
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4



大家好,又见面了.
本文是笔者作为掘金技术社区签约作者的身份输出的缓存专栏系列内容,将会通过系列专题,讲清楚缓存的方方面面。如果感兴趣,欢迎关注以获取后续更新.
作为《 深入理解缓存原理与实战设计 》系列专栏,在前面的文章中,我们一起领略了Guava Cache、Caffeine、Ehcache等优秀的本地JVM级别本地缓存框架的特性、原理与具体的使用方法。除却本地缓存之外,在当前分布式、微服务等架构盛行的时代, 本地缓存 明显 无法满足 大型系统中的各种缓存诉求,比如前面文章中反复提及的 缓存漂移 问题、以及单机缓存无法逾越的 内存容量 瓶颈。作为应对之法, 集中式缓存 被广泛的使用在各中分布式系统中,而使用最广泛的莫过于大家耳熟能详的 Redis 了.
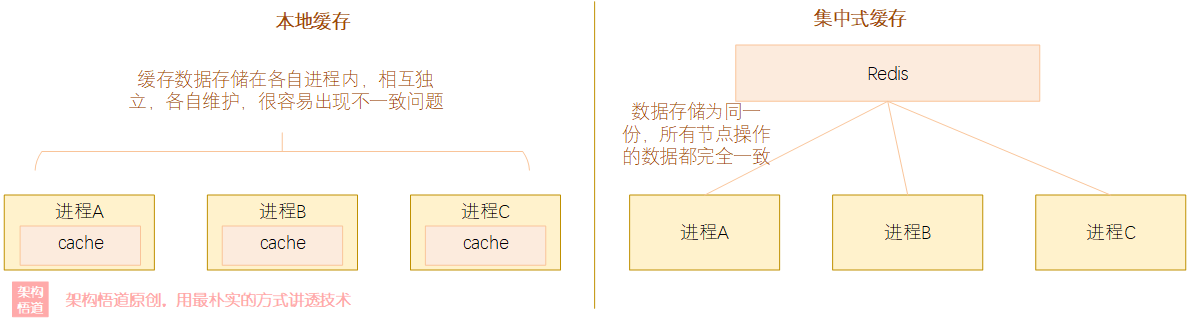
提到Redis,大家应该都不会陌生,至少应该是有听过这个名字。在中大型分布式系统中,Redis似乎成了一种标配,而说到集中缓存,很多人脑海中第一闪过的也是Redis。 Redis 是一个基于内存的非关系型数据库( NoSQL ),主要是存储key-value类型的键值对数据,而value则支持多种不同的类型。由于其强悍的性能表现以及完善的可靠性与集群扩展机制,使其俘获了众多开发人员的青睐,成为了高并发系统的制胜法宝。接下来的几篇文章中呢,我们就一起聊一聊与Redis有关的内容,探讨下Redis在集中式缓存领域一枝独秀的秘诀.

作为缓存组件,Redis的数据结构整体而言就是 key-value 类型的键值对,但是Redis对于value类型的支持还是比较丰富的,提供了 5种 不同的数据结构,可以满足大部分场景的使用诉求.
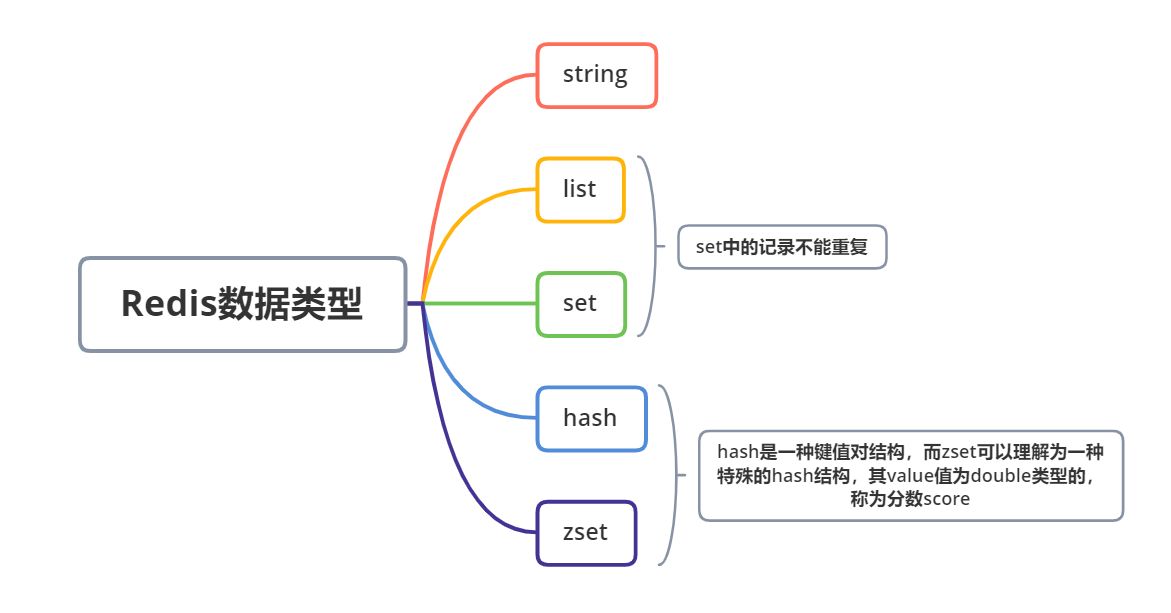
对几种类型的结构特点与使用注意点梳理汇总如下:
| 类型 | 说明 | 支持功能 |
|---|---|---|
| string | 普通字符串 | 字符串的基础增删改查能力,如果是整数或者浮点数,还支持 自增自减 能力。 |
| list | 链表内容,每个元素都是一个独立的字符串,内容可以相同 | 基础增删改查能力,从链表两端插入或者弹出元素,按照下标获取指定元素列表等等 |
| set | 无序集合,每个元素都是一个独立字符串,元素之间不允许重复 | 基础增删改查能力,判断元素是否存在,随机获取元素等等 |
| hash | 无序的key-value键值对集合 | 基础增删改查能力,获取所有的键值对 |
| zset | 可以理解为一种比较特殊的hash结构,含有member和score两个概念,对应到hash类型上分别是key与value的关系,其区别点在在于score是固定的double类型的value | 基础增删改查能力,支持根据score排序并获取指定的排序个数的元素列表 |
实际的使用中,也会根据各自类型不同的特点,用来实现不同的业务诉求.
举个例子:
一个系统内的通知公告查看功能,可以将公告ID作为key,然后这边通知公告的阅读量作为score,在redis中存储为zset类型,然后每次读取详情操作的都累加更新下对应的score值,这样的话,就可以根据score进行降序排列,拉取到热门新闻公告的排行榜.
基于Redis提供的基础能力,在项目中不同场景都有被广泛的使用,下面列举几个常见的使用场景.
在分布式系统里面经常会需要用到分布式锁,实现分布式锁的方式有很多种,其中使用的比较广泛的一种策略,就是基于Redis来实现的。之所以采用Redis来作为分布式锁,可以有几方面理由:
setnx + expire 的机制,完全契合分布式锁的实现要点 Redisson 客户端的流行,使得基于redis的分布式锁更加简单 借助redis超高的处理性能,经常会被放置在数据库的前面,用于数据扛压场景使用。比如各种 秒杀 场景,可以将数据库中的库存信息缓存到redis中,然后利用redis来抗住秒杀期间洪水般的大并发量请求.
这个场景也很常见,比如用户发送的短信验证码,一般都会要求5分钟内有效。这种情况下,可以将验证码信息存储在redis中并设定5分钟后自动过期。这样的话就可以实现超时失效的功能,而无需业务层面去维护过期信息.
在分布式系统中,Redis作为一个可以被所有节点访问的集中节点,加上其具备的 incrby 原子命令,使得在多个场景下发挥价值:
将其用作 全局唯一ID 的生成,以保证各个节点之间生成的唯一ID不会冲突.
incrby可以实现全局请求量的统计计数,结合expire一起可以实现定时重置计数器,进而实现 限流能力 .
其实,Redis还支持位图( Bitmap )格式进行数据存储。前面我们说Redis支持五种数据结构里面并没有看到Bitmap类型的身影,其实Redis的bitmap数据最终存储的是string类型,但是Redis为Bitmap操作提供了配套的操作接口,比如 setbit 命令.
位图的存在就是为了服务于 海量数据 的存储场景的,比如系统里面有10亿用户,现在需要记录每个人每天的签到情况,每天10亿数据量,如果用普通String类型存储,每天10亿条数据量,时间一久任何的Redis也扛不住。而基于bitmap的方式存储,则可以极大的降低整体数据量。关于redis的bitmap操作与使用,后面文章会展开阐述.
基于Redis的 zset 数据结构,可以将热门值作为score进行存储,这样可以根据需要,按照score进行排序并拉取榜单数据.
这篇文章中,我们改变下以往的文章行文叙事风格。我们先不直接切入到Redis的具体特性或功能点的实现原理与使用层面,而是先从面试场景作为切入口,通过几个面试问题,来感受下Redis整体的“魅力”、引出Redis所具备的核心特性与常见使用注意事项.
因为Redis在项目中的广泛使用,也让其成为了后端面试中的热门嘉宾。很多小伙伴应该在面试中都被问过与Redis有关的问题吧?当然有很多的八股文背诵一下就可以应付很多简单的面试场景,但笔者作为面试官一般不太会直接去问八股文问题,经常会将问题稍作包装之后再去问.
下面举几个例子.
Q1. 很多人都说Redis处理快是因为它是单线程的,Redis进程中真的只有一个线程吗?为什么常规项目中为了提升并发量都会采用线程池等方式来多线程处理,而Redis却反其道而行之呢?
很多的面试八股文中都会提到说Redis是单线程的,这个说法其实 不够严谨 ,因为Redis中并非是只有一个线程,整个进程中还有一些额外的线程负责做一些辅助的其他事务,比如管理与客户端的连接,比如队列中消息的维护等等.
Redis整体基于一种多路复用的机制来实现请求的接收与分配处理。整体简化后的处理逻辑如下图所示.
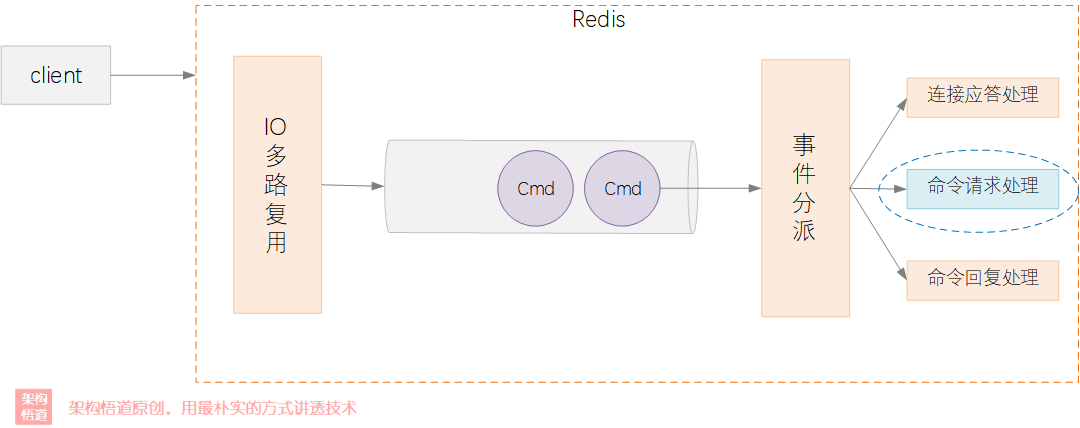
所以说,其实Redis仅仅是采用单线程来负责执行命令请求处理,而非整个Redis就是一个单线程的。回到最初的问题,为什么Redis选择采用单线程的方式来执行命令。在多线程编程的时候面临问题主要有:
而由于Redis是一种key-value模型的数据结构模式,比如很多查询操作都是 O(1) 的时间复杂度,其操作执行速度非常快,所以这种情况下,结合 I/O多路复用 模型一起,使用单线程的方式执行命令,反而可以达到比多线程更加优异的表现.
问题可以进一步引申,可以继续聊一些其他问题。比如:
既然Redis是单线程的,那使用的时候有什么需要注意的事项吗? 不能执行耗时操作,会阻塞其余请求命令的执行.
I/O多路复用 是个什么概念?它和 BIO 、 NIO 之间有什么异同? 诸如此类的问题,都可以进一步的去展开考察.
当前计算机一般都是多核CPU,用单线程去执行的话,相当于其它几个核就浪费了,那有什么方式可以将其余的几个核也利用起来么? 答案其实也不难,在一台机器上同时去部署多个Redis进程,组成个集群,就可以啦.
Q2. 如果我想要查询一下生产环境的Redis中有多少以“User_”开头的记录数量,可以怎么做?
这个问题其实是有一点小陷阱的。查找以指定前缀开头的记录,首先很多同学想到的就是 keys 命令,但问题中有个约束是在生产环境中执行。所以这个问题看似简单,其实需要结合如下几点来综合考虑:
keys 命令是一个耗时操作,复杂度 O(n) ,数据量越大执行速度越慢; 基于上述几点因素,如果在数据量较大的生产环境去执行 keys 命令将会导致执行耗时特别长,而由于Redis是单线程执行命令,就会导致其余请求命令被阻塞无法执行,这样在一个高并发集群内,很容易造成集群内请求的大面积阻塞,影响系统的整体稳定性.
那么keys命令不可以用,有什么替代方案呢?可以使用 scan 命令.
Q3. 假如有一批机器,内存都比较小(单机内存小于整体待缓存数据量),用来搭建个Redis做热点数据缓存扛压以降低数据库的请求压力。如果你来做的话,会有哪些应对思路呢?
这个问题就比较开放,而且答案也不唯一,考核的点也比较综合.
首先来分析下题目,从题干描述中可以捕捉到几个信息,以及对应的关联知识点:
热点数据 ,扛住大部分的流量; 集群 的方式,扩展Redis集群总内存大小,这样以集群的力量来缓存全部的数据量。 所以说这个题目里面其实涉及到了两个考点:
更进一步,又可以引申出很多其它细节问题,比如:
Redis中的数据淘汰策略有哪些? no-enviction、volatile-lru、volatile-ttl、volatile-random、allkeys-lru、allkeys-random 。
Redis的数据淘汰策略与数据过期有啥区别? 数据过期是达到了设定的过期时间之后使数据不可用,而数据淘汰策略主要是在容量满之后采取的被动应对策略.
Redis集群中是如何决定一个记录应该保存在哪个节点上的? 关于 一致性Hash 相关的内容,以及如何解决数据 倾斜问题 、节点扩容对缓存命中情况的影响等等.
回头看下,是不是其中蕴含的内容还是蛮多的?
这里我们以面试场景中会被问及的几个问题作为切入点,大概聊了下与Redis有关的一系列内容。当然这里介绍的都比较浅显,甚至只是列了下相关的知识点,主要是先让大家先感受下Redis所包含与涉及的相关知识点。在后续的文章中,我们将逐步逐个地去剖析与介绍.
好啦,作为redis部分的第一篇内容,我们只是简单的聊了下 Redis 的基础概念以及主要的特性介绍,同时通过几个实际的面试题演示了下Redis整体内容的“ 博大精深 ”。而关于Redis的更多细化方向的展开阐述,我们将会在后续文章中逐步介绍。那么你对Redis如何看呢?欢迎评论区一起交流下,期待和各位小伙伴们一起切磋、共同成长.
📣 补充说明1 :
本文属于《 深入理解缓存原理与实战设计 》系列专栏的内容之一。该专栏围绕缓存这个宏大命题进行展开阐述,全方位、系统性地深度剖析各种缓存实现策略与原理、以及缓存的各种用法、各种问题应对策略,并一起探讨下缓存设计的哲学.
如果有兴趣,也欢迎关注此专栏.
📣 补充说明2 :
我是悟道,聊技术、又不仅仅聊技术~ 。
如果觉得有用,请 点赞 + 关注 让我感受到您的支持。也可以关注下我的公众号【架构悟道】,获取更及时的更新.
期待与你一起探讨,一起成长为更好的自己.

最后此篇关于Redis缓存何以一枝独秀?——从百变应用场景与热门面试题中感受下Redis的核心特性与使用注意点的文章就讲到这里了,如果你想了解更多关于Redis缓存何以一枝独秀?——从百变应用场景与热门面试题中感受下Redis的核心特性与使用注意点的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
我需要将文本放在 中在一个 Div 中,在另一个 Div 中,在另一个 Div 中。所以这是它的样子: #document Change PIN
奇怪的事情发生了。 我有一个基本的 html 代码。 html,头部, body 。(因为我收到了一些反对票,这里是完整的代码) 这是我的CSS: html { backgroun
我正在尝试将 Assets 中的一组图像加载到 UICollectionview 中存在的 ImageView 中,但每当我运行应用程序时它都会显示错误。而且也没有显示图像。 我在ViewDidLoa
我需要根据带参数的 perl 脚本的输出更改一些环境变量。在 tcsh 中,我可以使用别名命令来评估 perl 脚本的输出。 tcsh: alias setsdk 'eval `/localhome/
我使用 Windows 身份验证创建了一个新的 Blazor(服务器端)应用程序,并使用 IIS Express 运行它。它将显示一条消息“Hello Domain\User!”来自右上方的以下 Ra
这是我的方法 void login(Event event);我想知道 Kotlin 中应该如何 最佳答案 在 Kotlin 中通配符运算符是 * 。它指示编译器它是未知的,但一旦知道,就不会有其他类
看下面的代码 for story in book if story.title.length < 140 - var story
我正在尝试用 C 语言学习字符串处理。我写了一个程序,它存储了一些音乐轨道,并帮助用户检查他/她想到的歌曲是否存在于存储的轨道中。这是通过要求用户输入一串字符来完成的。然后程序使用 strstr()
我正在学习 sscanf 并遇到如下格式字符串: sscanf("%[^:]:%[^*=]%*[*=]%n",a,b,&c); 我理解 %[^:] 部分意味着扫描直到遇到 ':' 并将其分配给 a。:
def char_check(x,y): if (str(x) in y or x.find(y) > -1) or (str(y) in x or y.find(x) > -1):
我有一种情况,我想将文本文件中的现有行包含到一个新 block 中。 line 1 line 2 line in block line 3 line 4 应该变成 line 1 line 2 line
我有一个新项目,我正在尝试设置 Django 调试工具栏。首先,我尝试了快速设置,它只涉及将 'debug_toolbar' 添加到我的已安装应用程序列表中。有了这个,当我转到我的根 URL 时,调试
在 Matlab 中,如果我有一个函数 f,例如签名是 f(a,b,c),我可以创建一个只有一个变量 b 的函数,它将使用固定的 a=a1 和 c=c1 调用 f: g = @(b) f(a1, b,
我不明白为什么 ForEach 中的元素之间有多余的垂直间距在 VStack 里面在 ScrollView 里面使用 GeometryReader 时渲染自定义水平分隔线。 Scrol
我想知道,是否有关于何时使用 session 和 cookie 的指南或最佳实践? 什么应该和什么不应该存储在其中?谢谢! 最佳答案 这些文档很好地了解了 session cookie 的安全问题以及
我在 scipy/numpy 中有一个 Nx3 矩阵,我想用它制作一个 3 维条形图,其中 X 轴和 Y 轴由矩阵的第一列和第二列的值、高度确定每个条形的 是矩阵中的第三列,条形的数量由 N 确定。
假设我用两种不同的方式初始化信号量 sem_init(&randomsem,0,1) sem_init(&randomsem,0,0) 现在, sem_wait(&randomsem) 在这两种情况下
我怀疑该值如何存储在“WORD”中,因为 PStr 包含实际输出。? 既然Pstr中存储的是小写到大写的字母,那么在printf中如何将其给出为“WORD”。有人可以吗?解释一下? #include
我有一个 3x3 数组: var my_array = [[0,1,2], [3,4,5], [6,7,8]]; 并想获得它的第一个 2
我意识到您可以使用如下方式轻松检查焦点: var hasFocus = true; $(window).blur(function(){ hasFocus = false; }); $(win

我是一名优秀的程序员,十分优秀!