 那么,有什么公式可以遵循吗?或者,你如何计算这个?或者,通常,一个 httpd/tomc
关闭。这个问题不符合Stack Overflow guidelines .它目前不接受答案。 要求我们推荐或查找书籍、工具、软件库、教程或其他场外资源的问题对于 Stack Overflow 来说是
我正在使用 Angular 5,我正在尝试在加载 div 的背景图像时获取加载图标。 如果它是一个普通的 img,我对此没有问题,但如果我尝试将它作为背景,它就不起作用。 这里是一些示例代码 app.
我们怎么知道我们的程序在 CPU 上有多少负载? 我尝试使用 htop 找到它。但是 htop 不会给 cpu 负载。它实际上给出了我程序的 cpu 利用率(使用 pid)。 我正在使用 C 编程,L
我们发现从Spark 1.3到当前的Spark 2.0.1以来,从Oracle数据库使用Spark的API加载数据一直很慢。典型的代码在Java中是这样的: Map options =
我有时会收到 mnesia overloaded主要使用时的错误消息 async_dirty查询和 ram_copies表。所以为了了解发生了什么,我想获得更多关于 mnesia 状态的信息,例如每秒
对于通常使用很少 CPU 的程序来说,内核 CPU 非常高。 Linux 机器在状态之间交替。大多数时候,程序使用低 CPU 正常执行。在 CPU“激增”期间,程序使用 100% 可用 CPU 使用高
我正在使用 Raspberry Pi 2 来路由 wifi-eth 连接。因此,从 eth 方面来看,我有一台可以使用 Pi wifi 连接到互联网的计算机。在 Raspberry 上我启动 htop
基本上我有一个网页,其中有一个 iframe 可以从不同的域加载另一个网页。它移动得很慢,我想证明整个页面很慢只是因为 iframe 内的页面。 有什么方法可以测量总页面负载以及总页面负载中有多少%来
我们有一个基于 Spring 的应用程序,它充当使用其他 Rest API 的编排层。我只想测试这个组件的性能,而不测试正在使用的下游 api。 我正在寻找有关如何完成此操作的任何架构建议? 当前的方
我正在学习 hibernate 。为了进行测试,我使用无效 key 调用了 session.load 。当我在调试器(JB Idea)中跨过该行后,没有任何反应 - 我预计会得到 ObjectNotF
我正在开发一个小型的待办事项 PHP 应用程序。我正在使用 jQuery 构建 HTML。其中一个是一个按钮,用于启动一个模式,允许用户编辑该项目。我很好奇加载数据时更好的方法是什么: 1) 在初始加
我尝试在 twitch 播放器中使用 angular 作为覆盖标记。 我将 ng-repear 与(键,值)结合使用。 //player is here 设置是一个全局对象。但是当我尝试加载页面
我即将了解 C 语言中的特定进程如何在特定时间范围内加载 CPU。该进程可能会在运行时切换处理器核心,因此我也需要处理这个问题。 CPU为ARM处理器。 我研究了从标准顶部获取负载的不同方法,perf
这个问题在这里已经有了答案: XMLHttpRequest Origin null is not allowed Access-Control-Allow-Origin for file:/// t
您好,我正在用 Java 开发负载平衡算法。在我的系统中将有一个主节点和 n 个从节点。主节点将接收查询分发给它的从节点。但是在将查询分发到其从节点之一之前,我想测量从节点中的当前负载,以检查特定从节
我正在渲染由大约 50 万个三角形组成的相当重的对象。我使用 opengl 显示列表,在渲染方法中只调用 glCallList。我认为一旦图形基元被编译成显示列表,cpu 的工作就完成了,它只是告诉
我正在尝试加密 Sipdroid,为此我必须在 RTP 数据包获得编码的音频负载后对其进行加密。我在 RTP 数据包类中使用这个函数: public byte[] getPayload() {
我正在尝试解析以下 JSON 负载: { "results":[ [ 298.648132, 280.68692, 356.54
在动画期间 cpu 负载非常高(高达 75%) 是否有优化代码以降低 CPU 负载的方法? 我的代码: ImageView myImageView = (ImageView)findViewById(

我是一名优秀的程序员,十分优秀!