
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


本文介绍基于 Python 语言中 TensorFlow 的 Keras 接口,实现深度神经网络回归的方法.
前期一篇文章 Python TensorFlow深度学习回归代码:DNNRegressor 详细介绍了基于 TensorFlow tf.estimator 接口的深度学习网络;而在 TensorFlow 2.0 中,新的 Keras 接口具有与 tf.estimator 接口一致的功能,且其更易于学习,对于新手而言友好程度更高;在 TensorFlow 官网也建议新手从 Keras 接口入手开始学习。因此,本文结合 TensorFlow Keras 接口,加以深度学习回归的详细介绍与代码实战.
和上述博客类似,本文第二部分为代码的分解介绍,第三部分为完整代码。一些在上述博客介绍过的内容,在本文中就省略了,大家如果有需要可以先查看上述文章 Python TensorFlow深度学习回归代码:DNNRegressor .
相关版本信息: Python 版本: 3.8.5 ; TensorFlow 版本: 2.4.1 ;编译器版本: Spyder 4.1.5 .
首先需要引入相关的库与包.
import os
import glob
import openpyxl
import numpy as np
import pandas as pd
import seaborn as sns
import tensorflow as tf
import scipy.stats as stats
import matplotlib.pyplot as plt
from sklearn import metrics
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import regularizers
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.layers.experimental import preprocessing
由于后续代码执行过程中,会有很多数据的展示与输出,其中多数数据都带有小数部分;为了让程序所显示的数据更为整齐、规范,我们可以对代码的浮点数、数组与 NumPy 对象对应的显示规则加以约束.
np.set_printoptions(precision=4,suppress=True)
其中, precision 设置小数点后显示的位数,默认为 8 ; suppress 表示是否使用定点计数法(即与科学计数法相对).
深度学习代码一大特点即为具有较多的参数需要我们手动定义。为避免调参时上下翻找,我们可以将主要的参数集中在一起,方便我们后期调整.
其中,具体参数的含义在本文后续部分详细介绍.
# Input parameters.
DataPath="G:/CropYield/03_DL/00_Data/AllDataAll.csv"
ModelPath="G:/CropYield/03_DL/02_DNNModle"
CheckPointPath="G:/CropYield/03_DL/02_DNNModle/Weights"
CheckPointName=CheckPointPath+"/Weights_{epoch:03d}_{val_loss:.4f}.hdf5"
ParameterPath="G:/CropYield/03_DL/03_OtherResult/ParameterResult.xlsx"
TrainFrac=0.8
RandomSeed=np.random.randint(low=21,high=22)
CheckPointMethod='val_loss'
HiddenLayer=[64,128,256,512,512,1024,1024]
RegularizationFactor=0.0001
ActivationMethod='relu'
DropoutValue=[0.5,0.5,0.5,0.3,0.3,0.3,0.2]
OutputLayerActMethod='linear'
LossMethod='mean_absolute_error'
LearnRate=0.005
LearnDecay=0.0005
FitEpoch=500
BatchSize=9999
ValFrac=0.2
BestEpochOptMethod='adam'
我的数据已经保存在了 .csv 文件中,因此可以用 pd.read_csv 直接读取.
其中,数据的每一列是一个特征,每一行是全部特征与因变量(就是下面的 Yield )组合成的样本.
# Fetch and divide data.
MyData=pd.read_csv(DataPath,names=['EVI0610','EVI0626','EVI0712','EVI0728','EVI0813','EVI0829',
'EVI0914','EVI0930','EVI1016','Lrad06','Lrad07','Lrad08',
'Lrad09','Lrad10','Prec06','Prec07','Prec08','Prec09',
'Prec10','Pres06','Pres07','Pres08','Pres09','Pres10',
'SIF161','SIF177','SIF193','SIF209','SIF225','SIF241',
'SIF257','SIF273','SIF289','Shum06','Shum07','Shum08',
'Shum09','Shum10','SoilType','Srad06','Srad07','Srad08',
'Srad09','Srad10','Temp06','Temp07','Temp08','Temp09',
'Temp10','Wind06','Wind07','Wind08','Wind09','Wind10',
'Yield'],header=0)
随后,对导入的数据划分训练集与测试集.
TrainData=MyData.sample(frac=TrainFrac,random_state=RandomSeed)
TestData=MyData.drop(TrainData.index)
其中, TrainFrac 为训练集(包括验证数据)所占比例, RandomSeed 为随即划分数据时所用的随机数种子.
在开始深度学习前,我们可以分别对输入数据的不同特征与因变量的关系加以查看。绘制联合分布图就是一种比较好的查看多个变量之间关系的方法。我们用 seaborn 来实现这一过程。 seaborn 是一个基于 matplotlib 的 Python 数据可视化库,使得我们可以通过较为简单的操作,绘制出动人的图片。代码如下:
# Draw the joint distribution image.
def JointDistribution(Factors):
plt.figure(1)
sns.pairplot(TrainData[Factors],kind='reg',diag_kind='kde')
sns.set(font_scale=2.0)
DataDistribution=TrainData.describe().transpose()
# Draw the joint distribution image.
JointFactor=['Lrad07','Prec06','SIF161','Shum06','Srad07','Srad08','Srad10','Temp06','Yield']
JointDistribution(JointFactor)
其中, JointFactor 为需要绘制联合分布图的特征名称, JointDistribution 函数中的 kind 表示联合分布图中非对角线图的类型,可选 'reg' 与 'scatter' 、 'kde' 、 'hist' , 'reg' 代表在图片中加入一条拟合直线, 'scatter' 就是不加入这条直线, 'kde' 是等高线的形式, 'hist' 就是类似于栅格地图的形式; diag_kind 表示联合分布图中对角线图的类型,可选 'hist' 与 'kde' , 'hist' 代表直方图, 'kde' 代表直方图曲线化。 font_scale 是图中的字体大小。 JointDistribution 函数中最后一句是用来展示 TrainData 中每一项特征数据的统计信息,包括最大值、最小值、平均值、分位数等.
图片绘制的示例如下:
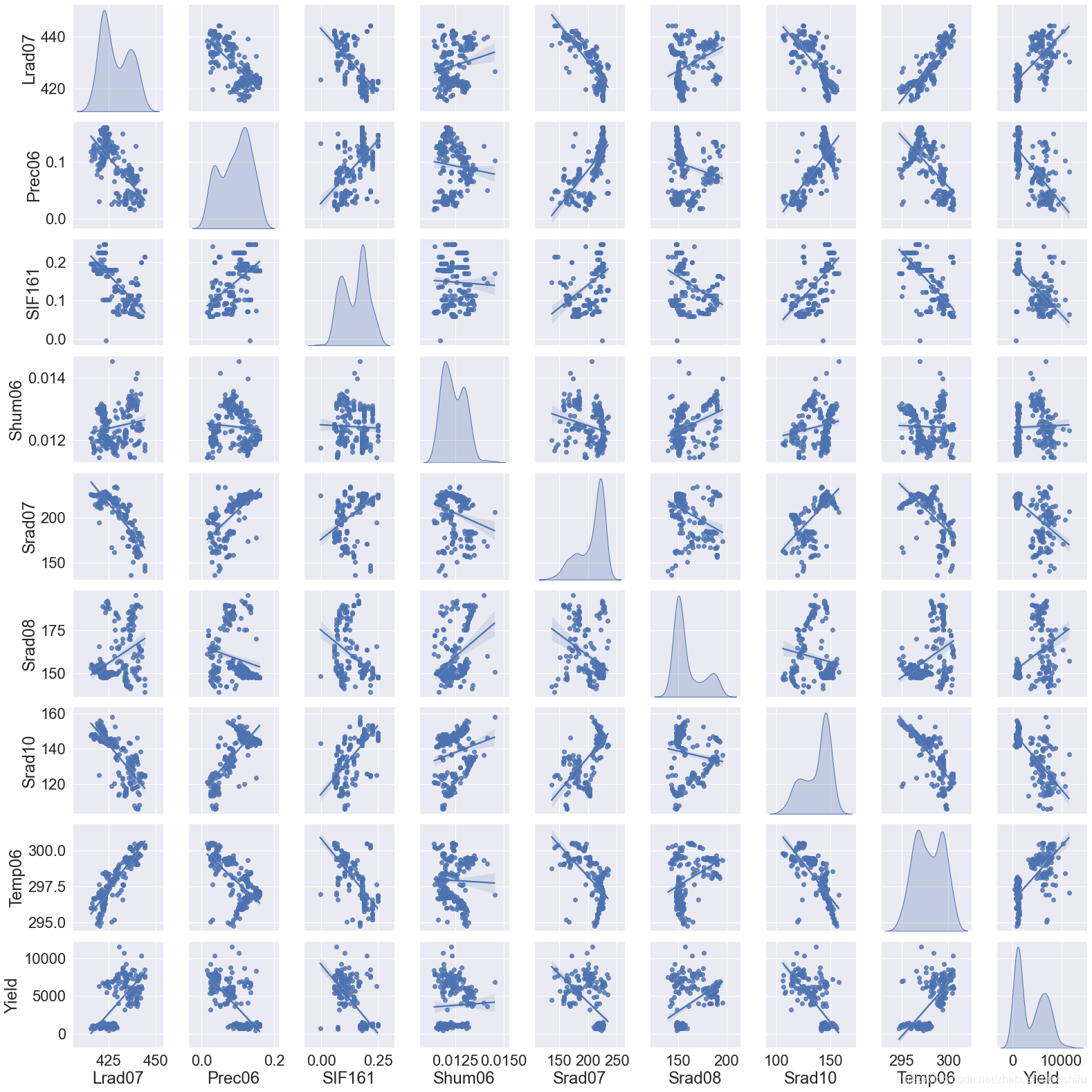
要注意,绘制联合分布图比较慢,建议大家不要选取太多的变量,否则程序会卡在这里比较长的时间.
因变量分离我们就不再多解释啦;接下来,我们要知道,对于机器学习、深度学习而言,数据标准化是十分重要的——用官网所举的一个例子:不同的特征在神经网络中会乘以相同的权重weight,因此输入数据的尺度(即数据不同特征之间的大小关系)将会影响到输出数据与梯度的尺度;因此,数据标准化可以使得模型更加稳定.
在这里,首先说明数据标准化与归一化的区别.
标准化即将训练集中某列的值缩放成均值为 0 ,方差为 1 的状态;而归一化是将训练集中某列的值缩放到 0 和 1 之间。而在机器学习中,标准化较之归一化通常具有更高的使用频率,且标准化后的数据在神经网络训练时,其收敛将会更快.
最后,一定要记得——标准化时只需要对训练集数据加以处理,不要把测试集 Test 的数据引入了!因为标准化只需要对训练数据加以处理,引入测试集反而会影响标准化的作用.
# Separate independent and dependent variables.
TrainX=TrainData.copy(deep=True)
TestX=TestData.copy(deep=True)
TrainY=TrainX.pop('Yield')
TestY=TestX.pop('Yield')
# Standardization data.
Normalizer=preprocessing.Normalization()
Normalizer.adapt(np.array(TrainX))
在这里,我们直接运用 preprocessing.Normalization() 建立一个预处理层,其具有数据标准化的功能;随后,通过 .adapt() 函数将需要标准化的数据(即训练集的自变量)放入这一层,便可以实现数据的标准化操作.
我们的程序每执行一次,便会在指定路径中保存当前运行的模型。为保证下一次模型保存时不受上一次模型运行结果干扰,我们可以将模型文件夹内的全部文件删除.
# Delete the model result from the last run.
def DeleteOldModel(ModelPath):
AllFileName=os.listdir(ModelPath)
for i in AllFileName:
NewPath=os.path.join(ModelPath,i)
if os.path.isdir(NewPath):
DeleteOldModel(NewPath)
else:
os.remove(NewPath)
# Delete the model result from the last run.
DeleteOldModel(ModelPath)
这一部分的代码在文章 Python TensorFlow深度学习回归代码:DNNRegressor 有详细的讲解,这里就不再重复.
在我们训练模型的过程中,会让模型运行几百个 Epoch (一个 Epoch 即全部训练集数据样本均进入模型训练一次);而由于每一次的 Epoch 所得到的精度都不一样,那么我们自然需要挑出几百个 Epoch 中最优秀的那一个 Epoch .
# Find and save optimal epoch.
def CheckPoint(Name):
Checkpoint=ModelCheckpoint(Name,
monitor=CheckPointMethod,
verbose=1,
save_best_only=True,
mode='auto')
CallBackList=[Checkpoint]
return CallBackList
# Find and save optimal epochs.
CallBack=CheckPoint(CheckPointName)
其中, Name 就是保存 Epoch 的路径与文件名命名方法; monitor 是我们挑选最优 Epoch 的依据,在这里我们用验证集数据对应的误差来判断这个 Epoch 是不是我们想要的; verbose 用来设置输出日志的内容,我们用 1 就好; save_best_only 用来确定我们是否只保存被认定为最优的 Epoch ; mode 用以判断我们的 monitor 是越大越好还是越小越好,前面提到了我们的 monitor 是验证集数据对应的误差,那么肯定是误差越小越好,所以这里可以用 'auto' 或 'min' ,其中 'auto' 是模型自己根据用户选择的 monitor 方法来判断越大越好还是越小越好.
找到最优 Epoch 后,将其传递给 CallBack 。需要注意的是,这里的最优 Epoch 是多个 Epoch ——因为每一次 Epoch 只要获得了当前模型所遇到的最优解,它就会保存;下一次再遇见一个更好的解时,同样保存,且不覆盖上一次的 Epoch 。可以这么理解,假如一共有三次 Epoch ,所得到的误差分别为 5 , 7 , 4 ;那么我们保存的 Epoch 就是第一次和第三次.
Keras 接口下的模型构建就很清晰明了了。相信大家在看了前期一篇文章 Python TensorFlow深度学习回归代码:DNNRegressor 后,结合代码旁的注释就理解啦.
# Build DNN model.
def BuildModel(Norm):
Model=keras.Sequential([Norm, # 数据标准化层
layers.Dense(HiddenLayer[0], # 指定隐藏层1的神经元个数
kernel_regularizer=regularizers.l2(RegularizationFactor), # 运用L2正则化
# activation=ActivationMethod
),
layers.LeakyReLU(), # 引入LeakyReLU这一改良的ReLU激活函数,从而加快模型收敛,减少过拟合
layers.BatchNormalization(), # 引入Batch Normalizing,加快网络收敛与增强网络稳固性
layers.Dropout(DropoutValue[0]), # 指定隐藏层1的Dropout值
layers.Dense(HiddenLayer[1],
kernel_regularizer=regularizers.l2(RegularizationFactor),
# activation=ActivationMethod
),
layers.LeakyReLU(),
layers.BatchNormalization(),
layers.Dropout(DropoutValue[1]),
layers.Dense(HiddenLayer[2],
kernel_regularizer=regularizers.l2(RegularizationFactor),
# activation=ActivationMethod
),
layers.LeakyReLU(),
layers.BatchNormalization(),
layers.Dropout(DropoutValue[2]),
layers.Dense(HiddenLayer[3],
kernel_regularizer=regularizers.l2(RegularizationFactor),
# activation=ActivationMethod
),
layers.LeakyReLU(),
layers.BatchNormalization(),
layers.Dropout(DropoutValue[3]),
layers.Dense(HiddenLayer[4],
kernel_regularizer=regularizers.l2(RegularizationFactor),
# activation=ActivationMethod
),
layers.LeakyReLU(),
layers.BatchNormalization(),
layers.Dropout(DropoutValue[4]),
layers.Dense(HiddenLayer[5],
kernel_regularizer=regularizers.l2(RegularizationFactor),
# activation=ActivationMethod
),
layers.LeakyReLU(),
layers.BatchNormalization(),
layers.Dropout(DropoutValue[5]),
layers.Dense(HiddenLayer[6],
kernel_regularizer=regularizers.l2(RegularizationFactor),
# activation=ActivationMethod
),
layers.LeakyReLU(),
# If batch normalization is set in the last hidden layer, the error image
# will show a trend of first stable and then decline; otherwise, it will
# decline and then stable.
# layers.BatchNormalization(),
layers.Dropout(DropoutValue[6]),
layers.Dense(units=1,
activation=OutputLayerActMethod)]) # 最后一层就是输出层
Model.compile(loss=LossMethod, # 指定每个批次训练误差的减小方法
optimizer=tf.keras.optimizers.Adam(learning_rate=LearnRate,decay=LearnDecay))
# 运用学习率下降的优化方法
return Model
# Build DNN regression model.
DNNModel=BuildModel(Normalizer)
DNNModel.summary()
DNNHistory=DNNModel.fit(TrainX,
TrainY,
epochs=FitEpoch,
# batch_size=BatchSize,
verbose=1,
callbacks=CallBack,
validation_split=ValFrac)
在这里, .summary() 查看模型摘要, validation_split 为在训练数据中,取出 ValFrac 所指定比例的一部分作为验证数据。 DNNHistory 则记录了模型训练过程中的各类指标变化情况,接下来我们可以基于其绘制模型训练过程的误差变化图像.
机器学习中,过拟合是影响训练精度的重要因素。因此,我们最好在训练模型的过程中绘制训练数据、验证数据的误差变化图象,从而更好获取模型的训练情况.
# Draw error image.
def LossPlot(History):
plt.figure(2)
plt.plot(History.history['loss'],label='loss')
plt.plot(History.history['val_loss'],label='val_loss')
plt.ylim([0,4000])
plt.xlabel('Epoch')
plt.ylabel('Error')
plt.legend()
plt.grid(True)
# Draw error image.
LossPlot(DNNHistory)
其中, 'loss' 与 'val_loss' 分别是模型训练过程中,训练集、验证集对应的误差;如果训练集误差明显小于验证集误差,就说明模型出现了过拟合.
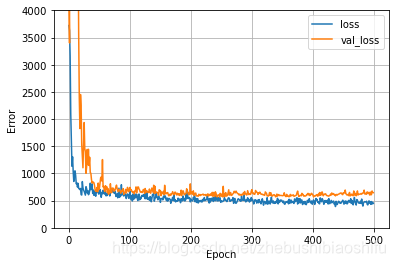
前面提到了,我们将多个符合要求的 Epoch 保存在了指定的路径下,那么最终我们可以从中选取最好的那个 Epoch ,作为模型的最终参数,从而对测试集数据加以预测。那么在这里,我们需要将这一全局最优 Epoch 选取出,并带入到最终的模型里.
# Optimize the model based on optimal epoch.
def BestEpochIntoModel(Path,Model):
EpochFile=glob.glob(Path+'/*')
BestEpoch=max(EpochFile,key=os.path.getmtime)
Model.load_weights(BestEpoch)
Model.compile(loss=LossMethod,
optimizer=BestEpochOptMethod)
return Model
# Optimize the model based on optimal epoch.
DNNModel=BestEpochIntoModel(CheckPointPath,DNNModel)
总的来说,这里就是运用了 os.path.getmtime 模块,将我们存储 Epoch 的文件夹中最新的那个 Epoch 挑出来——这一 Epoch 就是使得验证集数据误差最小的全局最优 Epoch ;并通过 load_weights 将这一 Epoch 对应的模型参数引入模型.
前期一篇文章 Python TensorFlow深度学习回归代码:DNNRegressor 中有相关的代码讲解内容,因此这里就不再赘述啦.
# Draw Test image.
def TestPlot(TestY,TestPrediction):
plt.figure(3)
ax=plt.axes(aspect='equal')
plt.scatter(TestY,TestPrediction)
plt.xlabel('True Values')
plt.ylabel('Predictions')
Lims=[0,10000]
plt.xlim(Lims)
plt.ylim(Lims)
plt.plot(Lims,Lims)
plt.grid(False)
# Verify the accuracy and draw error hist image.
def AccuracyVerification(TestY,TestPrediction):
DNNError=TestPrediction-TestY
plt.figure(4)
plt.hist(DNNError,bins=30)
plt.xlabel('Prediction Error')
plt.ylabel('Count')
plt.grid(False)
Pearsonr=stats.pearsonr(TestY,TestPrediction)
R2=metrics.r2_score(TestY,TestPrediction)
RMSE=metrics.mean_squared_error(TestY,TestPrediction)**0.5
print('Pearson correlation coefficient is {0}, and RMSE is {1}.'.format(Pearsonr[0],RMSE))
return (Pearsonr[0],R2,RMSE)
# Save key parameters.
def WriteAccuracy(*WriteVar):
ExcelData=openpyxl.load_workbook(WriteVar[0])
SheetName=ExcelData.get_sheet_names()
WriteSheet=ExcelData.get_sheet_by_name(SheetName[0])
WriteSheet=ExcelData.active
MaxRowNum=WriteSheet.max_row
for i in range(len(WriteVar)-1):
exec("WriteSheet.cell(MaxRowNum+1,i+1).value=WriteVar[i+1]")
ExcelData.save(WriteVar[0])
# Predict test set data.
TestPrediction=DNNModel.predict(TestX).flatten()
# Draw Test image.
TestPlot(TestY,TestPrediction)
# Verify the accuracy and draw error hist image.
AccuracyResult=AccuracyVerification(TestY,TestPrediction)
PearsonR,R2,RMSE=AccuracyResult[0],AccuracyResult[1],AccuracyResult[2]
# Save model and key parameters.
DNNModel.save(ModelPath)
WriteAccuracy(ParameterPath,PearsonR,R2,RMSE,TrainFrac,RandomSeed,CheckPointMethod,
','.join('%s' %i for i in HiddenLayer),RegularizationFactor,
ActivationMethod,','.join('%s' %i for i in DropoutValue),OutputLayerActMethod,
LossMethod,LearnRate,LearnDecay,FitEpoch,BatchSize,ValFrac,BestEpochOptMethod)
得到拟合图像如下:
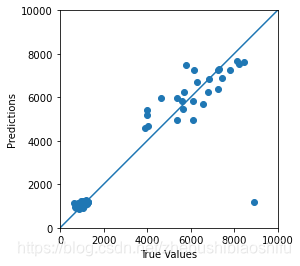
得到误差分布直方图如下:
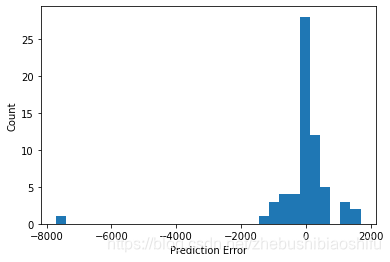
至此,代码的分解介绍就结束啦~ 。
# -*- coding: utf-8 -*-
"""
Created on Tue Feb 24 12:42:17 2021
@author: fkxxgis
"""
import os
import glob
import openpyxl
import numpy as np
import pandas as pd
import seaborn as sns
import tensorflow as tf
import scipy.stats as stats
import matplotlib.pyplot as plt
from sklearn import metrics
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import regularizers
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.layers.experimental import preprocessing
np.set_printoptions(precision=4,suppress=True)
# Draw the joint distribution image.
def JointDistribution(Factors):
plt.figure(1)
sns.pairplot(TrainData[Factors],kind='reg',diag_kind='kde')
sns.set(font_scale=2.0)
DataDistribution=TrainData.describe().transpose()
# Delete the model result from the last run.
def DeleteOldModel(ModelPath):
AllFileName=os.listdir(ModelPath)
for i in AllFileName:
NewPath=os.path.join(ModelPath,i)
if os.path.isdir(NewPath):
DeleteOldModel(NewPath)
else:
os.remove(NewPath)
# Find and save optimal epoch.
def CheckPoint(Name):
Checkpoint=ModelCheckpoint(Name,
monitor=CheckPointMethod,
verbose=1,
save_best_only=True,
mode='auto')
CallBackList=[Checkpoint]
return CallBackList
# Build DNN model.
def BuildModel(Norm):
Model=keras.Sequential([Norm, # 数据标准化层
layers.Dense(HiddenLayer[0], # 指定隐藏层1的神经元个数
kernel_regularizer=regularizers.l2(RegularizationFactor), # 运用L2正则化
# activation=ActivationMethod
),
layers.LeakyReLU(), # 引入LeakyReLU这一改良的ReLU激活函数,从而加快模型收敛,减少过拟合
layers.BatchNormalization(), # 引入Batch Normalizing,加快网络收敛与增强网络稳固性
layers.Dropout(DropoutValue[0]), # 指定隐藏层1的Dropout值
layers.Dense(HiddenLayer[1],
kernel_regularizer=regularizers.l2(RegularizationFactor),
# activation=ActivationMethod
),
layers.LeakyReLU(),
layers.BatchNormalization(),
layers.Dropout(DropoutValue[1]),
layers.Dense(HiddenLayer[2],
kernel_regularizer=regularizers.l2(RegularizationFactor),
# activation=ActivationMethod
),
layers.LeakyReLU(),
layers.BatchNormalization(),
layers.Dropout(DropoutValue[2]),
layers.Dense(HiddenLayer[3],
kernel_regularizer=regularizers.l2(RegularizationFactor),
# activation=ActivationMethod
),
layers.LeakyReLU(),
layers.BatchNormalization(),
layers.Dropout(DropoutValue[3]),
layers.Dense(HiddenLayer[4],
kernel_regularizer=regularizers.l2(RegularizationFactor),
# activation=ActivationMethod
),
layers.LeakyReLU(),
layers.BatchNormalization(),
layers.Dropout(DropoutValue[4]),
layers.Dense(HiddenLayer[5],
kernel_regularizer=regularizers.l2(RegularizationFactor),
# activation=ActivationMethod
),
layers.LeakyReLU(),
layers.BatchNormalization(),
layers.Dropout(DropoutValue[5]),
layers.Dense(HiddenLayer[6],
kernel_regularizer=regularizers.l2(RegularizationFactor),
# activation=ActivationMethod
),
layers.LeakyReLU(),
# If batch normalization is set in the last hidden layer, the error image
# will show a trend of first stable and then decline; otherwise, it will
# decline and then stable.
# layers.BatchNormalization(),
layers.Dropout(DropoutValue[6]),
layers.Dense(units=1,
activation=OutputLayerActMethod)]) # 最后一层就是输出层
Model.compile(loss=LossMethod, # 指定每个批次训练误差的减小方法
optimizer=tf.keras.optimizers.Adam(learning_rate=LearnRate,decay=LearnDecay))
# 运用学习率下降的优化方法
return Model
# Draw error image.
def LossPlot(History):
plt.figure(2)
plt.plot(History.history['loss'],label='loss')
plt.plot(History.history['val_loss'],label='val_loss')
plt.ylim([0,4000])
plt.xlabel('Epoch')
plt.ylabel('Error')
plt.legend()
plt.grid(True)
# Optimize the model based on optimal epoch.
def BestEpochIntoModel(Path,Model):
EpochFile=glob.glob(Path+'/*')
BestEpoch=max(EpochFile,key=os.path.getmtime)
Model.load_weights(BestEpoch)
Model.compile(loss=LossMethod,
optimizer=BestEpochOptMethod)
return Model
# Draw Test image.
def TestPlot(TestY,TestPrediction):
plt.figure(3)
ax=plt.axes(aspect='equal')
plt.scatter(TestY,TestPrediction)
plt.xlabel('True Values')
plt.ylabel('Predictions')
Lims=[0,10000]
plt.xlim(Lims)
plt.ylim(Lims)
plt.plot(Lims,Lims)
plt.grid(False)
# Verify the accuracy and draw error hist image.
def AccuracyVerification(TestY,TestPrediction):
DNNError=TestPrediction-TestY
plt.figure(4)
plt.hist(DNNError,bins=30)
plt.xlabel('Prediction Error')
plt.ylabel('Count')
plt.grid(False)
Pearsonr=stats.pearsonr(TestY,TestPrediction)
R2=metrics.r2_score(TestY,TestPrediction)
RMSE=metrics.mean_squared_error(TestY,TestPrediction)**0.5
print('Pearson correlation coefficient is {0}, and RMSE is {1}.'.format(Pearsonr[0],RMSE))
return (Pearsonr[0],R2,RMSE)
# Save key parameters.
def WriteAccuracy(*WriteVar):
ExcelData=openpyxl.load_workbook(WriteVar[0])
SheetName=ExcelData.get_sheet_names()
WriteSheet=ExcelData.get_sheet_by_name(SheetName[0])
WriteSheet=ExcelData.active
MaxRowNum=WriteSheet.max_row
for i in range(len(WriteVar)-1):
exec("WriteSheet.cell(MaxRowNum+1,i+1).value=WriteVar[i+1]")
ExcelData.save(WriteVar[0])
# Input parameters.
DataPath="G:/CropYield/03_DL/00_Data/AllDataAll.csv"
ModelPath="G:/CropYield/03_DL/02_DNNModle"
CheckPointPath="G:/CropYield/03_DL/02_DNNModle/Weights"
CheckPointName=CheckPointPath+"/Weights_{epoch:03d}_{val_loss:.4f}.hdf5"
ParameterPath="G:/CropYield/03_DL/03_OtherResult/ParameterResult.xlsx"
TrainFrac=0.8
RandomSeed=np.random.randint(low=21,high=22)
CheckPointMethod='val_loss'
HiddenLayer=[64,128,256,512,512,1024,1024]
RegularizationFactor=0.0001
ActivationMethod='relu'
DropoutValue=[0.5,0.5,0.5,0.3,0.3,0.3,0.2]
OutputLayerActMethod='linear'
LossMethod='mean_absolute_error'
LearnRate=0.005
LearnDecay=0.0005
FitEpoch=500
BatchSize=9999
ValFrac=0.2
BestEpochOptMethod='adam'
# Fetch and divide data.
MyData=pd.read_csv(DataPath,names=['EVI0610','EVI0626','EVI0712','EVI0728','EVI0813','EVI0829',
'EVI0914','EVI0930','EVI1016','Lrad06','Lrad07','Lrad08',
'Lrad09','Lrad10','Prec06','Prec07','Prec08','Prec09',
'Prec10','Pres06','Pres07','Pres08','Pres09','Pres10',
'SIF161','SIF177','SIF193','SIF209','SIF225','SIF241',
'SIF257','SIF273','SIF289','Shum06','Shum07','Shum08',
'Shum09','Shum10','SoilType','Srad06','Srad07','Srad08',
'Srad09','Srad10','Temp06','Temp07','Temp08','Temp09',
'Temp10','Wind06','Wind07','Wind08','Wind09','Wind10',
'Yield'],header=0)
TrainData=MyData.sample(frac=TrainFrac,random_state=RandomSeed)
TestData=MyData.drop(TrainData.index)
# Draw the joint distribution image.
# JointFactor=['Lrad07','Prec06','SIF161','Shum06','Srad07','Srad08','Srad10','Temp06','Yield']
# JointDistribution(JointFactor)
# Separate independent and dependent variables.
TrainX=TrainData.copy(deep=True)
TestX=TestData.copy(deep=True)
TrainY=TrainX.pop('Yield')
TestY=TestX.pop('Yield')
# Standardization data.
Normalizer=preprocessing.Normalization()
Normalizer.adapt(np.array(TrainX))
# Delete the model result from the last run.
DeleteOldModel(ModelPath)
# Find and save optimal epochs.
CallBack=CheckPoint(CheckPointName)
# Build DNN regression model.
DNNModel=BuildModel(Normalizer)
DNNModel.summary()
DNNHistory=DNNModel.fit(TrainX,
TrainY,
epochs=FitEpoch,
# batch_size=BatchSize,
verbose=1,
callbacks=CallBack,
validation_split=ValFrac)
# Draw error image.
LossPlot(DNNHistory)
# Optimize the model based on optimal epoch.
DNNModel=BestEpochIntoModel(CheckPointPath,DNNModel)
# Predict test set data.
TestPrediction=DNNModel.predict(TestX).flatten()
# Draw Test image.
TestPlot(TestY,TestPrediction)
# Verify the accuracy and draw error hist image.
AccuracyResult=AccuracyVerification(TestY,TestPrediction)
PearsonR,R2,RMSE=AccuracyResult[0],AccuracyResult[1],AccuracyResult[2]
# Save model and key parameters.
DNNModel.save(ModelPath)
WriteAccuracy(ParameterPath,PearsonR,R2,RMSE,TrainFrac,RandomSeed,CheckPointMethod,
','.join('%s' %i for i in HiddenLayer),RegularizationFactor,
ActivationMethod,','.join('%s' %i for i in DropoutValue),OutputLayerActMethod,
LossMethod,LearnRate,LearnDecay,FitEpoch,BatchSize,ValFrac,BestEpochOptMethod)
至此,大功告成.
最后此篇关于PythonTensorFlow深度神经网络回归:keras.Sequential的文章就讲到这里了,如果你想了解更多关于PythonTensorFlow深度神经网络回归:keras.Sequential的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
这与 Payubiz payment gateway sdk 关系不大一体化。但是,主要问题与构建项目有关。 每当我们尝试在模拟器上运行应用程序时。我们得到以下失败: What went wrong:
我有一个现有的应用程序,其中包含在同一主机上运行的 4 个 docker 容器。它们已使用 link 命令链接在一起。 然而,在 docker 升级后,link 行为已被弃用,并且似乎有所改变。我们现
在 Internet 模型中有四层:链路 -> 网络 -> 传输 -> 应用程序。 我真的不知道网络层和传输层之间的区别。当我读到: Transport layer: include congesti
很难说出这里要问什么。这个问题模棱两可、含糊不清、不完整、过于宽泛或夸夸其谈,无法以目前的形式得到合理的回答。如需帮助澄清此问题以便重新打开,visit the help center . 关闭 1
前言: 生活中,我们在上网时,打开一个网页,就可以看到网址,如下: https😕/xhuahua.blog.csdn.net/ 访问网站使用的协议类型:https(基于 http 实现的,只不过在
网络 避免网络问题降低Hadoop和HBase性能的最重要因素可能是所使用的交换硬件,在项目范围的早期做出的决策可能会导致群集大小增加一倍或三倍(或更多)时出现重大问题。 需要考虑的重要事项:
网络 网络峰值 如果您看到定期的网络峰值,您可能需要检查compactionQueues以查看主要压缩是否正在发生。 有关管理压缩的更多信息,请参阅管理压缩部分的内容。 Loopback IP
Pure Data 有一个 loadbang 组件,它按照它说的做:当图形开始运行时发送一个 bang。 NoFlo 的 core/Kick 在其 IN 输入被击中之前不会发送其数据,并且您无法在 n
我有一台 Linux 构建机器,我也安装了 minikube。在 minikube 实例中,我安装了 artifactory,我将使用它来存储各种构建工件 我现在希望能够在我的开发机器上做一些工作(这
我想知道每个视频需要多少种不同的格式才能支持所有主要设备? 在我考虑的主要设备中:安卓手机 + iPhone + iPad . 对具有不同比特率的视频进行编码也是一种好习惯吗? 那里有太多相互矛盾的信
我有一个使用 firebase 的 Flutter Web 应用程序,我有两个 firebase 项目(dev 和 prod)。 我想为这个项目设置 Flavors(只是网络没有移动)。 在移动端,我
我正在读这篇文章Ars article关于密码安全,它提到有一些网站“在传输之前对密码进行哈希处理”? 现在,假设这不使用 SSL 连接 (HTTPS),a.这真的安全吗? b.如果是的话,你会如何在
我试图了解以下之间的关系: eth0在主机上;和 docker0桥;和 eth0每个容器上的接口(interface) 据我了解,Docker: 创建一个 docker0桥接,然后为其分配一个与主机上
我需要编写一个java程序,通过网络将对象发送到客户端程序。问题是一些需要发送的对象是不可序列化的。如何最好地解决这个问题? 最佳答案 发送在客户端重建对象所需的数据。 关于java - 不可序列化对
所以我最近关注了this有关用 Java 制作基本聊天室的教程。它使用多线程,是一个“面向连接”的服务器。我想知道如何使用相同的 Sockets 和 ServerSockets 来发送对象的 3d 位
我想制作一个系统,其中java客户端程序将图像发送到中央服务器。中央服务器保存它们并运行使用这些图像的网站。 我应该如何发送图像以及如何接收它们?我可以使用同一个网络服务器来接收和显示网站吗? 最佳答
我正在尝试设置我的 rails 4 应用程序,以便它发送电子邮件。有谁知道我为什么会得到: Net::SMTPAuthenticationError 534-5.7.9 Application-spe
我正在尝试编写一个简单的客户端-服务器程序,它将客户端计算机连接到服务器计算机。 到目前为止,我的代码在本地主机上运行良好,但是当我将客户端代码中的 IP 地址替换为服务器计算机的本地 IP 地址时,
我需要在服务器上并行启动多个端口,并且所有服务器套接字都应在 socket.accept() 上阻塞。 同一个线程需要启动客户端套接字(许多)来连接到特定的 ServerSocket。 这能实现吗?
我的工作执行了大约 10000 次以下任务: 1) HTTP 请求(1 秒) 2)数据转换(0.3秒) 3)数据库插入(0.7秒) 每次迭代的总时间约为 2 秒,分布如上所述。 我想做多任务处理,但我

我是一名优秀的程序员,十分优秀!