
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4


本文将通过一个 NodeJS 程序里无效的错误捕获示例,来讲解错误捕获里常见的陷阱。错误捕获不是凭感觉添加 try catch 语句,它的首要目的是提供有效的错误排查信息,只有精心设计的错误捕获才有可能完成这个使命。针对哪些方面去精心设计就是本篇文章里想讨论的内容 。
实战系列来自于个人开发以及运维 site2share 网站过程中的经验 。
为什么代码里需要 try catch?是为了阻止 bug 的发生的?当然不是,bug 其实是代码的副产品,bug 的数量取决于代码的质量而非 try catch 的数量.
说到底 try catch 只是用来查漏补缺的工具,如果你把 try catch 只是当作万能的膏药在代码里想贴就贴,那你可能多半贴不中真正的要害,也得不到期望的结果 。
在 site2share 中我需要集成 Redis 用于存储用户的 session 信息,自然需要在代码中使用第三方类库使用 Redis,无论是 node-redis (还是 ioredis),它们都提供事件机制用于反馈与 Redis Server 连接的当前状态。比如我们可以监听 error 事件
redis.on('error', function () { });
为什么不监听看看呢。并且上线之后如偿所愿,在发现网站无法访问之后在日志中确实找到了 。

但它们统统都仅是 node-redis 类库内部的函数调用栈,我发现这些信息对我来说毫无用处,因为它们无法向我提供最关键的一类信息: 上下文 。所以这些信息都只是在告诉我在访问 /api/folder/:id 时 redis 出现了报错,然而下列这些问题的答案才更有助于我排查问题:
对于这些问题的答案我一无所知,更艰难的是我无法在本地开发环境中复现该错误。这个时候我才发现并非你收集的信息越多,你把问题解决的概率就越大,如果你始终缺失某条关键信息,再多的额外信息也于事无补.
这又回到了我之前所说的 信息应该是双向的 ,即我收集的信息务必让我有采取行动和回溯的能力 。
所以捕获错误同样需要设计。或者退一步说,即使我不太确定错误会在哪里发生而需要在大范围内对错误进行捕获,也需要保证错误要提供有效信息:
再退一步说,如果无法得到直接有效信息,间接的有效信息也是可以接受的,例如你可以利用服务供应商或者基础设施的自带日志来协助排查问题;再不济如果只能硬着头皮阅读代码的话,被精心设计的函数名也非常重要.
那么如何设计好的 try catch呢?看起来你需要懂你的函数,你需要知道它可能的输入和期待的输出是什么,你需要知道它在执行过程中会和哪些服务打交道,你需要知道它的风险在哪。很有意思的是,我们从函数出发,想尽可能完美地捕获报错,但完美的答案又在函数本身当中.
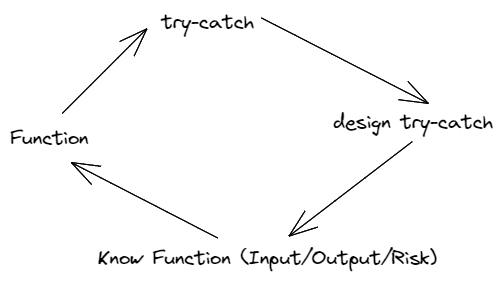
最后,如果程序在意料之外挂掉或者抛错,顺其自然好了。千万不要想法设法当作什么事情都没有发生然后继续执行下去。因为我们无法得知错误究竟带来的影响是什么,会带来怎样的连锁反应。抱有侥幸心理不如就此止损——请快速失败,快速恢复 。
说实话我很难找到关于 handle error 设计方面的书籍或者文章,很惊讶这块领域内的空白(我都能找到 好几本 聊 依赖注入 的 图书 )。当你在读技术教程比如 《.NET Core in Action》 或者 《ASP.NET MVC 4 in Action》 时,它们只会告诉你在框架中存在这样或者那样的 error handling 机制,至于如何使用才是最佳实践,并不在它们的范畴内.
为什么用“接住”而非“抓住”,是因为前者是被动后者是主动的,大部分情况下你都不太可能主动的、预测性的识别到某个bug。但我们不能因为如此就任由它们发生,我们需要:
在处理这些事物方面,我们需要集中化处理错误,目前绝大部分框架都支持这类操作。比如对于 .NET CORE 来说,我们可以通过在最外层添加 middleware 来解决这个问题 。
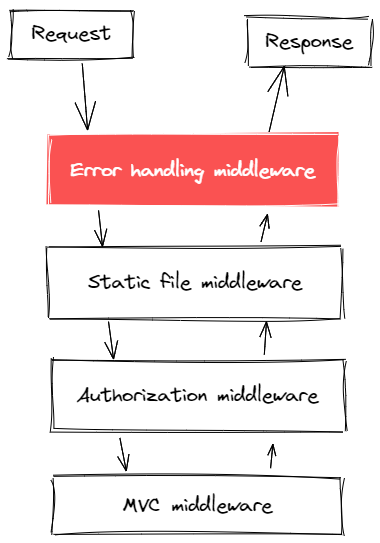
error handing middleare 只能作为程序处理错误的最后一道防线,对于不可知的错误尤其有效。然而对于一些可以前置,可以提前捕获的错误来说,我们又应该如何处理呢?
我的经验是,需要在系统内建立一套机制或者说通道,让 exception 按照指定的方向高效的流动起来才是首要任务。举个例子 。
try {
await getUserInfo()
} catch(e) {
throw new LoadUserInfoException()
}
第一个问题是,我们是否真的需要 try catch?不一定,理想情况下即使错误在当前代码块没有被捕获,它发生的意外错误也应该掉落进最后一道防线中,然后翻译为能够暴露给外部的信息,随后程序立即中断,快速重启.
退一步说,即使你按照以上代码有意进行 catch,你要如何处理这个新 throw 出来的错误呢?最好的办法是我们无需关心。LoadUserInfoException 中可以事先定义这个错误的状态吗的 message,上面所说的程序中提前建立好的机制,会自动将这个错误按照状态码和message进行翻译,返回给客户端。并非所有场景都需要有意屏蔽错误信息,有时候将恰当的错误信息返回给客户端能够让用户自主的排查问题更好.
上面涉及的自动捕获、对错误进行翻译、直达客户端,以及你能够想到的跨功能需求,比如收集错误日志,都应该是程序中的基础设施,具体的开发人员无需关心,无需对于每一个错误都手动执行这一系列步骤.
正如下图所示,无论你的 controller、service、SDK 之间的调用层次如何,各个模块中被抛出的异常都一视同仁的被处理。然而开发人员只需要关心下图左上方的部分,至于错误信息如何向右流向客户端,则无需关心 。
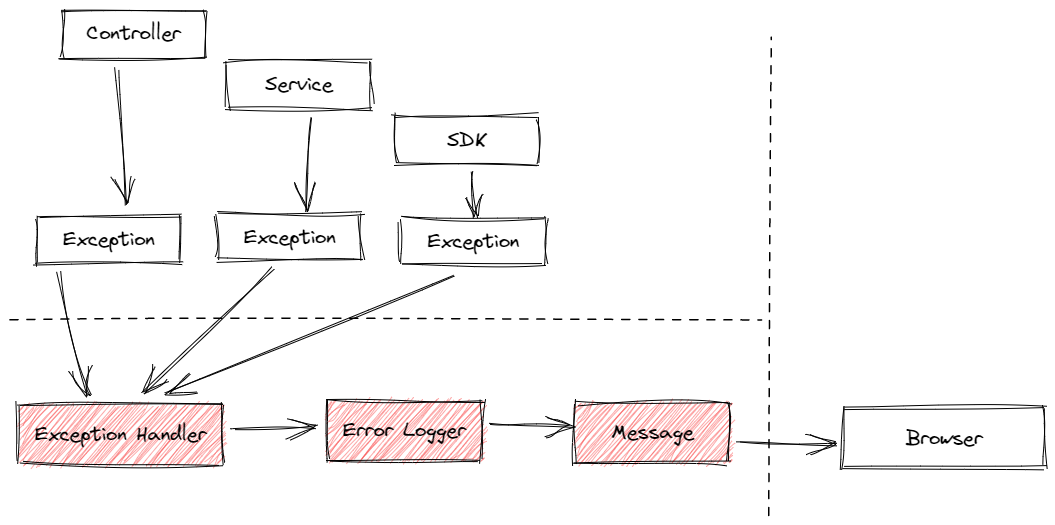
.NET Core 里的 middleware 和 NodeJS 里的 error handler 都能可以达到这个效果 。
你也可以通过 知乎 和 我的个人网站 访问这篇文章 。
最后此篇关于NodeJS实战系列:如何设计trycatch的文章就讲到这里了,如果你想了解更多关于NodeJS实战系列:如何设计trycatch的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
考虑以下代码: test1 print(test1) [1] "b" > print(test2) [1] "b" 最佳答案 '<<-' 是为不属于 R 的副作用而设计的。永远不要使用它,或者只有在
我正在编写一个函数,该函数使用 kmeans 来确定 bin 宽度,以将连续测量值(预测概率)转换为整数(3 个 bin 之一)。我偶然发现了一个边缘情况,在这种情况下,我的算法可以(正确)预测整个集
我注意到 tryCatch 没有正确捕获以下错误:它不打印 TRUE,并且它不转到浏览器... 它可能是 tryCatch 函数中的错误吗? library(formattable) df1 = st
我对 R 很陌生,我对 tryCatch 的正确用法感到困惑.我的目标是对大型数据集进行预测。如果预测不适合内存,我想通过拆分我的数据来规避这个问题。 现在,我的代码大致如下: tryCatch({
myFunc <- function(x) { x <- timeSeries(x, charvec=as.Date(index(x))) t<-tryCatch( doSomething(
我尝试连接 2 个数据框:Eset2 和 Essential。它们共享 1 个包含基因名称的公共(public)列,并且两个框架都有唯一的行。 所以我决定在 Eset2 中查找我需要的值(RMA,AN
我想知道这是检查 tryCatch 函数类型的错误或警告的方法,例如在 Java 中。 try { driver.findElement(By.xpath(locator)).
我正在尝试使用 tryCatch 生成 p 值列表,矩阵中有几行没有足够的观察值来进行 t 检验。这是我到目前为止生成的代码: pValues <- c() for(i in row.names(co
我有一个 1000 行的数据框。我想要循环的代码非常简单 - 我只想将第 4 列中的所有值设为大写。我希望它能够在任何行中出现错误时跳过该行并继续执行其余行。 我写了这段代码: for(i in 1:
我有一段代码,其中使用 for 循环读取和分析文件列表。由于我必须分析多个文件,因此我想使用 tryCatch 来打印引发问题的文件的名称。我的文件的一个常见问题是缺少列名,我的意思是,它应该在文件中
这将输出“未发现错误!”两次, x .8) stop("oops") TRUE } g = function() { ## on error, warn user but contin
我正在解析大量网站并编写了一个脚本,该脚本循环遍历来自单独文件的数千个链接。但是,我遇到过有时 R 无法加载一个链接,它会在循环中间停止,从而导致许多其他 url 无法解析。所以我尝试使用 tryCa
我有一个 1000 行的数据框。我想要循环的代码非常简单 - 我只想将第 4 列中的所有值设为大写。我希望它能够在任何行中出现错误时跳过该行并继续执行其余行。 我写了这段代码: for(i in 1:
我正在使用 tryCatch捕捉发生的任何错误。但是,即使我捕获它们并返回适当的错误值,看起来我的批处理系统的日志中仍然报告错误。有没有办法完全抑制错误并简单地继续我提供的错误处理? 最佳答案 确保您
我有一段代码,其中使用 for 循环读取和分析文件列表。由于我必须分析多个文件,因此我想使用 tryCatch 来打印引发问题的文件的名称。我的文件的一个常见问题是缺少列名,我的意思是,它应该在文件中
import org.newdawn.slick.Image; import org.newdawn.slick.SlickException; public class Images { t
下面的tryCatch装饰器无法捕捉到错误。 const TryCatchWrapper = (target, key, descriptor) => { const fn = descripto
我在排列数据上运行 GLMM,对于其中一些我有收敛的错误消息。 由于这是我的空模型,我只需要重新采样这个特定的排列数据。 因此,我试图处理 R 的 tryCatch 函数,但我有一些失败。 我有 Pe
我试图在 for 循环中处理两个可能的错误,它调用 stplanr::dist_google与 API 交互。我知道错误,所以我想在它们发生时采取具体的行动。 如果我尝试仅处理可能的错误之一,它会起作
我有一个函数: buggy buggy() Error in tryCatchList(expr, classes, parentenv, handlers) : I don't like gr

我是一名优秀的程序员,十分优秀!