
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 28
28
 4
4


最近在看 SQL SERVER 2008 查询性能优化 ,书中说当一个表创建了聚集索引,那么表中的行会按照主键索引的顺序物理排列,这里有一个关键词叫: 物理排列 ,如果不了解底层原理,真的会被忽悠过去,其实仔细想一想不可能实现严格的 物理排列 ,那对性能是非常大的损害,本篇我们就从底层出发聊一聊到底是怎么回事.
如果用 C# 代码来演示严格的物理排列,大概是这样的.
static void Main(string[] args)
{
List<int> list = new List<int>() {1,2,4,5 };
list.Insert(2, 3);
Console.WriteLine(string.Join(",", list));
}
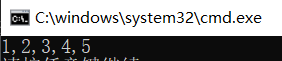
从代码看我用 Insert 将 3 插入到了 list 集合中形成了物理有序,但不要忘了 Insert 的复杂度是 O(N),而且还要将 3 后面的数据整体挪动,可以参考源码中的 Array.Copy 方法.
public void Insert(int index, T item)
{
if (_size == _items.Length)
{
EnsureCapacity(_size + 1);
}
if (index < _size)
{
Array.Copy(_items, index, _items, index + 1, _size - index);
}
_items[index] = item;
_size++;
_version++;
}
现在你可以想一想,如果我们每次在 Insert 的时候 SQLSERVER 都要将数据页上的数据往后挪,那这个性能有多差?
为了方便讲述,先创建一个测试表,插入 4 条记录,再创建一个聚集索引,sql 代码如下:
IF OBJECT_ID('t') IS NOT NULL DROP TABLE t;
CREATE TABLE t (a CHAR(5), b INT)
INSERT INTO t(a,b) VALUES('aaaaa',1);
INSERT INTO t(a,b) VALUES('ddddd',4);
INSERT INTO t(a,b) VALUES('ccccc',3);
INSERT INTO t(a,b) VALUES('eeeee',5);
CREATE CLUSTERED INDEX idx_a ON t(a);
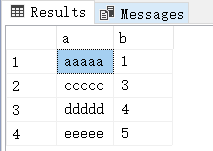
从图中看数据果然是有序的,严格的按照 a , c, d , e 排序,接下来用 dbcc 观察下在底层数据页上这几条记录是不是物理有序的? 查询 SQL 如下:
DBCC TRACEON(3604)
DBCC IND(MyTestDB,t,-1)
DBCC PAGE(MyTestDB,1,472,2)
Page数据页的输出结果如下:
PAGE: (1:472)
PAGE HEADER:
Page @0x000002C6E75D0000
m_pageId = (1:472) m_headerVersion = 1 m_type = 1
m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x4
m_objId (AllocUnitId.idObj) = 269 m_indexId (AllocUnitId.idInd) = 256
Metadata: AllocUnitId = 72057594055557120
Metadata: PartitionId = 72057594048348160 Metadata: IndexId = 1
Metadata: ObjectId = 850102069 m_prevPage = (0:0) m_nextPage = (0:0)
pminlen = 13 m_slotCnt = 4 m_freeCnt = 8024
m_freeData = 160 m_reservedCnt = 0 m_lsn = (49:1616:23)
m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0
m_tornBits = 0 DB Frag ID = 1
Allocation Status
GAM (1:2) = ALLOCATED SGAM (1:3) = NOT ALLOCATED PFS (1:1) = 0x40 ALLOCATED 0_PCT_FULL
DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGED
DATA:
Memory Dump @0x000000DF137F8000
000000DF137F8000: 01010000 04000001 00000000 00000d00 00000000 ....................
000000DF137F8014: 00000400 0d010000 581fa000 d8010000 01000000 ........X...........
000000DF137F8028: 31000000 50060000 17000000 00000000 00000000 1...P...............
000000DF137F803C: 00000000 01000000 00000000 00000000 00000000 ....................
000000DF137F8050: 00000000 00000000 00000000 00000000 10000d00 ....................
000000DF137F8064: 61616161 61010000 00030000 10000d00 63636363 aaaaa...........cccc
000000DF137F8078: 63030000 00030000 10000d00 64646464 64040000 c...........ddddd...
000000DF137F808C: 00030000 10000d00 65656565 65050000 00030000 ........eeeee.......
000000DF137F80A0: 00002121 21212121 21212121 21212121 21212121 ..!!!!!!!!!!!!!!!!!!
...
从 Memory Dump 区节的内存地址看,这四条记录果然是有序的, 。
接下来就是关键了,到底是不是物理有序,我们再插入一条 bbbbb 记录,看下会不会将 ccccc 所在的内存地址上的内容整体往后挪?测试的 sql 语句如下:
INSERT INTO t(a,b) VALUES('bbbbb',2);
SELECT * FROM t;
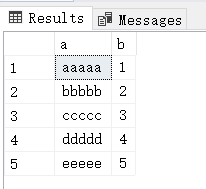
从图片看,貌似真的给塞进去了,那到底是不是这样呢? 带着好奇心再次观察下底层的 索引数据页 .
PAGE: (1:472)
PAGE HEADER:
Page @0x000002C6D76C4000
m_pageId = (1:472) m_headerVersion = 1 m_type = 1
m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x0
m_objId (AllocUnitId.idObj) = 269 m_indexId (AllocUnitId.idInd) = 256
Metadata: AllocUnitId = 72057594055557120
Metadata: PartitionId = 72057594048348160 Metadata: IndexId = 1
Metadata: ObjectId = 850102069 m_prevPage = (0:0) m_nextPage = (0:0)
pminlen = 13 m_slotCnt = 5 m_freeCnt = 8006
m_freeData = 176 m_reservedCnt = 0 m_lsn = (49:1640:2)
m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0
m_tornBits = 487522741 DB Frag ID = 1
Allocation Status
GAM (1:2) = ALLOCATED SGAM (1:3) = NOT ALLOCATED PFS (1:1) = 0x40 ALLOCATED 0_PCT_FULL
DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGED
DATA:
Memory Dump @0x000000DF0FDF8000
000000DF0FDF8000: 01010000 00000001 00000000 00000d00 00000000 ....................
000000DF0FDF8014: 00000500 0d010000 461fb000 d8010000 01000000 ........F...........
000000DF0FDF8028: 31000000 68060000 02000000 00000000 00000000 1...h...............
000000DF0FDF803C: b5010f1d 01000000 00000000 00000000 00000000 ....................
000000DF0FDF8050: 00000000 00000000 00000000 00000000 10000d00 ....................
000000DF0FDF8064: 61616161 61010000 00030000 10000d00 63636363 aaaaa...........cccc
000000DF0FDF8078: 63030000 00030000 10000d00 64646464 64040000 c...........ddddd...
000000DF0FDF808C: 00030000 10000d00 65656565 65050000 00030000 ........eeeee.......
000000DF0FDF80A0: 10000d00 62626262 62020000 00030000 00002121 ....bbbbb.........!!
000000DF0FDF80B4: 21212121 21212121 21212121 21212121 21212121 !!!!!!!!!!!!!!!!!!!!
...
000000DF0FDF9FF4: 21219000 80007000 a0006000 !!....p...`.
OFFSET TABLE:
Row - Offset
4 (0x4) - 144 (0x90)
3 (0x3) - 128 (0x80)
2 (0x2) - 112 (0x70)
1 (0x1) - 160 (0xa0)
0 (0x0) - 96 (0x60)
从 Memory Dump 节的内存地址看, bbbbb 并没有插入到 aaaaa 和 cccccc 之间,而是写入到页面尾部的空闲空间中,接下来就有一个问题了,为什么 sql 输出中是有序的呢?怎么做到的? 如果你了解 Page 的 Slot 布局,你会发现 Slot1 指向的就是 bbbbb 这条记录的首地址,画一张图就是这样.
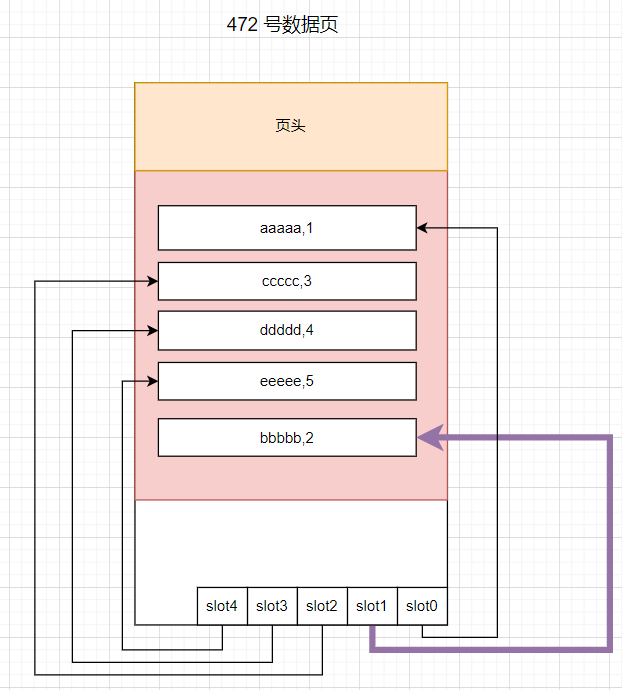
从图中我们就明白了最终的原理,当 Insert 时,SQLSERVER 并没有对表记录重排,而只是将指向的 Slot 槽位进行了重排,将物理无序做成了一种逻辑有序.
其实大家只要往高性能上想,肯定不会实现物理有序的,太伤性能了,在 物理无序 上抽象出一层 逻辑有序 不失为一种好办法.
最后此篇关于SQLSERVER的主键索引真的是物理有序吗?的文章就讲到这里了,如果你想了解更多关于SQLSERVER的主键索引真的是物理有序吗?的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
28
4
 0
0
在我的 Windows 类库(由 MVC 网站使用)中,我安装了 NugetPackage Microsoft.SqlServer.Types (Spatial)。 现在,我正在使用 ado.net
测试sql: 复制代码代码如下: SET STATISTICS IO ON SET STATISTICS TIME ON SELECT COUNT(1)&n
我正在从 SqlConnection 构建 DbContext。当我使用它时,我收到以下错误: The Entity Framework provider type 'System.Data.Enti
我使用dotNet 4.5创建了WCF服务。数据库层是使用Entity Framework 6构建的。 我使用IIS 8托管了该服务。它运行正常。 现在,我需要使用Windows窗体客户端使用该服务,
我正在尝试从 SqlServer 1 上的 sql 数据库中导出一些表。在我们的内部网 LAN(就在我旁边)中有一个我制作的临时 Sql Server,称为 SqlServer 2。 我不想备份整个数
Error 1 Copying file bin\EntityFramework.SqlServer.xml to obj\Debug\Package\PackageTmp\bin\Entit
我正在尝试使用 SMO 通过 Powershell 恢复数据库,但是当我尝试定义和使用服务器对象时,出现以下错误: Cannot convert argument "srv", with value:
出于某种原因,我需要将我的表列之一从“NOT NULL”更新为“NULL”。命令很简单: ALTER TABLE TBLOGDOCMESSAGE ALTER COLUMN PROCESSID BIGI
我想知道我正在尝试做的事情是否可行。我相信它是在 TSQL 中使用 PIVOT 函数,但对 PIVOT 函数没有足够的经验来知道从哪里开始。 基本上,我正在尝试采用以下名为 #tmpbudgetdat
我正在尝试将子查询作为带有条件的列。 我从 SQL Server 得到的错误是: 子查询返回了 1 个以上的值。当子查询跟随 =、!=、、>= 或当子查询用作表达式时,这是不允许的。 我正在选择更多的
我有一个正在查询的 SQL 服务器数据库,我只想在特定行为空时获取信息。我使用了一个 where 语句,例如: WHERE database.foobar = NULL 它不返回任何东西。但是,我知道
1、拼接字符串(整个字符串不分割)步骤: 首先在字符串的前后加单引号; 字符串中的变量以'''+@para+'''在字符串中表示; 若在执行时存在类型转换错误,则应用相应的类型
说明: 收缩日志的原因有很多种,有些是考虑空间不足,有些则是应用程序限制导致的。 ?
Rand()函数是系统自带的获取随机数的函数,可以直接运行select rand() 获取0~1之间的float型的数字。 如果想要获取0~100之间的整数随机数,可以这样使用 select ro
将以下内容保存为 openSql.bat 双击运行即可 复制代码 代码如下: @echo ========= SQL Server Ports =================== @ech
新增的APPLY表运算符把右表表达式应用到左表表达式中的每一行。它不像JOIN那样先计算那个表表达式都可以,APPLY必选先逻辑地计算左表达式。这种计算输入的逻辑顺序允许吧右表达式关联到左表表达式。
SQL Server本身提供了这么一个DMV来返回这些信息,它就是sys.dm_exec_sessions 。 比如在我的机器上做一下查询: 复制代码 代码如下: SELECT * FROM
尽管从技术上讲,其它排名函数的计算与ROW_NUMBER类似,但它们的的实际应用却少很多。RANK和DENSE——RANK主要用于排名和积分。NTILE更多地用于分析。 先创建一个示例表: 复制
1、文件和文件组的含义与关系 每个数据库有一个主数据文件.和若干个从文件。文件是数据库的物理体现。 文件组可以包括分布在多个逻辑分区的文件,实现负载平衡。文件组允许对文件进行分组,以便于管理和数据的
我想很多人都知道,在oracle里面,存储过程里面可以传入数组(如int[]),也就是说,可以传多条记录到数据,从而一起更新。减少数据库的请求次数。 但SqlServer呢?bulk Insert这

我是一名优秀的程序员,十分优秀!