
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4


当用户自定义类型时(struct 或 class),编译器会自动计算该类型占用的字节数.
C/C++ 为什么要内存对齐?我道行太浅, 摘抄 了网上的一个解释.
为了方便从内存中读取数据。假设没有内存对齐,在内存中存储一个 int 变量 x(占 4 字节),放在了地址 2-5 上。现在要读取 x 到寄存器中,CPU 知道读 int 一次应该读 4 字节,但是不会直接读地址 2-5(为什么不会?我也不知道啊!但是 CPU 有直接读 2-5 地址的功能,但它没有用起来),一次读出来,而是先读 0-3,再读 4-7,丢掉多余的字节。可以看到对齐后少读了一次内存,性能肯定得到提升了(我们知道 C/C++ 是追求极致性能的).
#include <iostream>
using namespace std;
// #pragma pack (1)
struct Test
{
int i1;
char c;
int i2;
double d;
};
int main(int argc, char* argv[])
{
cout << sizeof(Test) << endl; // 24
return 0;
}
如果没有内存对齐,Test 类型的大小应该是 4+1+4+8 = 17 字节,经过对齐后变成了 24 字节.
第 5 行注释就是设置内存对齐基数,取值一般是 1, 2, 4, 8, 若该值为 1 则表示不对齐 (不信就去掉注释再运行一次,输出肯定是 17).
#pragma pack () 设置的对齐基数是 i(现在机器一般都是 8,旧一些的应该是 4),struct 中“最大”成员所占用的字节数 j,则 n = min(i, j) ,也就是说 这个 struct 类型最终的大小必须是 n 的倍数 。 k = min(sizeof(memberType), n) , 它要求每个成员的 offset 必须是 k 的倍数,第一个成员的 offset 为 0 。比如一个 short 成员的 k = min(sizeof(short), n) 可以看出,当 i = 1 时就是不对齐;当 i >= j 时,i 不起作用.
假设 n = 8 。
先进行成员对齐:
#include <iostream>
using namespace std;
struct Test
{
int i1; // offset为0, 占用第0-3字节
char c; // 1 < 8, offset是1的倍数, 因此offset为4, 占用第4字节
int i2; // 4 < 8, offset是4的倍数, 因此offset为8, 占用第8-11字节
double d; // 8 == 8, offset是8的倍数, 因此offset为16, 占用第16-23字节
// 构造函数
Test(int ii1, char cc, int ii2, double dd):
i1(ii1), c(cc), i2(ii2), d(dd) {}
};
// 来验证一下
int main(int argc, char* argv[])
{
cout << sizeof(Test) << endl;
Test *pt = new Test(1, 'a', 2, 1.25); // 基地址
unsigned char* ppt = (unsigned char*)pt; // 强制类型转换, 按字节读
for (int i = 0; i < sizeof(Test); ++i) {
printf("%x ", *(ppt + i));
}
cout << endl;
// 1 0 0 0 61 f0 ad ba 2 0 0 0 d f0 ad ba 0 0 0 0 0 0 f4 3f
return 0;
}
再进行整体对齐:这个 struct 类型所需字节为 24 字节,恰好是 n 的倍数,无须在尾部额外填充.
内存排列如下图所示:
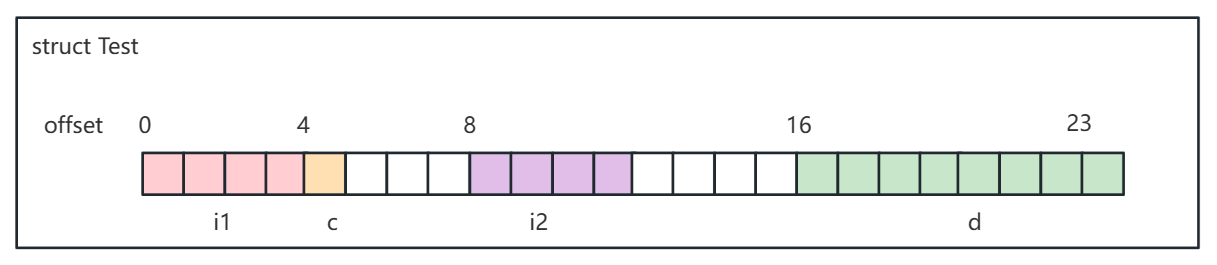
其中白色格子代表填充,其内容是不确定的.
按十六进制输出:1 0 0 0 61 f0 ad ba 2 0 0 0 d f0 ad ba 0 0 0 0 0 0 f4 3f 。
可以看到前面 4 字节是 1 0 0 0,是 i1 = 1 ; 。
第 5 字节是 61,是 'a' 的十六进制 ASCII 码; 。
然后 6-7 字节是填充的内容,不确定的; 。
第 8-11 字节是 2 0 0 0,是 i2 = 2 ; 。
第 12 - 15 字节是填充的内容,不确定的; 。
第 16-23 字节是 d = 1.25 的底层二进制表示(怎么算的我也忘了好久了,参考神书《CSAPP:深入理解计算机系统》即可找回记忆).
问:在 自定义类型嵌套 时,比如 Test1 嵌套正在 Test2 中,此时应该怎么进行内存对齐呢?
struct Test1
{
int i1;
char c;
int i2;
double d;
// 构造函数
Test1(int ii1, char cc, int ii2, double dd):
i1(ii1), c(cc), i2(ii2), d(dd) {}
};
struct Test2
{
Test1 t1;
int x;
};
答:先计算 Test1 所占字节大小 sizeof(Test1) ,然后继续按照上述基本原则计算 Test2 即可。如果是多重嵌套,那就递归找到那个成员全都是基本类型的 struct 开始计算,然后回溯.
问:继承体系中如何进行内存对齐?
struct A
{
int i;
char c1;
};
struct B: public A
{
char c2;
};
struct C: public B
{
char c3;
};
答:我也不会!我郁闷了,在我 64 位 Windows 操作系统 + gcc8.1.0 和 ubuntu18.04 + gcc7.5.0 上的运行结果都是 12! 。
但是我参考的一篇博客说,他的结果是 8 或 16! C++ 内存对齐 - tenos - 博客园 (cnblogs.com) 。
博客里说根据编译器类型拥有两种方式: 先继承后对齐 和 先对齐后继承 .
但是我无论按哪种方式, #pragma pack () 取 4 或 8,排列组合 2*2=4 种可能,我都算不出来 12!但是我能算出 8 和 16! 。
希望有朋友可以解答我的疑惑,万分感谢.
如果本文对你有帮助,请点个赞吧.
有任何疑问,欢迎评论和我一起讨论.
最后此篇关于C/C++内存对齐原则的文章就讲到这里了,如果你想了解更多关于C/C++内存对齐原则的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
GitOps描述了一种使用植根于 Git 版本控制系统的方法来操作和管理软件的方法。使用基于 GitOps 的工作流,通过要求将系统的特征定义为 Git 存储库中的文件,可以更轻松地开发、部署、维护和
关闭。这个问题不符合Stack Overflow guidelines .它目前不接受答案。 我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。 关闭 6 年前。
命令行货币转换器应用程序,提示用户输入源货币、源货币代码和目标货币代码,例如 C:\workspace> java CurrencyConverter 100.50 EUR GBP 应用程序返回源金额
得到这个实体: /** * @ORM\Table(name="shop_payment_details") * @ORM\Entity(repositoryClass="Acme\ShopBund
我有一个原则实体,无需调用 persist 或 flush 即可持久保存到数据库中。 我在下面很简单地重现了这个问题。正如您将看到的,此脚本从名为 MyEntity 的数据库表中加载一行,并获取一个以
在我的编程实践中,我经常遇到客户端和服务器端脚本之间数据重复的问题。 在这种情况下,我们可以讨论客户端的 JavaScript 和服务器端的 PHP 或 C# (ASP.NET)。 比方说,我有一段
简介 我在写关于继承问题的硕士论文并解决了一些问题 表明存在继承问题的指标。 像下面的例子: 示例 public static String getAnimalNoise(Animal animal)
就目前而言,这个问题不适合我们的问答形式。我们希望答案得到事实、引用资料或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visit the
当我注意到this answer时,我一直在阅读里氏替换原理。 。它有一个 Circle 和一个 ColoredCircle 类型,其中 ColoredCircle 的构造函数需要一个额外的参数; 颜
这段代码是否违反了DRY原则? if (notAuthorized) { return sendErrorCode(new ForbiddenException()) } else if (n
我在查询中使用 Doctrine 2 的结果缓存来检索用户(消息传递应用程序)的新消息数量: $query->useResultCache(true, 500, 'messaging.nb_new_m
关闭。这个问题需要多问focused 。目前不接受答案。 想要改进此问题吗?更新问题,使其仅关注一个问题 editing this post . 已关闭 8 年前。 Improve this ques
如何设置包含类名的变量,例如 android.util.Log 中的 TAG,同时尊重 Dont-Repeat-Yourself? 以下是一些可能性: 在 Google 代码中,它的常用用法如下 pu
我有以下查询: $roles = array(); $roles[] = 'ROLE_SUPER_ADMIN'; $roles[] = 'ROLE_ADMIN';
下面的代码违反了哪一条 SOLID 原则? public class A { void hello(){ //some code here } } public class B ext
我目前有一个 Message_Repository 类,它有如下方法: getLocationDetailsByID($messageId), getCustomerDetailsById($mess
我不知道它到底叫什么,但现在我将它称为“非空测试”。在 C# 8 中有一个新的行为允许测试一个对象是否不为空,例如: Foo foo = new Foo(); if(foo is { }) {
我正在学习 Doctrine。我在多对多关系中有两个实体 Article 和 Category,我正在尝试获取所有不是特定文章的类别。 文章实体: class Article extends Base
在阅读了一本书和一篇在线文章中有关 SOLID 代码的内容后,我想重构一个现有的类,使其与“SOLID”兼容。 但我想我迷路了,尤其是依赖注入(inject):当我想实例化类的一个对象时,我需要“注入
我的项目中有类似的东西,这个项目已经完成了(它正在运行)我只想知道 SOLID 原则是否可以接受 static public class Tools { static public GetPr

我是一名优秀的程序员,十分优秀!