
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 27
27
 4
4


深度学习是机器学习的一个特定分支 。 我们要想充分理解深度学习,必须对机器学习的基本原理有深刻的理解 .
大部分机器学习算法都有 超参数 (必须在学习算法外 手动设定 )。 机器学习本质上属于应用统计学 ,其更加强调使用计算机对复杂函数进行 统计估计 ,而较少强调围绕这些函数证明置信区间;因此我们会探讨两种统计学的主要方法: 频率派估计和贝叶斯推断 。同时,大部分机器学习算法又可以分成 监督学习 和 无监督学习 两类;本文会介绍这两类算法定义,并给出每个类别中一些算法示例.
本章内容还会介绍如何组合不同的算法部分,例如优化算法、代价函数、模型和数据 集,来建立一个机器学习算法。最后,在 5.11 节中,我们描述了一些限制传统机器学习泛化能力的因素。正是这些挑战推动了克服这些障碍的深度学习算法的发展.
大部分深度学习算法都是基于被称为随机梯度下降的算法求解的.
机器学习算法是一种能够从数据中学习的算法。这里所谓的“学习“是指:“如果计算机程序在任务 \(T\) 中的性能(以 \(P\) 衡量)随着经验 \(E\) 而提高,则可以说计算机程序从经验 \(E\) 中学习某类任务 \(T\) 和性能度量 \(P\) 。”-来自 Mitchell ( 1997 ) 。
经验 \(E\) ,任务 \(T\) 和性能度量 \(P\) 的定义范围非常宽广,本文不做详细解释.
从 “任务” 的相对正式的定义上说,学习过程本身不能算是任务。学习是我们所谓的获取完成任务的能力。机器学习可以解决很多类型的任务,一些非常常见的机器学习任务列举如下:
为了评估机器学习算法的能力,我们必须设计其性能的 定量度量 。通常,性能度量 \(P\) 特定于系统正在执行的任务 \(T\) .
可以理解为不同的任务有不同的性能度量.
对于诸如分类、缺失输入分类和转录任务,我们通常度量模型的 准确率 ( accu- racy )。准确率是指该模型输出正确结果的样本比率。我们也可以通过 错误率 ( error rate )得到相同的信息。错误率是指该模型输出错误结果的样本比率.
我们使用测试集( test set )数据来评估系统性能,将其与训练机器学习系统的训练集数据分开.
值得注意的是,性能度量的选择或许看上去简单且客观,但是选择一个与系统理想表现能对应上的性能度量通常是很难的.
根据学习过程中的不同经验,机器学习算法可以大致分类为 无监督 ( unsuper-vised )算法和 监督 ( supervised )算法.
无监督学习算法 ( unsupervised learning algorithm )训练含有很多特征的数据集,然后学习出这个数据集上有用的结构性质。在深度学习中,我们通常要学习生成数据集的整个概率分布,显式地,比如密度估计,或是隐式地,比如合成或去噪。 还有一些其他类型的无监督学习任务,例如聚类,将数据集分成相似样本的集合.
监督学习算法 ( supervised learning algorithm )也训练含有很多特征的数据集,但与无监督学习算法不同的是 数据集中的样本都有一个标签 ( label )或目标( target )。例如, Iris 数据集注明了每个鸢尾花卉样本属于什么品种。监督学习算法通过研究 Iris 数据集,学习如何根据测量结果将样本划分为三个不同品种.
半监督学习算法 中,一部分样本有监督目标,另外一部分样本则没有。在多实例学习中,样本的整个集合被标记为含有或者不含有该类的样本,但是集合中单独的样本是没有标记的.
大致说来,无监督学习涉及到观察随机向量 \(x\) 的好几个样本,试图显式或隐式地学习出概率分布 \(p(x)\) ,或者是该分布一些有意思的性质; 而监督学习包含观察随机向量 \(x\) 及其相关联的值或向量 \(y\) ,然后从 \(x\) 预测 \(y\) ,通常是估计 \(p(y | x)\) 。术语监督学习( supervised learning )源自这样一个视角,教员或者老师提供目标 \(y\) 给机器学习系统,指导其应该做什么。在无监督学习中,没有教员或者老师,算法必须学会在没有指导的情况下理解数据.
无监督学习和监督学习并不是严格定义的术语。它们之间界线通常是模糊的。很多机器学习技术可以用于这两个任务.
尽管无监督学习和监督学习并非完全没有交集的正式概念,它们确实有助于粗略分类我们研究机器学习算法时遇到的问题。传统地,人们将回归、分类或者结构化输出问题称为监督学习。支持其他任务的密度估计通常被称为无监督学习.
表示数据集的常用方法是 设计矩阵 ( design matrix ).
我们将机器学习算法定义为,通过经验以提高计算机程序在某些任务上性能的算法。这个定义有点抽象。为了使这个定义更具体点,我们展示一个简单的机器学习示例: 线性回归 ( linear regression ).
顾名思义,线性回归解决回归问题。 换句话说,目标是构建一个系统,该系统可以将向量 \(x \in \mathbb{R}\) 作为输入,并预测标量 \(y \in \mathbb{R}\) 作为输出。在线性回归的情况下,输出是输入的线性函数。令 \(\hat{y}\) 表示模型预测值。我们定义输出为 。
其中 \(w \in \mathbb{R}^{n}\) 是 参数 ( parameter )向量.
参数是控制系统行为的值。在这种情况下, \(w_i\) 是系数,会和特征 \(x_i\) 相乘之 后全部相加起来。我们可以将 \(w\) 看作是一组决定每个特征如何影响预测的权重 (weight).
通过上述描述,我们可以定义任务 \(T\) : 通过输出 \(\hat{y} = w^{⊤}x\) 从 \(x\) 预测 \(y\) .
我们使用 测试集 ( test set )来评估模型性能如何,将输入的设计矩 阵记作 \(\textit{X}\) (test),回归目标向量记作 \(y\) (test).
回归任务 常用的一种模型性能度量方法是计算模型在测试集上的 均方误差 ( mean squared error )。如果 \(\hat{y}\) ( test ) 表示模型在测试集上的预测值,那么均方误差表示为
直观上,当 \(\hat{y}^{(test)}\) = \(y^{(test)}\) 时,我们会发现误差降为 0.
图 5.1 展示了线性回归算法的使用示例.
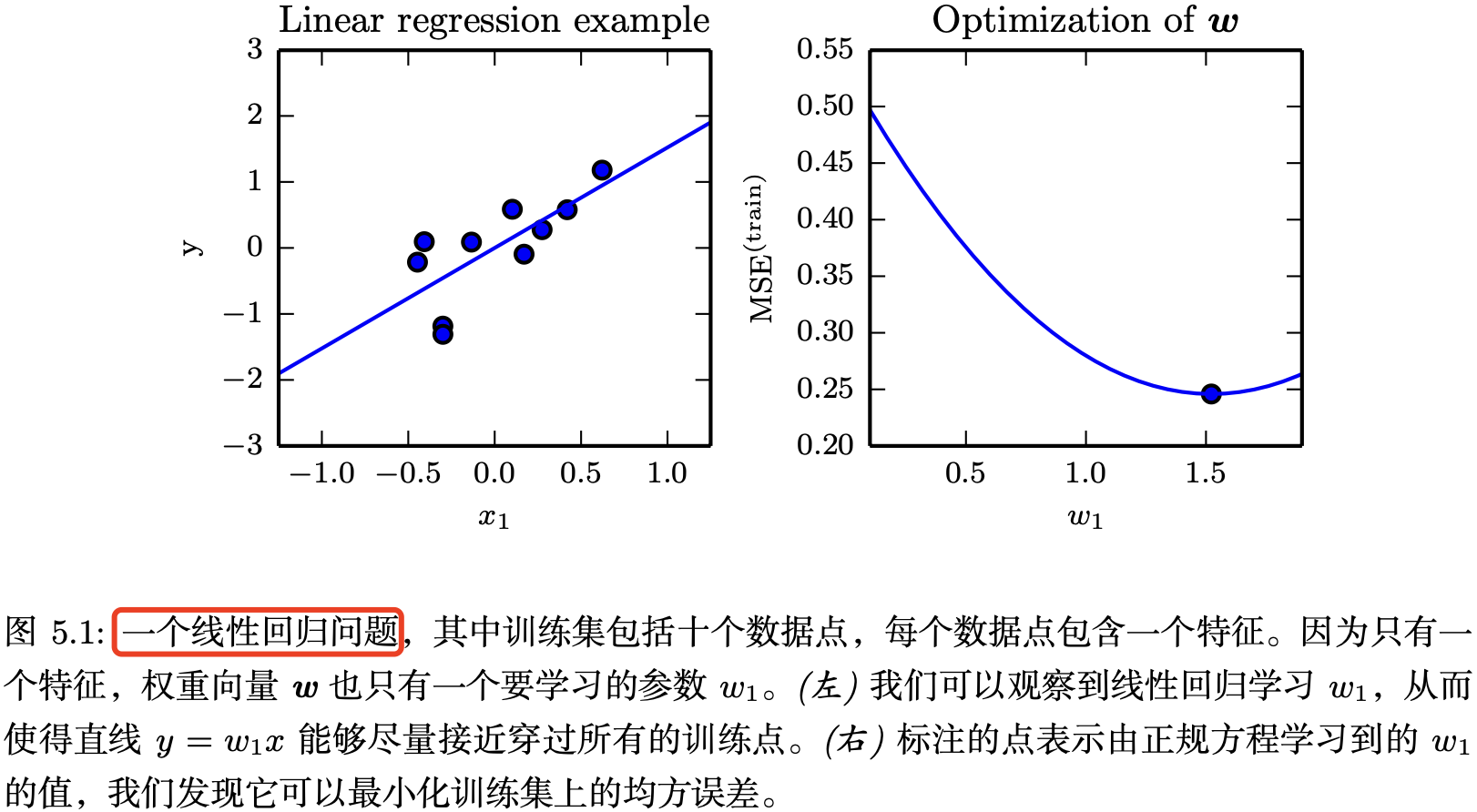
机器学习的挑战主要在于算法如何在测试集(先前未观测的新输入数据)上表现良好,而不只是在训练集上表现良好。在测试集(以前未观察到的输入)上表现良好的能力称为 泛化 ( generalization ).
我们通常通过在与训练集分开收集的测试集上测量其性能来估计机器学习模型的泛化误差.
机器学习算法的两个主要挑战是: 欠拟合 ( underfitting )和 过拟合 ( overfitting ).
我们可以通过调整模型的 容量 ( capacity ),来控制模型是否偏向于过拟合或者欠拟合。通俗地讲, 模型的容量是指其拟合各种函数的能力 。容量低的模型可能很难拟合训练集,容量高的模型可能会过拟合,因为记住了不适用于测试集的训练集性质.
一种控制训练算法容量的方法是选择 假设空间 ( hypothesis space ),即允许 学习算法选择 作为解决方案的一组函数。例如,线性回归算法将其输入的所有线性函数的集合作为其假设空间。我们可以推广线性回归以在其假设空间中包含多项式,而不仅仅是线性函数。这样做就增加模型的容量.
当机器学习算法的容量适合于所执行任务的复杂度和所提供训练数据的数量时,算法效果通常会最佳。容量不足的模型不能解决复杂任务。容量高的模型能够解决复杂的任务,但是当其容量高于任务所需时,有可能会过拟合.
图 5.2 展示了上述原理的使用情况。我们比较了线性,二次和 9 次预测器拟合真 实二次函数的效果.
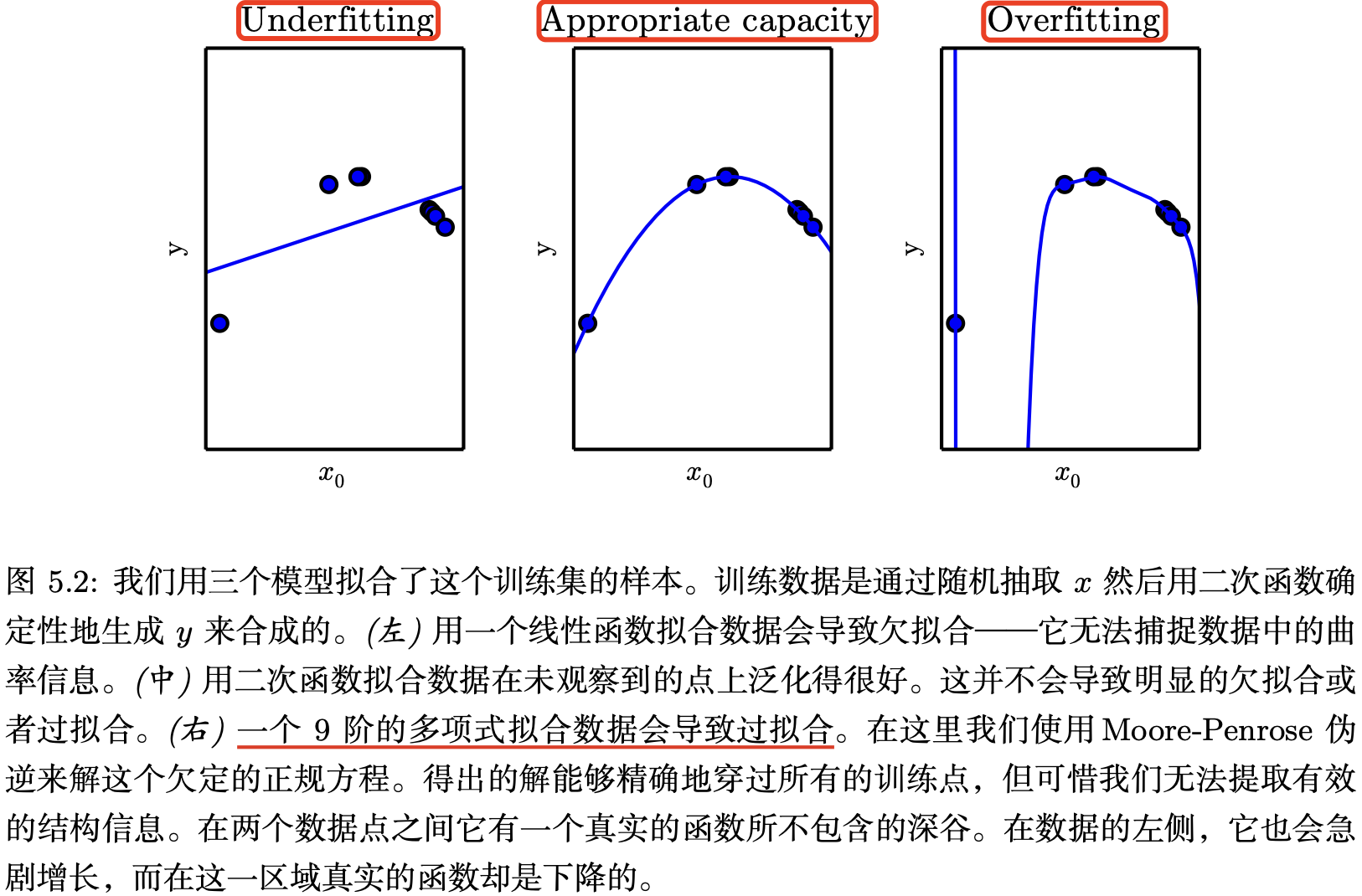
统计学习理论提供了量化模型容量的不同方法。在这些中,最有名的是 Vapnik- Chervonenkis 维度 (Vapnik-Chervonenkis dimension, VC)。 VC 维度量二元分类 器的容量。 VC 维定义为该分类器能够分类的训练样本的最大数目。假设存在 \(m\) 个 不同 \(x\) 点的训练集,分类器可以任意地标记该 \(m\) 个不同的 \(x\) 点, VC 维被定义为 \(m\) 的最大可能值.
因为可以量化模型的容量,所以使得统计学习理论可以进行量化预测。统计学习理论中最重要的结论阐述了训练误差和泛化误差之间差异的上界随着模型容量增长而增长,但随着训练样本增多而下降 ( Vapnik and Chervonenkis, 1971 ; Vapnik, 1982 ; Blumer et al., 1989 ; Vapnik, 1995 )。这些边界为机器学习算法可以有效解决问题提供了理论 验证,但是它们 很少应用于实际中的深度学习算法 。一部分原因是边界太松,另一部分原因是 很难确定深度学习算法的容量 。由于有效容量受限于优化算法的能力,所以确定深度学习模型容量的问题特别困难。而且我们对深度学习中涉及的非常普遍的 非凸优化问题 的理论了解很少.
虽然更简单的函数更可能泛化(训练误差和测试误差的差距小),但我们仍然必须选择一个足够复杂的假设来实现低训练误差。通常,随着模型容量的增加,训练误差会减小,直到它逐渐接近最小可能的误差值(假设误差度量具有最小值)。通常, 泛化误差是一个关于模型容量的 U 形曲线函数 。如下图 5.3 所示.
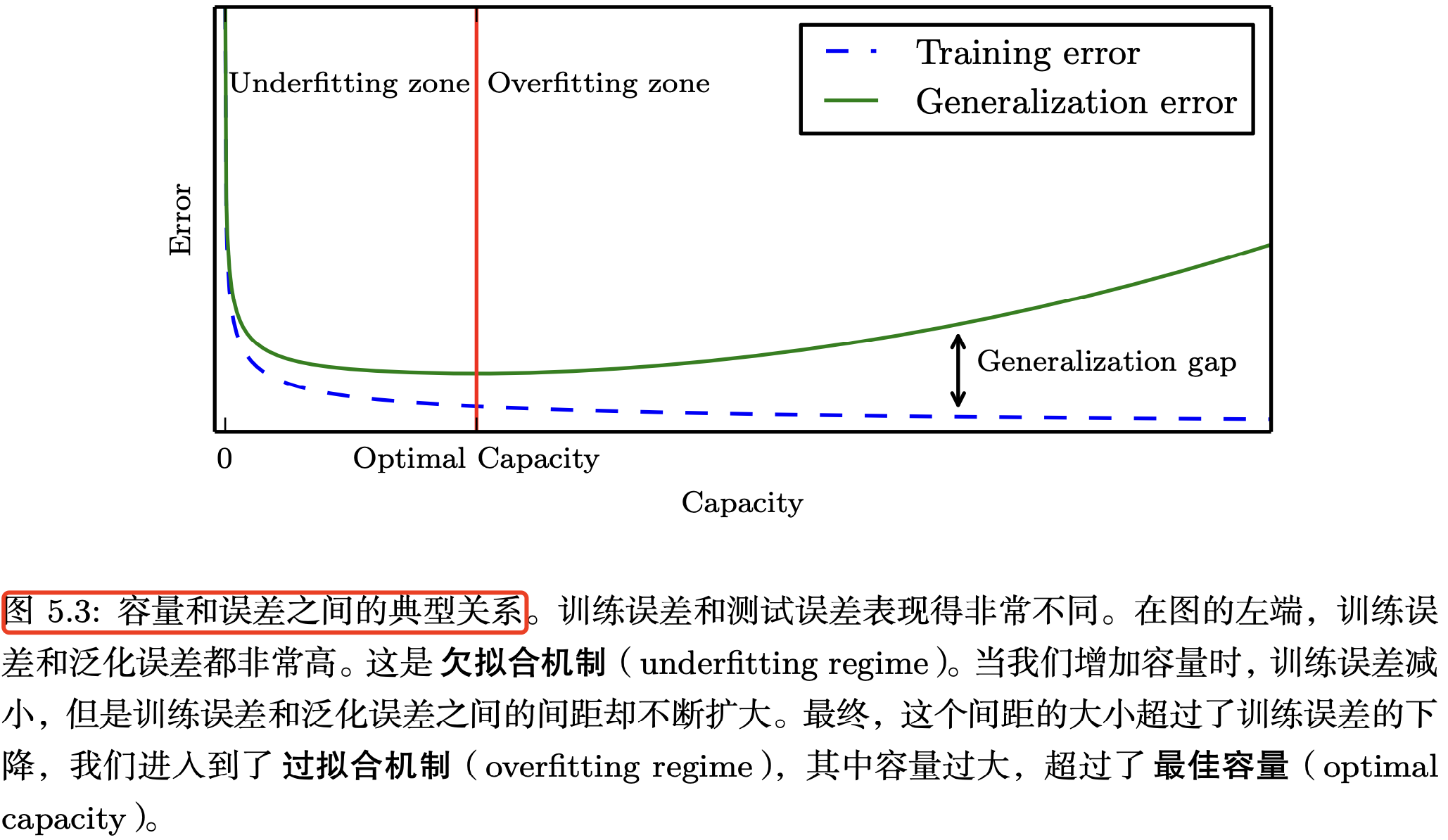
机器学习的 没有免费午餐定理 ( Wolpert,1996 )指出,对所有可能的数据生成分布进行平均,每个分类算法在对以前未观察到的点进行分类时具有相同的错误率。换句话说,在某种意义上, 没有任何机器学习算法普遍优于其他任何算法 .
上述这个结论听着真的让人伤感,但庆幸的是,这些结论仅在我们考虑 所有可能的数据生成分布 时才成立。如果我们对实际应用中遇到的概率分布类型做出假设,那么我们可以 设计出在这些分布上表现良好的学习算法 .
这意味着机器学习研究的目标 不是找一个通用学习算法或是绝对最好的学习算法 。反之,我们的目标是理解什么样的分布与人工智能获取经验的 “真实世界” 相关, 什么样的学习算法在我们关注的数据生成分布上效果最好 .
总结 :没有免费午餐定理清楚地阐述了没有最优的学习算法,即暗示我们必须在特定任务上设计性能良好的机器学习算法.
算法的效果不仅很大程度上受影响于假设空间的函数数量,也取决于这些函数的具体形式.
在假设空间中,相比于某一个学习算法,我们可能更偏好另一个学习算法。这 意味着两个函数都是符合条件的,但是我们更偏好其中一个。只有非偏好函数比偏好函数在训练数据集上效果明显好很多时,我们才会考虑非偏好函数.
我们可以加入 权重衰减 ( weight decay )来修改线性回归的训练标准。新的代价函数 \(J(w)\) 定义如下
\(\lambda\) 是超参数,需提前设置, 其控制我们对较小权重的偏好强度 。当 \(\lambda = 0\) ,我们没有任何偏好。 \(\lambda\) 越大,则权重越小。最小化 \(J(w)\) 会导致权重的选择在 拟合训练数据和较小权重之间进行权衡 .
简单来说,就是给代价函数添加 正则化项 ( regularizer) 的惩罚,即正则化一个学习函数为 \(f(x;\theta)\) 的模型。上述权重衰减的例子中,正则化项是 \(\Omega(w) = \lambda w^{⊤}w\) 。 在后续的第七章,我们将学习其他的 正则化项 .
我们将 正则化定义 为“对学习算法的修改-旨在减少泛化误差而不是训练误差”。正则化是机器学习领域的中心问题之一,只有优化能够与其重要性相媲.
和没有最优的学习算法一样,特别地,也没有最优的正则化形式 。反之,我们必须挑选一个非常适合于我们所要解决的任务的正则形式.
超参数的值不是通过学习算法本身学习出来的,而是需要算法定义者手动指定的 .
通常, 80% 的训练数据用于训练, 20% 用于验证。验证集是用于估计训练中或训练后的泛化误差,从而 更新超参数 .
一个 小规模的测试集 意味着平均测试误差估计的统计不确定性,使得很难判断算法 A 是否比算法 B 在给定的任务上做得更好。解决办法是基于在原始数据上 随机采样或分离 出的不同数据集上 重复训练和测试 ,最常见的就是 \(k\) -折交叉验证,即将数据集分成 \(k\) 个 不重合的子集。测试误差可以估计为 \(k\) 次计算后的平均测试误差。在第 \(i\) 次测试时, 数据的第 \(i\) 个子集用于测试集,其他的数据用于训练集。算法过程如下所示.
k 折交叉验证虽然一定程度上可以解决小数据集上测试误差的不确定性问题,但代价则是增加了计算量.

统计领域为我们提供了很多工具来实现机器学习目标,不仅可以解决训练集上 的任务,还可以泛化。基本的概念,例如参数估计、偏差和方差,对于正式地刻画泛化、欠拟合和过拟合都非常有帮助.
略 。
偏差和方差度量着估计量的两个不同误差来源。偏差度量着偏离真实函数或参数的误差期望。而方差度量着数据上任意特定采样可能导致的估计期望的偏差.
偏差和方差的关系和机器学习容量、欠拟合和过拟合的概念紧密相联。用 MSE 度量泛化误差(偏差和方差对于泛化误差都是有意义的)时,增加容量会增加方差,降低偏差。如图 5.6 所示,我们再次在关于容量的函数中,看到泛化误差的 U 形曲线.
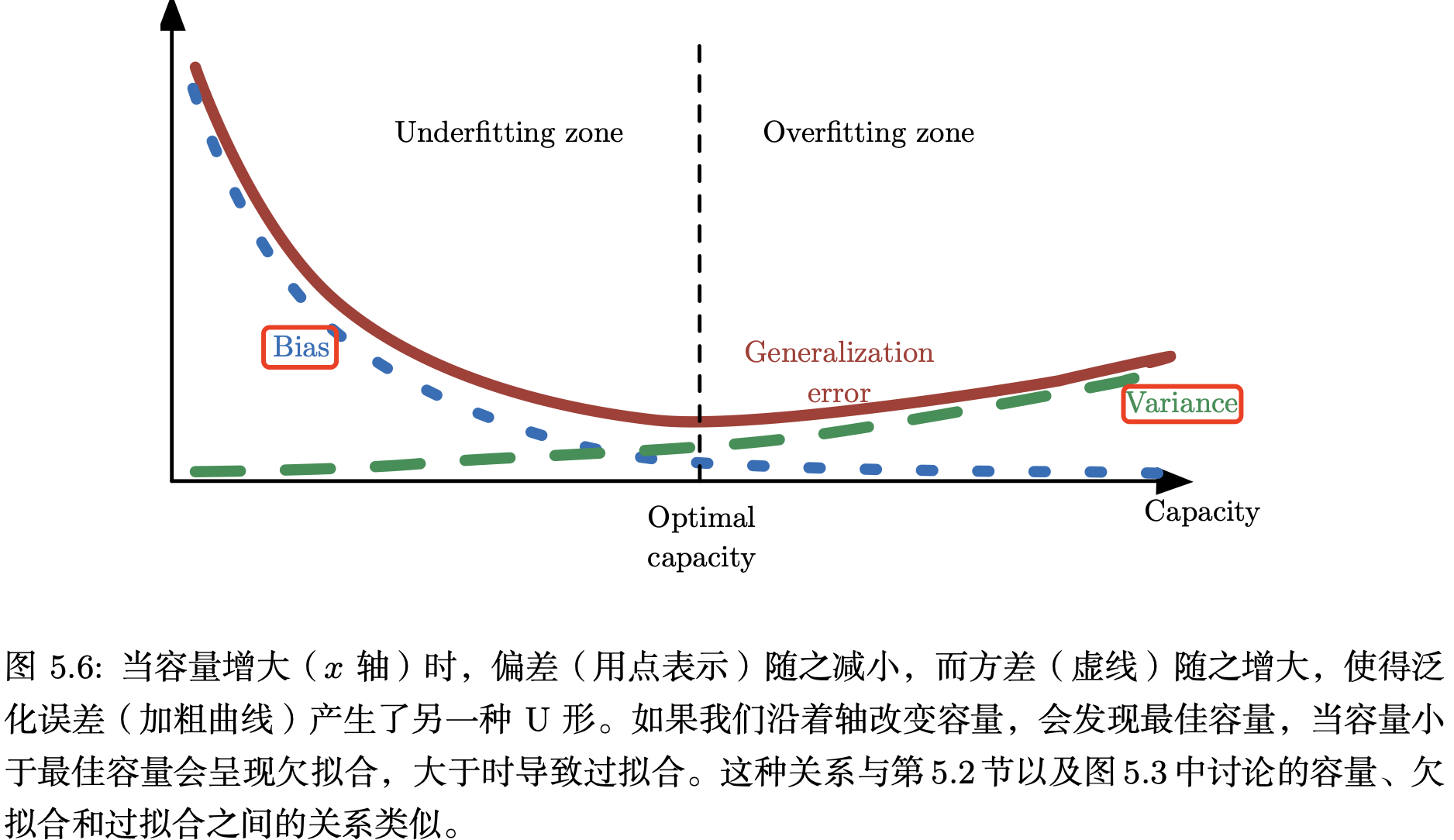
《深度学习》 。
最后此篇关于深度学习机器学习基础-基本原理的文章就讲到这里了,如果你想了解更多关于深度学习机器学习基础-基本原理的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
27
4
 0
0
关闭。这个问题是opinion-based .它目前不接受答案。 想要改进这个问题? 更新问题,以便 editing this post 可以用事实和引用来回答它. 关闭 9 年前。 Improve
介绍篇 什么是MiniApis? MiniApis的特点和优势 MiniApis的应用场景 环境搭建 系统要求 安装MiniApis 配置开发环境 基础概念 MiniApis架构概述
我正在从“JavaScript 圣经”一书中学习 javascript,但我遇到了一些困难。我试图理解这段代码: function checkIt(evt) { evt = (evt) ? e
package com.fastone.www.javademo.stringintern; /** * * String.intern()是一个Native方法, * 它的作用是:如果字
您会推荐哪些资源来学习 AppleScript。我使用具有 Objective-C 背景的传统 C/C++。 我也在寻找有关如何更好地开发和从脚本编辑器获取更快文档的技巧。示例提示是“查找要编写脚本的
关闭。这个问题不满足Stack Overflow guidelines .它目前不接受答案。 想改善这个问题吗?更新问题,使其成为 on-topic对于堆栈溢出。 4年前关闭。 Improve thi
关闭。这个问题不满足Stack Overflow guidelines .它目前不接受答案。 想改善这个问题吗?更新问题,使其成为 on-topic对于堆栈溢出。 7年前关闭。 Improve thi
关闭。这个问题不符合 Stack Overflow guidelines 。它目前不接受答案。 想改善这个问题吗?更新问题,以便堆栈溢出为 on-topic。 6年前关闭。 Improve this
我是塞内加尔的阿里。我今年60岁(也许这是我真正的问题-笑脸!!!)。 我正在学习Flutter和Dart。今天,我想使用给定数据模型的列表(它的名称是Mortalite,请参见下面的代码)。 我尝试
关闭。这个问题是off-topic .它目前不接受答案。 想改进这个问题? Update the question所以它是on-topic对于堆栈溢出。 9年前关闭。 Improve this que
学习 Cappuccino 的最佳来源是什么?我从事“传统”网络开发,但我对这个新框架非常感兴趣。请注意,我对 Objective-C 毫无了解。 最佳答案 如上所述,该网站是一个好地方,但还有一些其
我正在学习如何使用 hashMap,有人可以检查我编写的这段代码并告诉我它是否正确吗?这个想法是有一个在公司工作的员工列表,我想从 hashMap 添加和删除员工。 public class Staf
我正在尝试将 jQuery 与 CoffeScript 一起使用。我按照博客中的说明操作,指示使用 $ -> 或 jQuery -> 而不是 .ready() 。我玩了一下代码,但我似乎无法理解我出错
还在学习,还有很多问题,所以这里有一些。我正在进行 javascript -> PHP 转换,并希望确保这些做法是正确的。是$dailyparams->$calories = $calories;一条
我目前正在学习 SQL,以便从我们的 Magento 数据库制作一个简单的 RFM 报告,我目前可以通过导出两个查询并将它们粘贴到 Excel 模板中来完成此操作,我想摆脱 Excel 模板。 我认为
我知道我很可能会因为这个问题而受到抨击,但没有人问,我求助于你。这是否是一个正确的 javascript > php 转换 - 在我开始不良做法之前,我想知道这是否是解决此问题的正确方法。 JavaS
除了 Ruby-Doc 之外,哪些来源最适合获取一些示例和教程,尤其是关于 Ruby 中的 Tk/Tile?我发现自己更正常了 http://www.tutorialspoint.com/ruby/r
我只在第一次收到警告。这正常吗? >>> cv=LassoCV(cv=10).fit(x,y) C:\Python27\lib\site-packages\scikit_learn-0.14.1-py
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visit the
As it currently stands, this question is not a good fit for our Q&A format. We expect answers to be

我是一名优秀的程序员,十分优秀!