
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 28
28
 4
4


作者:vivo 互联网服务器团队- Liu Xin、Yu Dan 。
本文基于故障定位项目的实践,围绕根因定位算法的原理进行展开介绍。鉴于算法有一定的复杂度,本文通过图文的方式进行说明,希望即使是不懂技术的同学也能理解.
作为一名IT从业人员,比如开发和运维,多少有过类似的经历:睡觉的时候被电话叫醒,过节的时候在值班,游玩的时候被通知处理故障。作为一名程序员,我们时时刻刻都在想着运用信息技术,为别人解决问题,提升效率,节省成本。随着微服务架构的快速发展,带来一系列复杂的调用链路和海量的数据。对于我们来说,排查问题是一个大挑战,寻找故障原因犹如大海捞针,需要花费大量的时间和精力.
vivo已经建立了一套完整的端到端监控体系,涵盖了基础监控、通用监控、调用链、日志监控、拨测监控等。这些系统每天都会产生海量的数据,如何利用好这些数据,挖掘数据背后的潜在价值,让数据更好的服务于人,成为了监控体系的探索方向。目前行业内很多厂商都在朝AIOps探索,业界有一些优秀的根因分析算法和论文,部分厂商分享了在故障定位实践中的解决方案。vivo有较完整的监控数据,业界有较完整的分析算法和解决方案,结合两者就可以将故障定位平台run起来,从而解决困扰互联网领域的定位问题。接下来我们看下实施的效果.
目前主要针对平均时延指标的问题,切入场景包括两种:主动查询和调用链告警.
当用户反馈某个应用很慢或超时,我们第一反应可能是查看对应服务的响应时间,并定位出造成问题的原因,通常这两个步骤是分别进行,需要用到一系列的监控工具,费时费力。如果使用故障定位平台,只需从vivo的paas平台上进入故障定位首页,找到故障服务和故障时间,剩下的事情就交给系统完成.
当收到一条关于平均响应时间问题的调用链告警,只需查看告警内容下方的查看原因链接,故障定位平台就能帮助我们快速定位出可能的原因。下图是调用链告警示例:

。
调用链是vivo服务级监控的重要手段,上图红框内原因链接是故障定位平台提供的根因定位能力.
通过以上两种方式进入故障定位平台后,首先看到的是故障现场,下图表示服务A的平均响应时间突增.
。
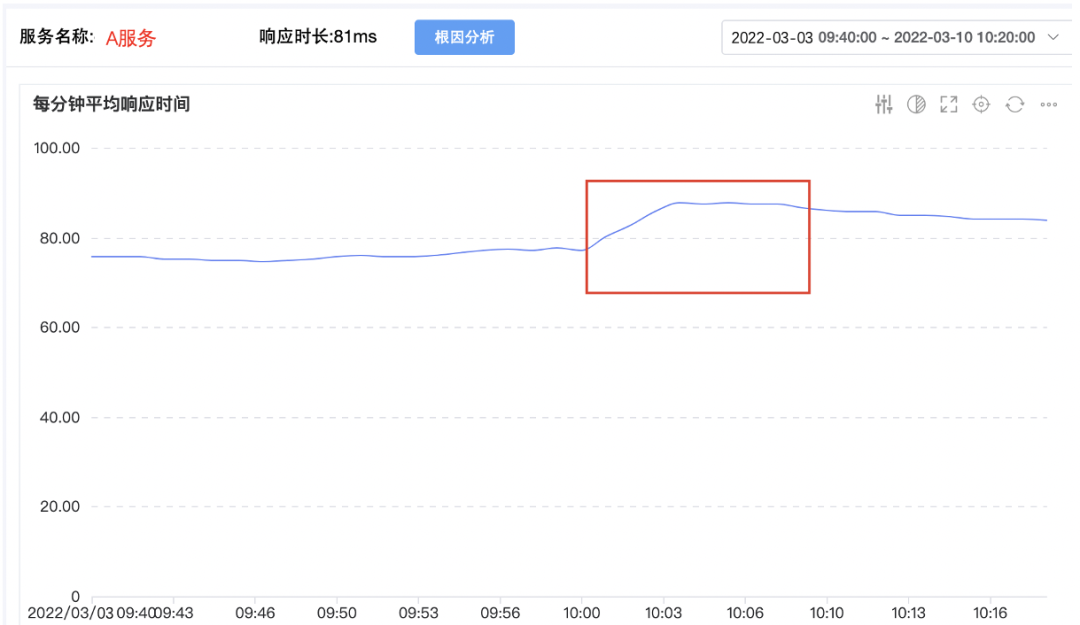
上图红框区域,A服务从10:00左右,每分钟平均时延从78ms开始增长,突增到10:03分的90ms左右.
。
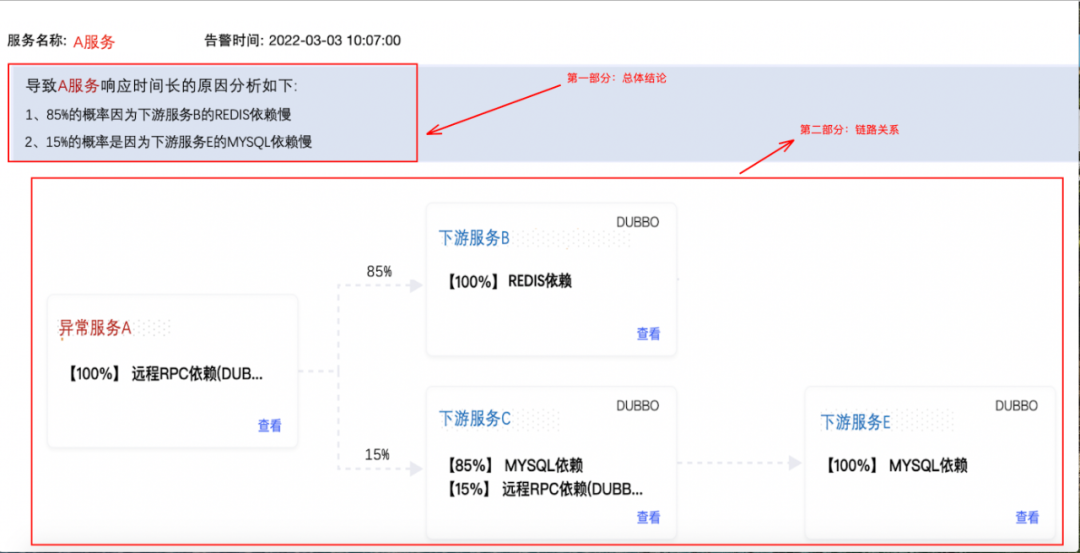
直接点击图2蓝色的【根因分析】按钮,就可以分析出下图结果:
。
从点击按钮到定位出原因的过程中,系统是如何做的呢?接下来我们看下系统的分析流程.
。
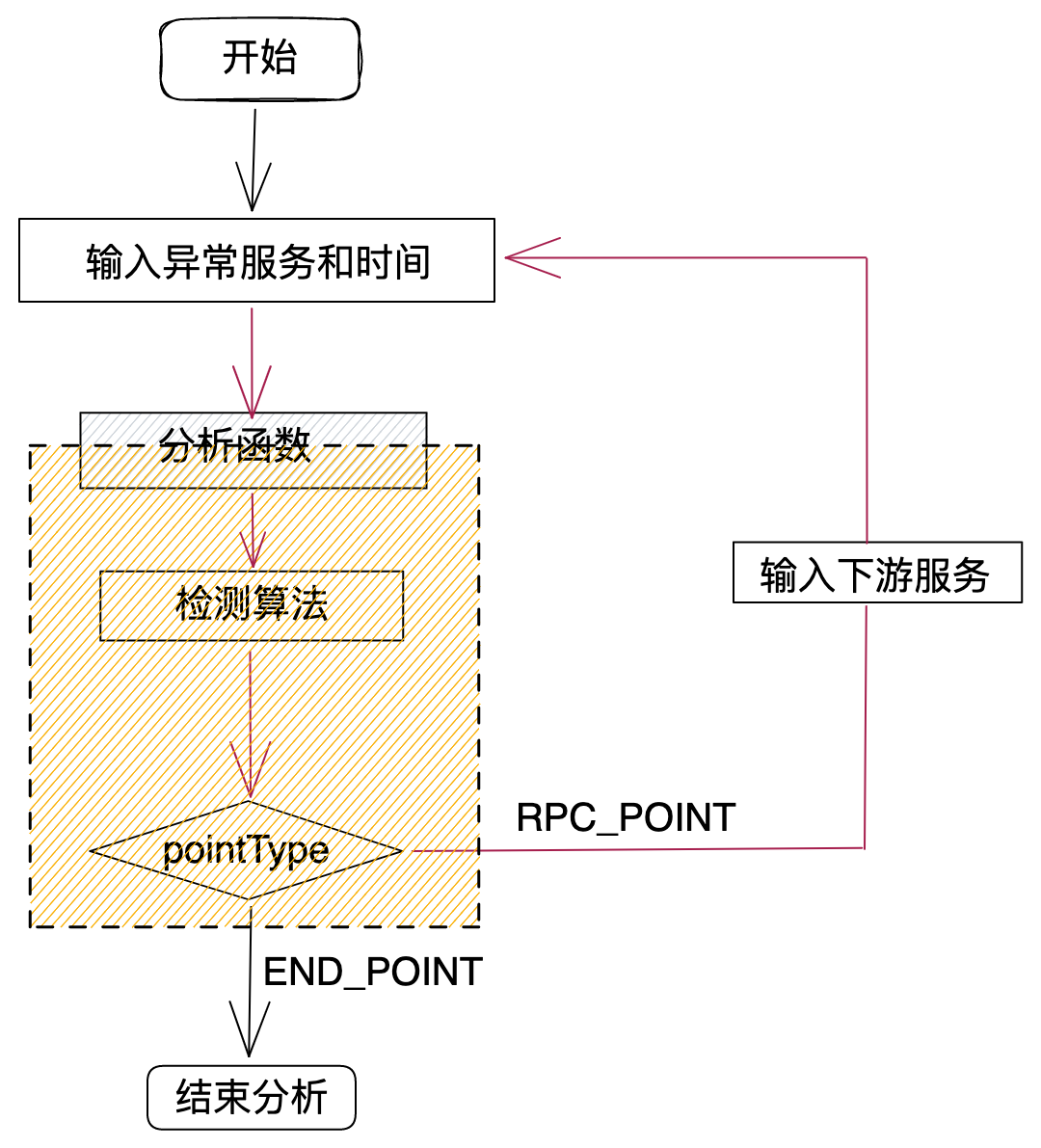
图4是根因分析的主要流程,下面将通过文字详细描述:
第一步: 前端将异常服务名和时间作为参数通过接口传递到后端; 。
第二步: 后端执行分析函数,分析函数调用检测算法,检测算法分析后,返回一组下游数据给分析函数(包括下游服务及组件、波动方差及pointType); 。
第三步: 分析函数根据pointType做不同逻辑处理,如果pointType=END_POINT,则结束分析,如果pointType=RPC_POINT,则将下游服务作为入参,继续执行分析函数,形成递归.
RPC_POINT包含组件:HTTP、DUBBO、TARS 。
END_POINT包含组件:MYSQL、REDIS、ES、MONGODB、MQ 。
。
最终分析结果展示了造成 服务A异常 的主要链路及原因,如下图所示:

。
在整个分析过程中,分析函数负责调用检测算法,并根据返回结果决定是否继续下钻分析。而核心逻辑是在检测算法中实现的,接下来我们看下检测算法是如何做的.
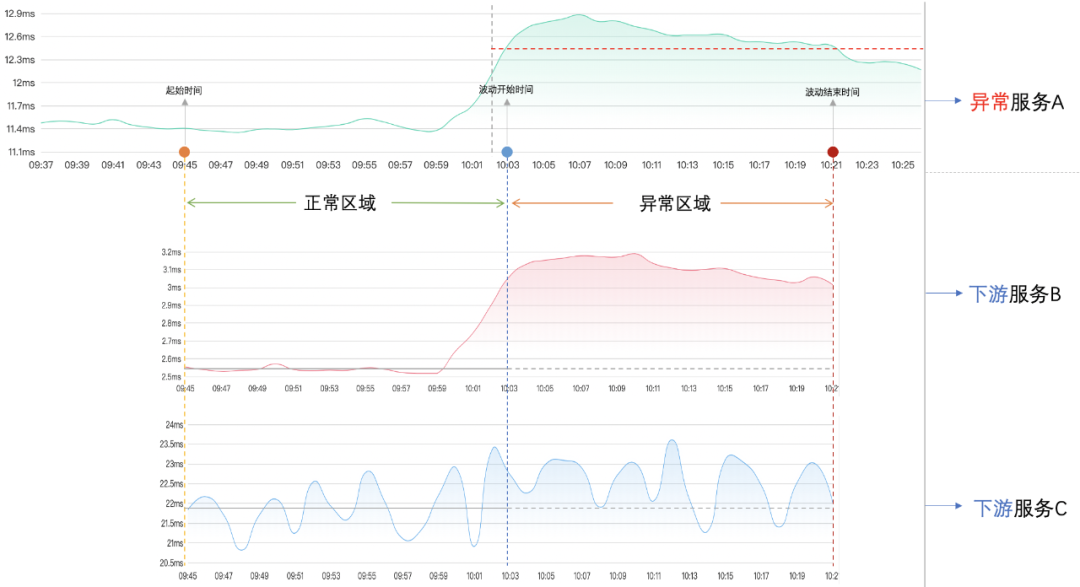
检测算法的大体 逻辑 是:先分析异常服务,标记出起始时间、波动开始时间、波动结束时间。然后根据起始时间~波动结束时间,对异常服务按组件和服务名下钻,将得到的下游服务时间线分成两个区域:正常区域(起始时间~波动开始时间)和异常区域(波动开始时间~波动结束时间),最后计算出每个下游服务的波动方差。大体过程如下图所示:
。
图中异常服务A调用了两个下游服务B和C,先标记出服务A的起始时间、波动开始时间、波动结束时间。然后将下游服务按时间线分成两个正常区域和异常区域,标准是起始时间 到 波动开始时间属于正常区域,波动开始时间 到 波动结束时间属于异常区域.
那么波动方差和异常原因之间有什么关联呢?
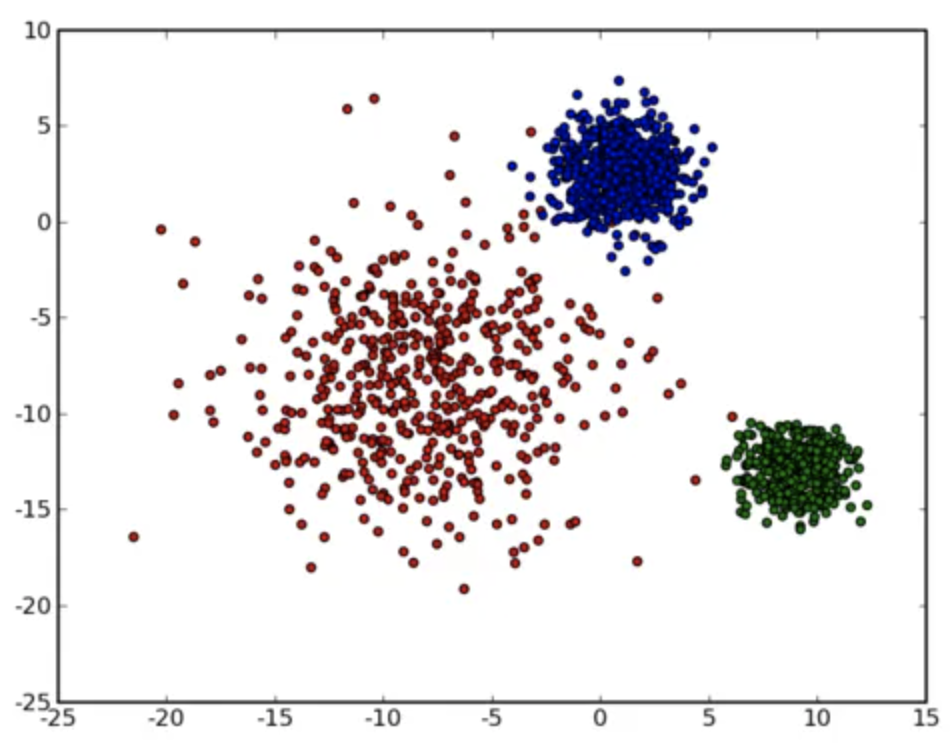
其实波动方差代表当前服务波动的一个量化值,有了这个量化值后,我们利用 K-Means聚类算法 ,将波动方差值分类,波动大的放一起聚成一类,波动小的放一起聚成一类。如下图:
。
最后我们通过聚成类的波动方差,过滤掉波动小的聚类,找到最可能造成异常服务的原因。以上是对算法原理的简要介绍,接下来我们更进一步,深入到算法实现细节.
(1)切分时间线: 将异常时间线从中点一分为二,如下图:

。
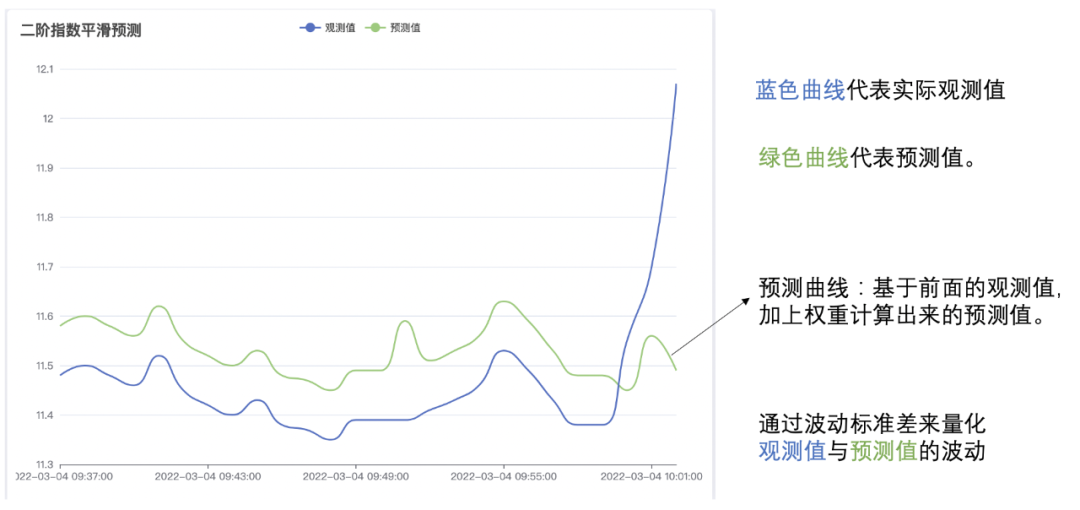
(2) 计算波动标准差: 运用 二级指数平滑算法 对前半段进行数据预测,然后根据观测值与预测值计算出波动标准差,如下图:
。
(3)计算异常波动范围: 后半段大于3倍波动标准差的时间线属于异常波动,下图红线代表3倍波动标准差,所以异常波动是红线以上的时间线,如下图:

。
(4)时间点标记: 红线与时间线第一次相交的时间点是波动开始时间,红线与时间线最后一次相交的时间点是波动结束时间,起始时间和波动结束时间关于波动开始时间对称,如下图:

。
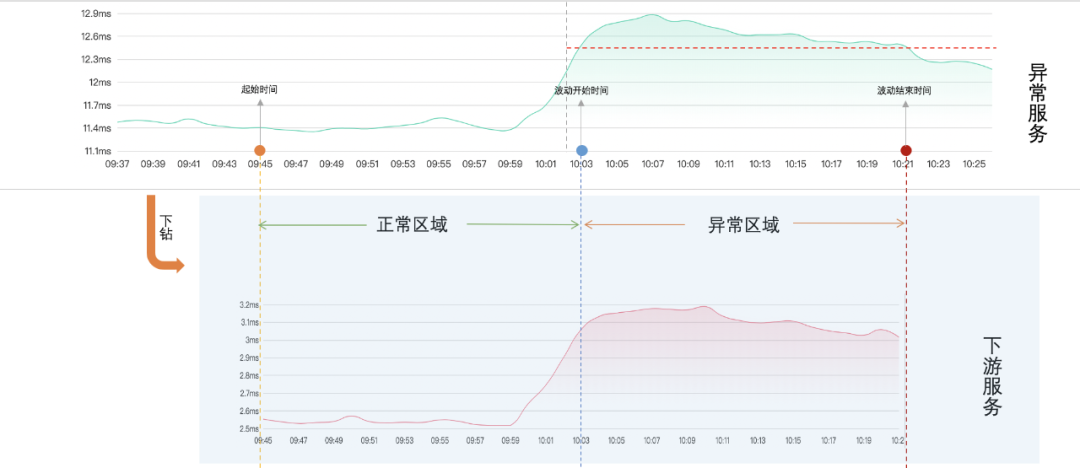
(5)服务下钻: 根据起始时间~波动结束时间,对异常服务按组件和服务名下钻,得到下游服务时间线,如下图:
(6)计算正常区域平均值: 下游服务的前半段是正常区域,后半段是异常区域,先求出正常区域的平均值,如下图:
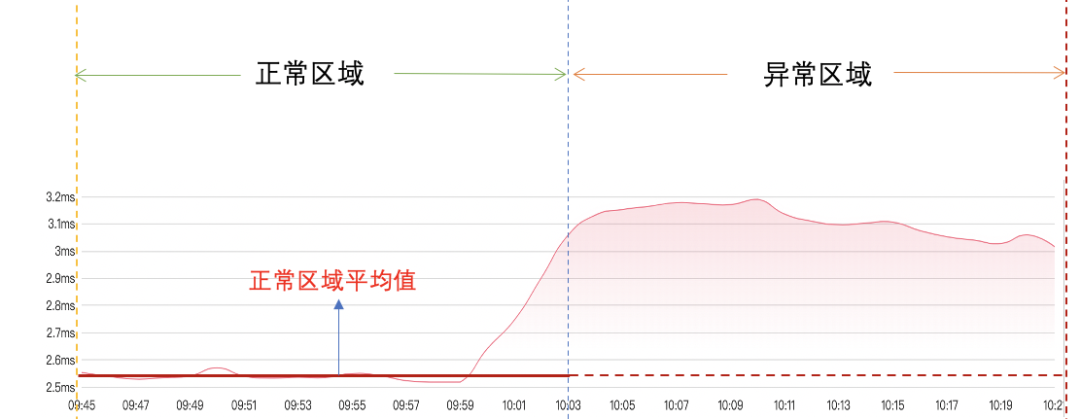
。
(7)计算异常区域波动方差: 根据异常区域波动点与正常区域均值之间的波动计算波动方差和波动比率,如下图: 。
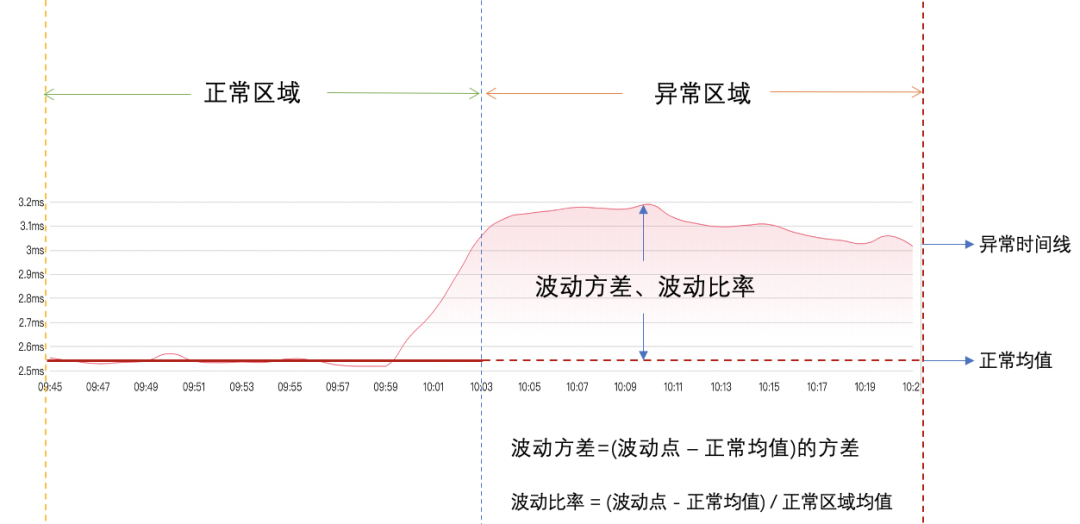
。
(8)时间线过滤: 过滤掉波动方向相反、波动比率小于总波动比率的1/10的时间线,排除正常时间线,如下图:
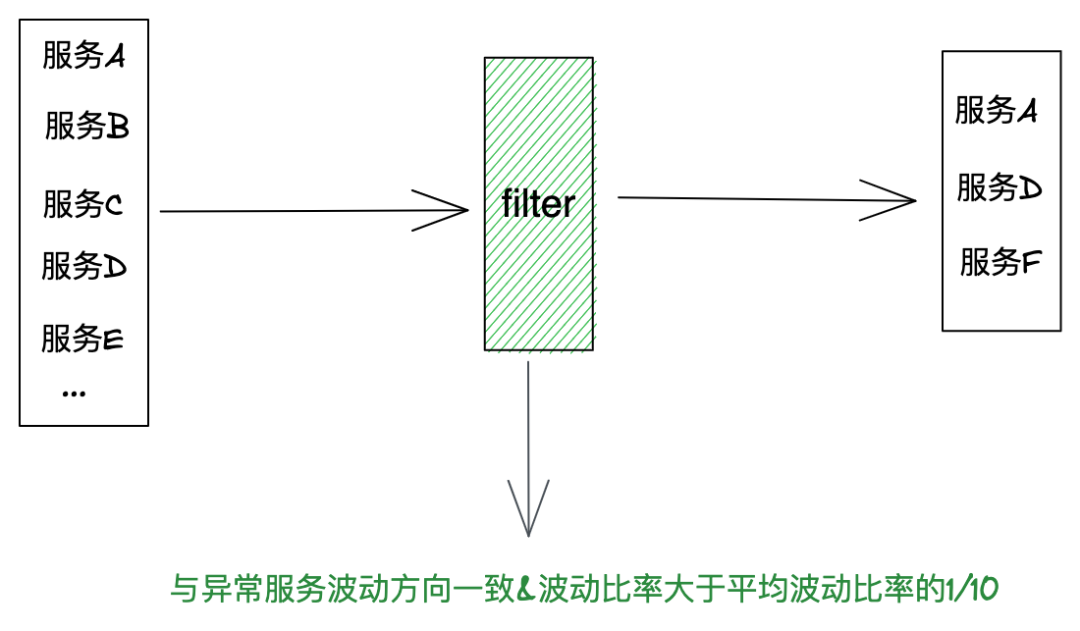
。
(9)对剩余下钻时间线进行 KMeans聚类 ,如下图:
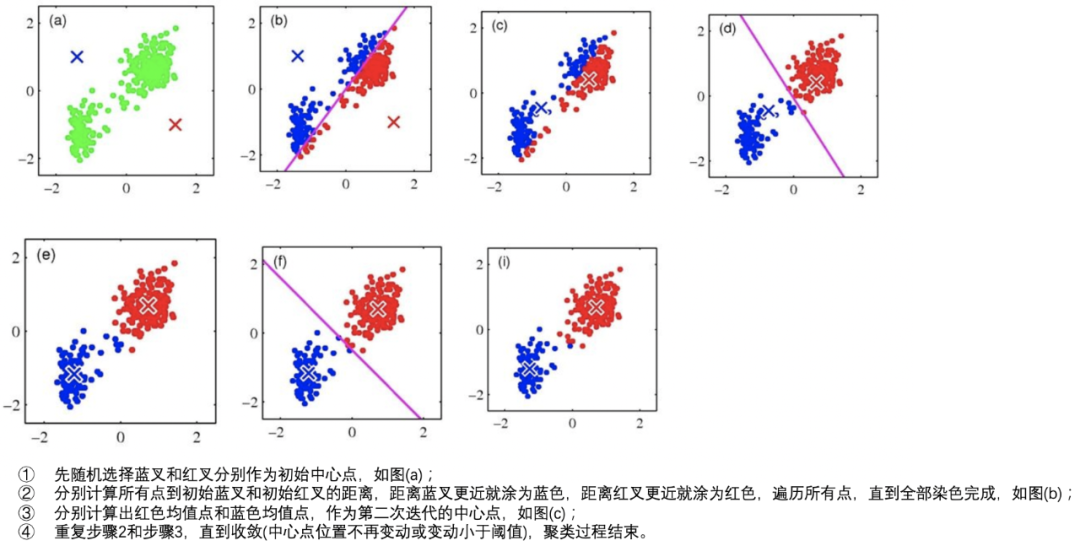
1、一种小而美的根因定位算法,利用方差量化波动,再通过排除法过滤掉波动小的下游,留下可能的下游作为原因。这种算法可以利用我们较完善的链路数据,可实现的成本低; 。
2、针对下游依赖场景的原因定位,准确率可达85%以上。但没有覆盖自身原因造成的故障(如GC、变更、机器问题等); 。
3、分析结果只能提供大概的线索,最后一公里还是需要人工介入; 。
4、故障定位算是AI领域的项目,开发方式与传统的敏捷开发有一定的区别:
角色职责: 领域专家(提出问题) → AI专家(算法预研) → 算法专家(算法实现和优化) → 应用专家(工程化开发) 。
操作步骤: 调研论文和git(业界、学界、同行) → 交流 → 实践 → 验证 。
项目实施: 复杂问题简单化,先做简单部分;通用问题特例化,找出具体案例,先解决具体问题.
1、故障预测: 当前我们主要关注服务出现异常后,如何检测异常和定位根因,未来是否能够通过一些现象提前预判故障,将介入的时间点左移,防患于未然; 。
2、数据质量治理: 当前我们的监控数据都有,但数据质量却参差不齐,而且数据格式的差异很大(比如日志数据和指标数据),我们在做机器学习或AIOps时,想要从中找出一些有价值的规律,其实挺难的; 。
3、经验知识化: 当前我们的专家经验很多都在运维和开发同学的脑海中,如果将这些经验知识化,对于机器学习或AIOps将是一笔宝贵的财富; 。
4、从统计算法往AI算法演进: 我们故障定位现在实际用的是统计算法,并没有用到AI。统计往往是一种强关系描述,而AI偏向弱关系,可以以统计算法为主,然后通过AI算法优化的方式.
。
参考资料 。
[1] Dapper, a Large-Scale Distributed Systems Tracing Infrastructure[EB/OL],2010-04-01. 。
[2] Holt-Winters Forecasting for Dummies (or Developers)[EB/OL],2016-01-29 . 。
[3] k-means clustering[EB/OL],2021-03-09. 。
最后此篇关于vivo故障定位平台的探索与实践的文章就讲到这里了,如果你想了解更多关于vivo故障定位平台的探索与实践的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
28
4
 0
0
接上篇 通过一个示例形象地理解C# async await 非并行异步、并行异步、并行异步的并发量控制 前些天写了两篇关于C# async await异步的博客, 第一篇博客看的人多,点
前言 在 SwiftUI 中,我们可以通过添加不同的交互来使我们的应用程序更具交互性,这些交互可以响应我们的点击,点击和滑动。 今天,我们将回顾SwiftUI基本手势:
今年我一直在想,2022年我想做些什么,做哪方面的改变,这周末在家终于想到了! 2021 轻描淡写 年底就一直想对2021年写一篇总结的,起码不得写个千八百字,可是思来想去不知道怎么写,直到最后都没想
已关闭。此问题不符合Stack Overflow guidelines 。目前不接受答案。 要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于 Stack Overflow 来说是偏离主题的,因为
在 Eclipse 中使用 Java 进行开发时,它非常方便:您可以像自己一样附加源代码并探索核心 Java 代码。在 Visual Studio 中,我知道只有在调试时才能查看 .net 源代码(我
我正在尝试创建自己的字符串数据类型,谁能告诉我 typedef 和初始化做错了什么。 #include #include typedef char string[10]; int main(){
我期待开发一些东西来分析在服务器上运行的应用程序的 JVM 线程,要求如下: 访问在单独应用程序中运行的所有线程 打印线程栈 了解事件的详细信息 - 记录执行时间和方法详细信息(在特定线程中执行) 我
是否可以探索 Android 内部存储?我需要这个用于调试目的,以帮助我的开发工作。 最佳答案 您可以在模拟器上,或在 Root设备上。只是 adb shell 连接设备,然后从那里导航。 关于and
我有一个使用大量外键的 innoDB 表,但我们只想从中查找一些基本信息。 我做了一些研究,但还是迷路了。 如何判断我的主机是否有 Sphinx已经安装了吗?我没看到作为表格存储的选项方法(即 inn
我有一个创建列表的 GWT 代码(作为结果的网格),我将样式设置为 CSS 类,如 .test tr { height: 26px; } 现在...如果在渲染未完成或网格没有元素时我需要从代码
我需要使用 Javascript 和 HTML 为 Rally 敏捷工具开发一个 View 。我没有处理过在我作为开发人员的新职业中经常使用的网络语言。 我只是在探索他们的 API,但不知道如何探索他
我想了解 Hadoop 而不是一个黑盒子。我想探索 Hadoop 代码本身。我怎样才能不从主干下载 bundle ,我应该从哪里开始?任何帮助都会很有帮助谢谢舒佳特 最佳答案 Hadoop 代码在 S
想象一下这样的情况。您获得了一些遗留代码或获得了一些新框架。您需要尽快调查并了解如何使用此代码。没有机会向以前的开发人员寻求帮助。什么是最佳实践/方法/方式/步骤/工具(首选 .NET Framewo
我注意到我的 git 存储库中的某些 makefile 缺少变量定义的问题,我想搜索所有提交历史以查找我的变量 TESTDIR 在变更集中出现的位置 我该怎么做? 干杯 最佳答案 你可以使用 git
有什么方法可以探索 GO 包吗? 在 java 中,我使用“javap java.lang.String”命令来查看类内部的方法。像这样,有没有命令是他们用 GO 语言写的? 我在谷歌中搜索了相同的内
我注意到 docker 我需要了解容器内发生了什么或其中存在哪些文件。一个示例是从 docker 索引下载图像 - 您不知道图像包含什么,因此无法启动应用程序。 理想的情况是能够通过 ss
近日,华为 分析服务 6.9.0版本发布,正式上线 探索能力 。开发者可自由定义与配置分析模型,支持报告实时预览,数据洞察体验更加灵活与便捷. 新上线的探索能力中,有漏斗分析、事件归因、会话路径分析
我有一个 4 列的 excel 2010 电子表格。 A 列:我销售的产品的 UPC 代码列表。大约300行。 B 列:公式(稍后会详细介绍) C 列:另一个 UPC 代码列表。这些 UPC 代码大约
我有 3 个表格如下: CREATE TABLE USER_STATUS ("UID" varchar2(7), "STAT_ID" varchar2(11)) ; INSERT ALL IN
有什么方法可以探索 java 脚本对象(如 telerik 菜单或任何其他第 3 方对象)的属性和/或功能?我可以通过调试和破坏然后在 watch 中添加对象或在 VS 中使用智能感知来实现。 我使用

我是一名优秀的程序员,十分优秀!