
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


本篇文章会详细介绍web开发模式、API接口及其接口测试工具、restful规范、还有经常分不清又很重要的序列化与反序列化的部分,初级交接触APIView、Request类。每个人对知识点的理解都会不一样,因此我会用自己的理解撰写一篇文章,这篇将会是我对学习的一个态度更是对自己的一个交代。那咱们开始吧!!嘿嘿嘿 DRF安装与使用 。
1、web开发模式
在我们的web开发应用中,有两种开发模式,一是前后端不分离即全栈开发 咱们的BBS项目是典型例子。二是前后端分离,这种开发模式是我们以后的重点发展方向,因为研究的事件一旦变多了我们就会想办法解耦合,内容越细越精嘛,这就为什么会出现了后者,这种开发模式个人觉得整个过程非常舒服,每个人清楚的知道自己要干什么,自己的主要任务是什么。前端和后端分离之后,后端程序员只需要写接口也就是说与通过后端代码操作数据库,说白了就是对数据增删改查。接下来通过图片的方式更加直观的解释,会帮助到咱们的理解.
前后端不分离:客户端看到的所有页面和后端关键逻辑都是由同一个服务端提供的 。
前后端分离:前端只负责页面且由独立服务端提供服务,后端只负责返回数据即可 。
2、API接口
API接口即应用程序接口(Applicant Programming Interface),应用程序对外提供了一个操作数据的入口,这个入口的实现可以是通过FBV或CBV方式来完成、也可以是一个URL地址或一个网址。当客户端调用该入口时应用程序会执行相应的代码操作、给客户端完成对应的功能。这样可以减小前后端之间的合作成本,可以简单的理解为API接口是前后端之间信息交互的媒介.
3、接口测试工具
我们脑海里肯定会出现一个疑问,浏览器就是天生的测试工具为嘛还要搞一个其他工具呢?兄dei那你就太天真来,浏览器只能解决get请求的测试需求,二程序员还要测试其他的请求,比如post、put、delete等等。这时候浏览器大哥也无可奈何了嘛!接口测试工具有以下6个:Poster、Postman、RESTClient、Fiddler、Jmeter、 WireMock。接口测试工具是用于测试系统组件间接口的工具,主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点。同一类的软件使用以及底层原理都大差不差、举一反三,那我们本次学习那postman为例展开从软件下载到基本使用的操作过程。由于本姑娘喜欢分类与收纳,因此我把postman的安装与使用单独拎出来写了点击该地址既可以看到详细的过程。快戳我---> postman的安装与使用 。
4、restful规范
REST全称为Representational State Transfer即表述性状态转移,RESTful是一种专门为web开发而定义API接口的设计风格、尤其是适用于前后端分离的应用模式中。这种风格的理念是后端开发的任务就是提供数据、对外提供的是数据资源的访问接口、所以咋定义接口时客户端访问的URL路径就表示这种要操作的数据资源。而对于数据资源分别使用post、get、delete、update等请求动作来表达对数据的增删改查。RESTful规范是一种通用规范、不限制语言和开发框架的使用。因此、我们当然可以使用任何一门编程语言、任何框架都可以实现RESTful规范的API接口.
- 为安全起见通常用https(http+ssl/tsl)协议
- 接口中要携带API标识如https://www.baidu.com/api/books
- 为满足多版本共存路径中带版本信息如https://www.baidu.com/api/v1/books
- 因为URL资源、均使用名词、尽量不要出现动词
- 而且资源的操作方式由请求方式决定
- 在请求地址中带过滤条件 在?号后面name=米热&price=11的形式
- 响应状态码有两种默认的和公司自定义的
- 返回数据中带错误信息
- 返回的结果一个规定规范但是公司有自己的格式
- 响应数据中带连接
5、序列化与反序列化
序列化与反序列化的核心:转换数据格式 。
API接口开发最核心最常见的一个代码编写过程就是序列化,所谓的序列化就是转换数据格式,其有两个阶段,一是序列化:把后端的数据编程字符串或者json数据提供给别人、二是反序列化:前端js提供的数据是json格式数据,对于Python而言json就是字符串需要反序列化成字典、将字典转换成模型对象,这样才能把数据保存到数据库中 。
- 序列化:查数据(单条多条)、后端数据库到前端页面、eg:登录接口
- 反序列化:修改及存储数据、前端页面到后端数据库、eg:注册接口
6、快速体验drf框架的厉害
from rest_framework.routers import SimpleRouter
router = SimpleRouter()
router.register('books', views.BookView, 'books')
urlpatterns = [
path('admin/', admin.site.urls),
]
# 两个列表相加 [1,2,4] + [6,7,8]=
urlpatterns += router.urls
from .serializer import BookSerializer
from rest_framework.viewsets import ModelViewSet
class BookView(ModelViewSet):
queryset = Book.objects.all()
serializer_class = BookSerializer
from rest_framework import serializers
from .models import Book
class BookSerializer(serializers.ModelSerializer):
class Meta:
model = Book
fields = '__all__'
7、CBV源码分析

8、APIView类及其源码分析
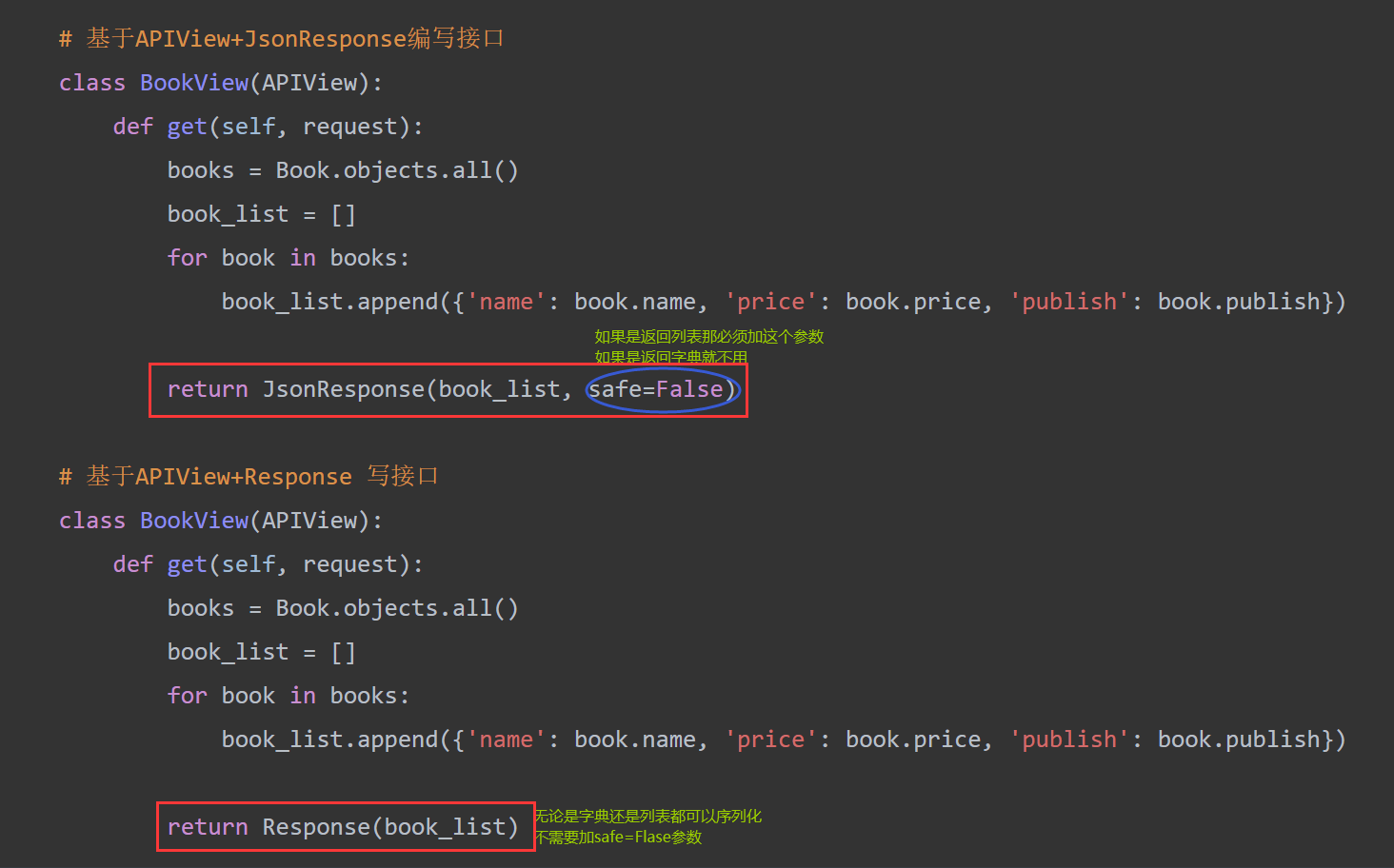
# 基于APIView+JsonResponse编写接口
class BookView(APIView):
def get(self, request):
books = Book.objects.all()
book_list = []
for book in books:
book_list.append({'name': book.name, 'price': book.price, 'publish': book.publish})
return JsonResponse(book_list, safe=False)
# 基于APIView+Response 写接口
class BookView(APIView):
def get(self, request):
books = Book.objects.all()
book_list = []
for book in books:
book_list.append({'name': book.name, 'price': book.price, 'publish': book.publish})
return Response(book_list)
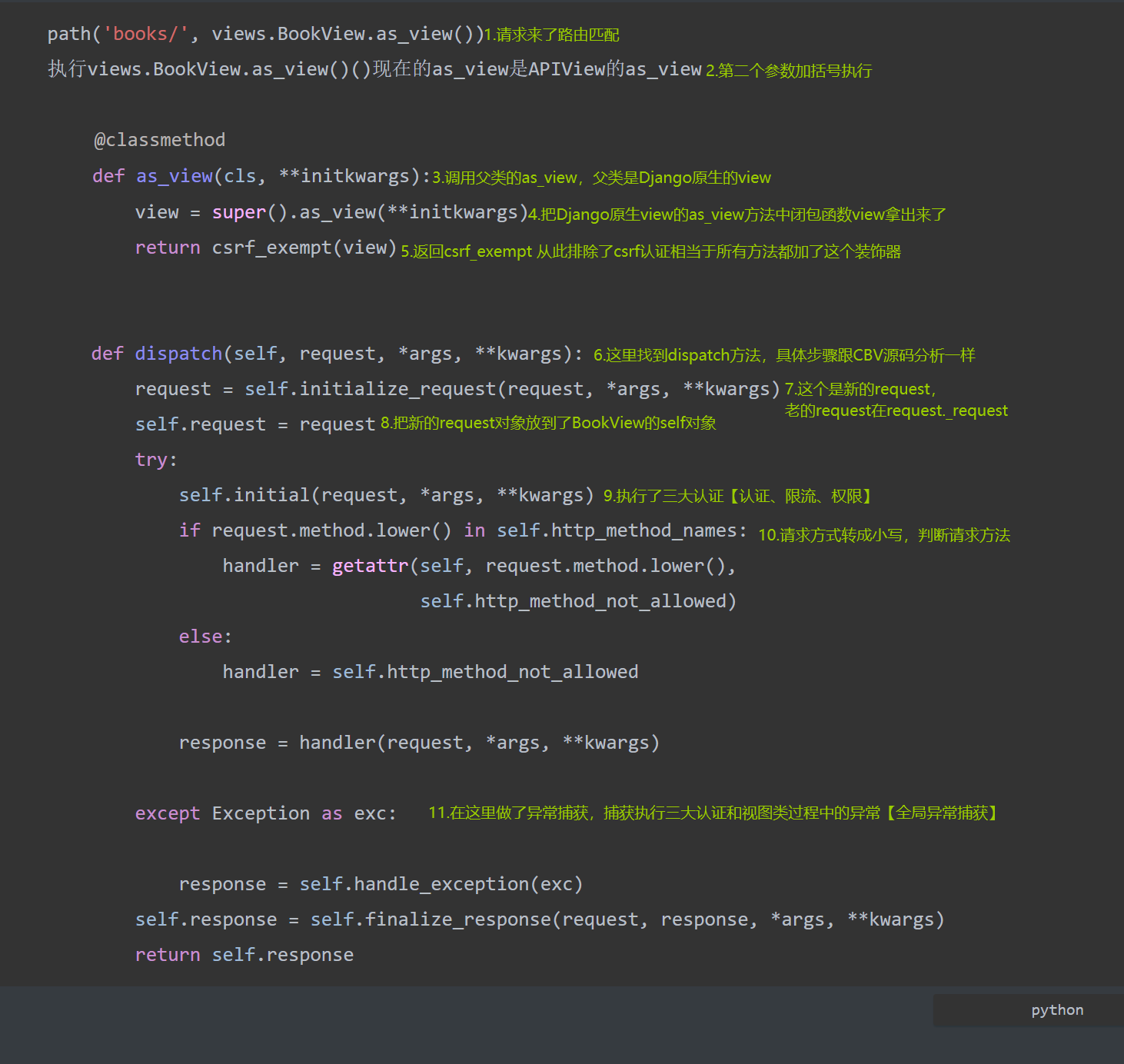
- 首先去除了所有的CSRF验证
- 包装了新的request类request._request
- 执行视图类之前执行了三大认证
- 为确保出现异常设置了全局异常捕获
9、Request类
- 老的request:django.core.handlers.wsgi.WSGIRequest
- 新的request:from rest_framework.request import Request
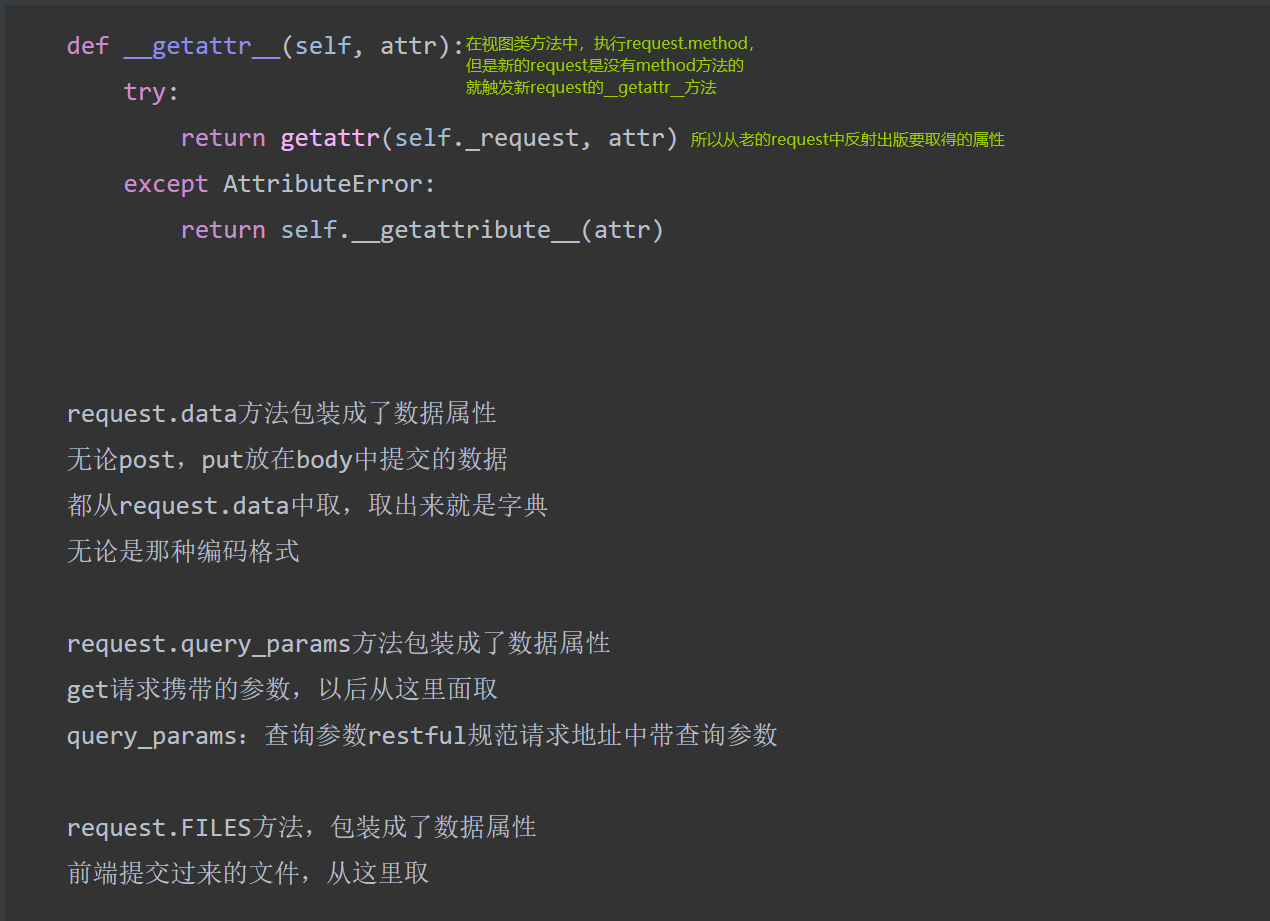
- 新的request跟老的request用起来一样、新的取不到双下getattr就取老的
- request.data无论是什么编码什么请求方式字典从body里面取数据取出来是字典
- request.query_params就是原来的request._request.GET,请求携带的参数
- request.FILES上传的文件从这里取
10、序列化器及其用法
# 视图层代码
from django.http import JsonResponse
from .models import Book
from django.views import View
import json
class BookView(View):
"""1.查所有数据"""
def get(self, request):
# 查询出所有图书,queryset对象,不能直接给前端
books = Book.objects.all()
book_list = []
for book in books:
book_list.append({'name': book.name, 'price': book.price, 'publish': book.publish})
return JsonResponse(book_list, safe=False, json_dumps_params={'ensure_ascii': False})
"""2.新增一条数据"""
def post(self, request):
# 取出前端传入的数据
name = request.POST.get('name')
price = request.POST.get('price')
publish = request.POST.get('publish')
# 存到新增的对象字典
book = Book.objects.create(name=name, price=price, publish=publish)
# 返回新增的对象字典
return JsonResponse({'name': book.name, 'price': book.price, 'publish': book.publish})
class BookDetailView(View):
"""3.查询单个数据"""
def get(self, request, pk):
book = Book.objects.filter(pk=pk).first()
return JsonResponse({'id': book.id, 'name': book.name, 'price': book.price, 'publish': book.publish})
"""4.修改数据"""
def put(self, request, pk):
# 查到要改的
book = Book.objects.filter(pk=pk).first()
# 前端使用json格式提交 自己保存
book_dict = json.loads(request.body)
book.name = book_dict.get('name')
book.price = book_dict.get('price')
book.publish = book_dict.get('publish')
book.save()
return JsonResponse({'id': book.id, 'name': book.name, 'price': book.price, 'publish': book.publish})
def delete(self, request, pk):
"""5.删除数据"""
Book.objects.filter(pk=pk).delete()
return JsonResponse(data={})
# 路由层代码
from django.contrib import admin
from django.urls import path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
path('api/v1/books/<int:pk>/',views.BookDetailView.as_view()),
path('api/v1/books/', views.BookView.as_view()),
]
# 路由层代码
from django.contrib import admin
from django.urls import path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
path('books/', views.BookView.as_view()),
path('books/<int:pk>/', views.BookDetailView.as_view()),
]
# 视图层
from django.shortcuts import render
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import Book
from .serializer import BookSerializer
class BookView(APIView):
"""1.查所有数据 序列化过程"""
def get(self, request):
books = Book.objects.all()
# 需要序列化类来完成---得有序列化类即BookSerializer
# instance参数是要序列化的数据books queryset对象
# 要传的数据是多条那就得加上many=True参数,如果是单挑就不用传
ser = BookSerializer(instance=books, many=True)
return Response(ser.data)
def post(self, request):
"""2.新增数据 反序列化过程"""
# request.data 前端提交数据---校验数据---存数据,前端传入的数据给data参数
ser = BookSerializer(data=request.data)
# 校验数据
if ser.is_valid():
ser.save()
return Response({'code':100, 'msg':'新增成功', 'result':ser.data})
else:
return Response({'code':101, 'msg':ser.errors})
class BookDetailView(APIView):
"""3.获取单个数据 序列化过程"""
def get(self, request, *args, **kwargs):
book = Book.objects.filter(pk=kwargs.get('pk')).first()
ser = BookSerializer(instance=book)
return Response(ser.data)
def put(self, requet, pk):
"""4.修改数据 反序列化过程"""
book = Book.objects.filter(pk=pk).first()
ser = BookSerializer(data=requet.data, instance=book)
if ser.is_valid():
ser.save()
return Response({'code':100, 'msg':'修改数据', 'result':ser.data})
else:
return Response({'code':101, 'msg':ser.errors})
def delete(self, request, pk):
Book.objects.filter(pk=pk).delete()
return Response({'code':100,'msg':'删除成功'})
# 在app01目录下新建serializer.py文件 写如下序列化类
from rest_framework import serializers
from rest_framework.exceptions import ValidationError
from .models import Book
class BookSerializer(serializers.Serializer):
# 序列化模型表的三个字段
name = serializers.CharField()
price = serializers.CharField()
publish = serializers.CharField()
def create(self, validated_data):
"""数据保存逻辑"""
# 保存到数据库
# validated_data是校验过后的数据
book = Book.objects.create(**validated_data)
return book
def update(self, instance, validated_data):
"""数据更新逻辑"""
# instance是要修改的对象
instance.name = validated_data.get('name')
instance.price = validated_data.get('price')
instance.publish = validated_data.get('publish')
# orm的单个对象 修改了单个对象的属性 只要调用对象.save就能把修改保存的数据库
instance.save()
# 返回修改后的对象
return instance
def validate_name(self, name):
# 校验name是否合法
if name.startswith('sb'):
# 校验啊不能通过 抛异常
raise ValidationError('名字不能以sb开头')
else:
return name
def validate(self, attrs):
# 校验过后的数据 书名跟出版社名字不能一样
if attrs.get('name') == attrs.get('publish'):
raise ValidationError('书名和出版社名不能一样')
else:
return attrs
需要了解的字段类以及其参数 。
1.布尔字段 BooleanField
BooleanField() # 不用传参数,自带布尔值
2.无布尔值字段 NullBooleanField
NullBooleanField() # 不用传参数,自带无布尔值
4.邮箱字段 EmailField
EmailField(max_length=None, min_length=None, allow_blank=False)
5.正则字段 RegexField
RegexField(regex, max_length=None, min_length=None, allow_blank=False)
6.正则字段 SlugField
SlugField(max_length=50, min_length=None, allow_blank=False) # 验证正则模式 [a-zA-Z0-9-]+
7.路由字段 URLField
URLField(max_length=200, min_length=None, allow_blank=False)
8.UUIDField # UUID是通用唯一识别码(Universally Unique Identifier)
UUIDField(format=’hex_verbose’)
9.API地址字段 IPAddressField
IPAddressField(protocol=’both’, unpack_ipv4=False, **options)
10.小数字段 FloatField
FloatField(max_value=None, min_value=None)
11.年月日字段 DateField
DateField(format=api_settings.DATE_FORMAT, input_formats=None)
12.时分秒 TimeField
TimeField(format=api_settings.TIME_FORMAT, input_formats=None)
13.持续时间字段 DurationField
DurationField()
14.选择字段 ChoiceField
ChoiceField(choices) choices与Django的用法相同
15.多选字段 MultipleChoiceField
MultipleChoiceField(choices)
16.文件字段 FileField
FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL)
17.图像字段 ImageField
ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL)
必须掌握的字段类以及参数 。
前端传进来的是什么在序列化类里面就用什么字段 后端在表模型写的方法是什么在序列化类里面就用什么字段 重点学习的两个字段 列表字段ListField 字典字段DictField 没有参数 在定制字段的时候用到具体使用方法请见@模型表中定制方法,如下嘿嘿嘿!! 。
1.CharField
CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True)
2.IntegerField
IntegerField(max_value=None, min_value=None)
3.DecimalField
DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None)
# max_digits: 最多位数 decimal_palces: 小数点位置
4.DateTimeField DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None)
序列化器需要用到的两个重要字段和两个参数 。
- ListField当需要接收一个 list 的时候使用
- DictField当传入的数据是 dict 时使用
- read_only 表明该字段仅用于序列化输出,默认False
- write_only 表明该字段仅用于反序列化输入,默认False
- 字段参数校验规则
- 字段单独设置校验
- 局部钩子校验规则
- 全局钩子校验规则
# 反序列化的校验 只要在序列化类中写局部和全局钩子
局部钩子
def validate_字段名(self,name):
校验通过,返回name,
如果不通过,抛出异常
全局钩子
# attr,前端传入的数据,走完局部钩子校验后的数据
def validate(self,attrs):
校验通过,返回attrs
如果不通过,抛出异常
# 创建关联表、迁移数据库、录入伪数据
from django.db import models
class Book(models.Model):
"""1.书籍表"""
name = models.CharField(max_length=32)
price = models.CharField(max_length=32)
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE)
authors = models.ManyToManyField(to='Author')
class Publish(models.Model):
"""2.出版社表"""
name = models.CharField(max_length=32)
address = models.CharField(max_length=32)
class Author(models.Model):
"""3.作者表"""
name = models.CharField(max_length=32)
phone = models.CharField(max_length=11)
创建完模型表之后需要录入一些伪数据,今天我们创建的是多张关联表,录入数据不能乱录入。原则是先录入结构简单的表(即没有外键的表),本次录入数据的顺序的话author》publish》book 。
# 写序列化类
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
real_name = serializers.CharField(max_length=8, source='name')
real_price = serializers.CharField(source='price')
publish = serializers.CharField(source='publish.name')
authors = serializers.CharField(source='authors.all')
# 写视图类
from django.shortcuts import render
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import Book, Author, Publish
from .serializer import BookSerializer
class BookView(APIView):
def get(self, request):
books = Book.objects.all()
ser = BookSerializer(instance=books, many=True)
return Response(ser.data)
# 写路由
from django.contrib import admin
from django.urls import path
from app01 import views
urlpatterns = [
path('books/', views.BookView.as_view()),
]
# 定制关联字段的显示形式
一对多>>>显示字典
多对多>>>显示列表套字典
class BookSerializer(serializers.Serializer):
name = serializers.CharField(max_length=8)
price = serializers.CharField()
publish_detail = serializers.SerializerMethodField()
def get_publish_detail(self, obj):
return {'name': obj.publish.name, 'address': obj.publish.address}
author_list = serializers.SerializerMethodField()
def get_author_list(self, obj):
l = []
for author in obj.authors.all():
l.append({'name': author.name, 'phone': author.phone})
return l
# 在serializer.py中写这个代码
class BookSerializer(serializers.Serializer):
name = serializers.CharField(max_length=8)
price = serializers.CharField
publish_detail = serializers.DictField()
author_list = serializers.ListField()
# 在models.py中写这两个方法
class Book(models.Model):
"""1.书籍表"""
name = models.CharField(max_length=32)
price = models.CharField(max_length=32)
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE)
authors = models.ManyToManyField(to='Author')
def publish_detail(self):
return {'name':self.publish.name, 'address':self.publish.address}
def author_list(self):
l =[]
for author in self.authors.all():
l.append({'name':author.name, 'phone':author.phone})
return
"""
因为这个方法针对一对多和多对多字段而设置的
而且是外键 所以外键在哪里这两个方法建在哪里
"""
ModelSerializer 是对 serializers 的进一步封装 。
"""ModelSerializer的使用"""
class BookSerializer(serializers.ModelSerializer):
# 跟表有关联
class Meta:
# 跟book建立了关系 序列化类和表模型类
model = Book
# 序列化所有book中的name和price字段,如果这样写fields = '__all__' # 可以序列化所有字段
fields = ['name', 'price', 'publish_detail', 'author_list', 'publish', 'authors']
# 定制name反序列化时最长不能超过8
extra_kwargs = {'name': {'max_length': 8},
'publish_detail': {'read_only': True},
'auth0r_list': {'read_only': True},
'publish': {'write_only': True},
'authors': {'write_only': True}
}
def validate_name(self, name):
if name.startswith('sb'):
raise ValidationError('不能以sb开头')
else:
return name
我们在分析源代码的时候会经常看到assert和try,因为就一个关键词节省了很多逻辑代码,其作用是声明其布尔值必须为真的判定,如果发生异常就说明表达示为假。可以理解assert断言语句为raise-if-not,用来测试表示式,其返回值为假,就会触发异常.
# 如果不用断言实现需求是如下
name = 'almira'
if name == 'almira':
print('yep')
else:
print('nope')
# 如果使用断言实现需求是如下
# 断定是就跑正常逻辑 如果不是就抛异常
assert name == 'almira'
print('keep it up')
11、DRF之请求request
方式一:局部配置 。
在APIView及其子类的视图类中配置具体操作步骤如下
# 1.需要先导入
from rest_framework.parsers import JSONParser,FormParser,MultiPartParser
# 2.在视图cbv里面写需要用的格式
class BookView(APIView):
parser_classes = [JSONParser,]
方式二:全局配置 。
直接在配置文件里面改配置既可影响全局
# 不需要用的就注释掉既可
REST_FRAMEWORK = {
'DEFAULT_PARSER_CLASSES': [
# 'rest_framework.parsers.JSONParser',
'rest_framework.parsers.FormParser',
# 'rest_framework.parsers.MultiPartParser',
],
}
方式三:局部全局 。
局部配置方法和全局配置方法混着用
有个需求:全局配了一个某个视图类却想要三个怎么解决?
# 解决方法很简单
"""
直接在该视图类配置3个就可以
因为先从自身类找找不到去项目找再找不到就去drf默认配置找
"""
request源码分析上面已经分析过哦 。
12、DRF之响应response
"""
drf是Django的一个APP因此当然要注册 切记哦
drf的响应如果使用浏览器和postman访问同一个接口返回的格式是不一样
因为drf做了个判断 如果是浏览器好看一些 如果是postman只要json数据
"""
方式一:局部配置 。
from rest_framework.renderers import JSONRenderer,BrowsableAPIRenderer
class BookView(APIView):
renderer_classes=[JSONRenderer,]
方式二:全局配置 。
REST_FRAMEWORK = {
'DEFAULT_RENDERER_CLASSES': [
'rest_framework.renderers.JSONRenderer',
'rest_framework.renderers.BrowsableAPIRenderer',
],
}
方式三:使用顺序 。
# 一般就用内置的即可
优先使用视图类中的配置,其次使用项目配置文件中的配置,最后使用内置的
# drf 的Response 源码分析
from rest_framework.response import Response
视图类的方法返回时,retrun Response ,走它的__init__,init中可以传什么参数
# Response init可以传的参数
def __init__(self,
data=None,
status=None,
template_name=None,
headers=None,
exception=False,
content_type=None)
data:之前咱们写的ser.data 可以是字典或列表,字符串---》序列化后返回给前端---》前端在响应体中看到的就是这个
status:http响应的状态码,默认是200,你可以改
drf在status包下,把所有http响应状态码都写了一遍,常量
from rest_framework.status import HTTP_200_OK
Response('dddd',status=status.HTTP_200_OK)
template_name:了解即可,修改响应模板的样子,BrowsableAPIRenderer定死的样子,后期公司可以自己定制
headers:响应头,http响应的响应头
content_type :响应编码格式,一般不动
十3、两个视图基类、五个视图扩展类、九个视图子类
- APIView
- GenericAPIView
'''
# GenericAPIView属性
1 queryset:要序列化或反序列化的表模型数据
2 serializer_class:使用的序列化类
3 lookup_field :查询单条的路由分组分出来的字段名
4 filter_backends:过滤类的配置(了解)
5 pagination_class:分页类的配置(了解)
# GenericAPIView方法
1 get_queryset :获取要序列化的对象
2 get_object :获取单个对象
3 get_serializer :获取序列化类 ,跟它差不多的get_serializer_class,一般重写它,不调用它
4 filter_queryset :过滤有关系(了解)
'''
from rest_framework.generics import GenericAPIView
class BookView(GenericAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializer
def get(self, request):
objs = self.get_queryset() # 好处,可以重写该方法,后期可扩展性高
ser = self.get_serializer(instance=objs, many=True)
return Response(ser.data)
def post(self, request):
ser = self.get_serializer(data=request.data)
if ser.is_valid():
ser.save()
return Response({'code': 100, 'msg': '新增成功', 'result': ser.data})
else:
return Response({'code': 101, 'msg': ser.errors})
class BookDetailView(GenericAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializer
def get(self, request, pk):
obj = self.get_object() # 获取单条
ser = self.get_serializer(instance=obj)
return Response(ser.data)
def put(self, request, pk):
obj = self.get_object()
ser = self.get_serializer(instance=obj, data=request.data)
if ser.is_valid():
ser.save()
return Response({'code': 100, 'msg': '修改成功', 'result': ser.data})
else:
return Response({'code': 101, 'msg': ser.errors})
def delete(self, request, pk):
self.get_object().delete()
return Response({'code': 100, 'msg': '删除成功'})
- 新增 create方法 CreateModelMixin
- 删除 destroy方法 DestroyModelMixin
- 差单条 retrieve方法 RetrieveModelMixin
- 查所有 list方法 ListModelMixin
- 更新 update方法 UpdateModelMixin
from rest_framework.generics import GenericAPIView
from rest_framework.mixins import CreateModelMixin, UpdateModelMixin, DestroyModelMixin, RetrieveModelMixin, ListModelMixin
class BookView(GenericAPIView, ListModelMixin, CreateModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
def get(self, request):
return self.list(request)
def post(self, request):
return self.create(request)
class BookDetailView(GenericAPIView, RetrieveModelMixin, UpdateModelMixin, DestroyModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
def get(self, request, *args, **kwargs):
return self.retrieve(request, *args, **kwargs)
def put(self, request, *args, **kwargs):
return self.update(request, *args, **kwargs)
def delete(self, request, *args, **kwargs):
return self.destroy(request, *args, **kwargs)
周一过来再认真总结 。
最后此篇关于drf入门规范、序列化器组件、视图组件、请求与响应的文章就讲到这里了,如果你想了解更多关于drf入门规范、序列化器组件、视图组件、请求与响应的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
阅读目录 1、视图介绍 2、创建视图 3、查询视图 4、修改视图 5、删除视图 6、检查选项
基于函数的视图你已经get了,基于类的视图get了吗?CBV本质不知道?点进来看源码分析~ Django 视图之FBV 与 CBV FBV(function base views) 基于函数的视图,就
SQLite 视图(View) 视图(View)只不过是通过相关的名称存储在数据库中的一个 SQLite 语句。视图(View)实际上是一个以预定义的 SQLite 查询形式存在的表的组合。 视图
视图 什么是视图?视图的作用是什么? 视图(view)是一种虚拟存在的表,是一个逻辑表,它本身是不包含数据的。作为一个select语句保存在数据字典中的。 通过视图,可以展现基表(用来创建视图
代码如下: CREATE OR REPLACE VIEW BLOG_V_ADMIN (ID,NICKNAME,SEX,EMAIL,
创建视图 视图包含应用的 HTML 代码,并将应用的控制器逻辑和表现逻辑进行分离。视图文件存放在 resources/views 目录中。下面是一个简单的视图示例:
加密测试的存储过程 ? 1
简介数据库快照 数据库快照,正如其名称所示那样,是数据库在某一时间点的视图。是SQL Server在2005之后的版本引入的特性。快照
一 ,mysql事务 MYSQL中只有INNODB类型的数据表才能支持事务处理。 启动事务有两种方法 (1) 用begin,rollback,commit来实现 复制代码代码如
前言 在日常开发中,存储数据的最常用的方式便是数据库了,其中最为著名的便是MySQL数据库,因它简便易于上手而且可扩展性强大,跨平台使得它广为使用。上一篇文章,我们讲到了它的安装,今天我们就来
1、视图 视图:VIEW,虚表,保存有实表的查询结果,实际数据不保存在磁盘 物化视图:实际数据在磁盘中有保存,加快访问,MySQL不支持物化视图 基表:视图依赖的表 视图中的数据事实上
事项开启和使用 ? 1
代码如下: create PROCEDURE sp_decrypt(@objectName varchar(50)) AS begin begin tran&
前言 在之前 《Oracle打怪升级之路一》中我们主要介绍了Oracle的基础和Oracle常用查询及函数,这篇文章作为补充,主要介绍Oracle的对象,视图、序列、同义词、索引等,以及PL/SQL编

我是一名优秀的程序员,十分优秀!