
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 29
29
 4
4


训练模型过程中,经常需要追踪一些性能指标的变化情况,以便了解模型的实时动态,例如:回归任务中的MSE、分类任务中的Accuracy、生成对抗网络中的图片、网络模型结构可视化…… 除了追踪外,我们还希望能够将这些指标以动态图表的形式可视化显示出来.
TensorFlow的附加工具Tensorboard就完美的提供了这些功能。不过现在经过Pytorch团队的努力,TensorBoard已经集成到了Pytorch中,只要安装有pytorch也可以直接使用TensorBoard.
Tensorboard同时提供了后端数据记录功能和前端数据可视化功能。通过后端数据记录功能,我们可以将需要追踪的性能指标写入到指定文件;通过前端数据可视化功能,我们可是实时查看当前训练情况.
在接下来的文章中,将对TensorBoard的使用方法进行介绍,如果你还没有安装,可以通过一下命令进行安装。注意,虽然torch集成有TensorBoard,但是并不完整,需要使用下面命令完整安装后,才能开启TensorBoard的WEB应用.
pip install tensorboard
在通过上述命令完成tensorboard的安装后,即可在命令行调用tensorboard进行启动。如下所示:
tensorboard --logdir
=
./run
运行后输出如下:

logdir参数的作用是指定读取记录数据的目录,如果该目录内又多个记录文件,也会在页面中列表显示。另外从输出结果中,tensorboard默认从6006端口启动,当然也可以通过port参数指定端口,如下所示,我们指定从8088端口启动:
tensorboard --logdir
=
./run --port
8088
在浏览器地址栏,我们输入对应地址,打开页面如下:
现在之所以提示这些信息,是因为我们还没有记录过任何数据.
SummaryWriter是tensorboard中专门用来记录数据的类,只有通过SummaryWriter记录好的数据,才能在前端页面中展示。SummaryWriter类实例化时,主要参数如下:
log_dir (str):指定了数据保存的文件夹的位置,如果该文件夹不存在则会创建一个出来。如果没有指定的话,默认的保存的文件夹是./runs/现在的时间_主机名,例如:Dec16_21-13-54_DESKTOP-E782FS1,因此每次运行之后都会创建一个新的文件夹.
comment (string):给默认的log_dir添加的后缀,如果我们已经指定了log_dir具体的值,那么这个参数就不会有任何的效果 。
purge_step (int):TensorBoard在记录数据的时候有可能会崩溃,例如在某一个epoch中,进行到第$T + X$个step的时候由于各种原因(内存溢出)导致崩溃,那么当服务重启之后,就会从$T$个step重新开始将数据写入文件,而中间的$X$,即purge_step指定的step内的数据都被被丢弃.
import
torch
from
torch.utils.tensorboard
import
SummaryWriter
# 使用默认参数创建summary writer,程序将会自动生成文件名
writer
=
SummaryWriter
()
# 生成的文件路径为: runs/Dec16_21-13-54_DESKTOP-E782FS1/
# 创建summary writer时,指定文件路径
writer
=
SummaryWriter
(
"my_experiment"
)
# 生成的文件路径为: my_experiment
# 创建summary writer时,使用comment作为后缀
writer
=
SummaryWriter
(
comment
=
"LR_0.1_BATCH_16"
)
# folder location: runs/Dec16_21-19-59_DESKTOP-E782FS1LR_0.1_BATCH_16/
SummaryWriter类中定义了各式各样的方法,用于记录不同的数据,这些方法都已“add_”开头,我们先罗列一下这些方法:
writer
=
SummaryWriter
(
'runs'
)
for
i
in
SummaryWriter
.
__dict__
.
keys
():
if
i
.
startswith
(
"add_"
):
print
(
i
)
add_hparams
add_scalar
add_scalars
add_histogram
add_histogram_raw
add_image
add_images
add_image_with_boxes
add_figure
add_video
add_audio
add_text
add_onnx_graph
add_graph
add_embedding
add_pr_curve
add_pr_curve_raw
add_custom_scalars_multilinechart
add_custom_scalars_marginchart
add_custom_scalars
add_mesh
大体来说,所能记录的数据类型包括标量(scalar)、图像(image)、统计图(diagram)、视频(video)、音频(audio)、文本(text)、Embedding等等。下面我们一次来说说怎么记录这些不同类型的数据.
注意:训练过程中,添加loss等数据是,一定要通过item()方法,转换为标量之后才能添加到tensorboard中.
(1)add_scalar:一图一曲线 。
tag (str):用于给数据进行分类的标签,标签中可以包含父级和子级标签。例如给训练的loss以loss/train的tag,而给验证以loss/val的tag,这样的话,最终的效果就是训练的loss和验证的loss都被分到了loss这个父级标签下。而train和val则是具体用于区分两个参数的标识符(identifier)。此外,只支持二级标签.
global_step (int):首先,每个epoch中我们都会更新固定的step。因此,在一个数据被加入的时候,有两种step,第一种step是数据被加入时当前epoch已经进行了多少个step,第二种step是数据被加入时候,累计(包括之前的epoch)已经进行了多少个step。而考虑到我们在绘图的时候往往是需要观察所有的step下的数据的变化,因此global_step指的就是当前数据被加入的时候已经计算了多少个step。计算global_step的步骤很简单,就是$global\_step=epoch∗len(dataloader)+current\_step$ 。
wlltime (int):从SummaryWriter实例化开始到当前数据被加入时候所经历时间(以秒计算),默认是使用time.time()来自动计算的,当然我们也可以指定这个参数来进行修改。这个参数一般不改 。
writer
=
SummaryWriter
(
'runs/add_scalar'
)
for
n_iter
in
range
(
100
):
writer
.
add_scalar
(
'Loss/train'
,
np
.
random
.
random
(),
n_iter
)
writer
.
add_scalar
(
'Loss/test'
,
np
.
random
.
random
(),
n_iter
)
writer
.
add_scalar
(
'Accuracy/train'
,
np
.
random
.
random
(),
n_iter
)
writer
.
add_scalar
(
'Accuracy/test'
,
np
.
random
.
random
(),
n_iter
)
writer
.
close
()
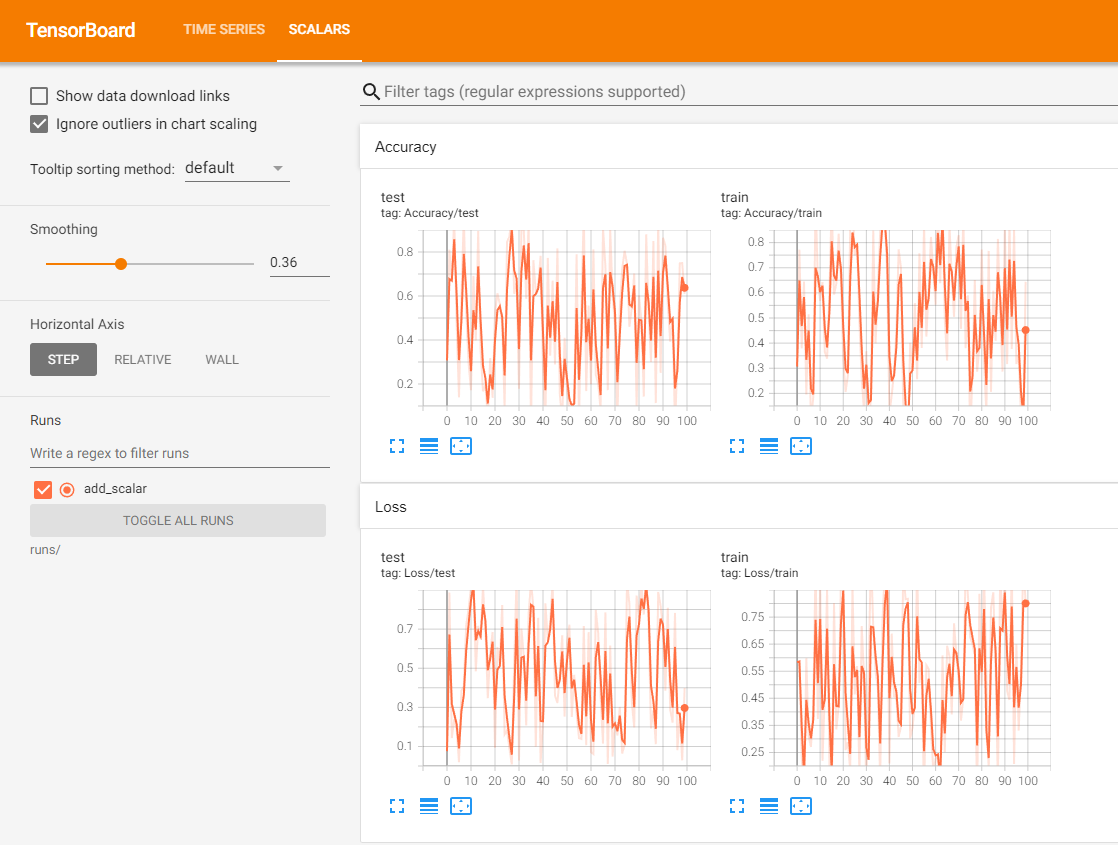
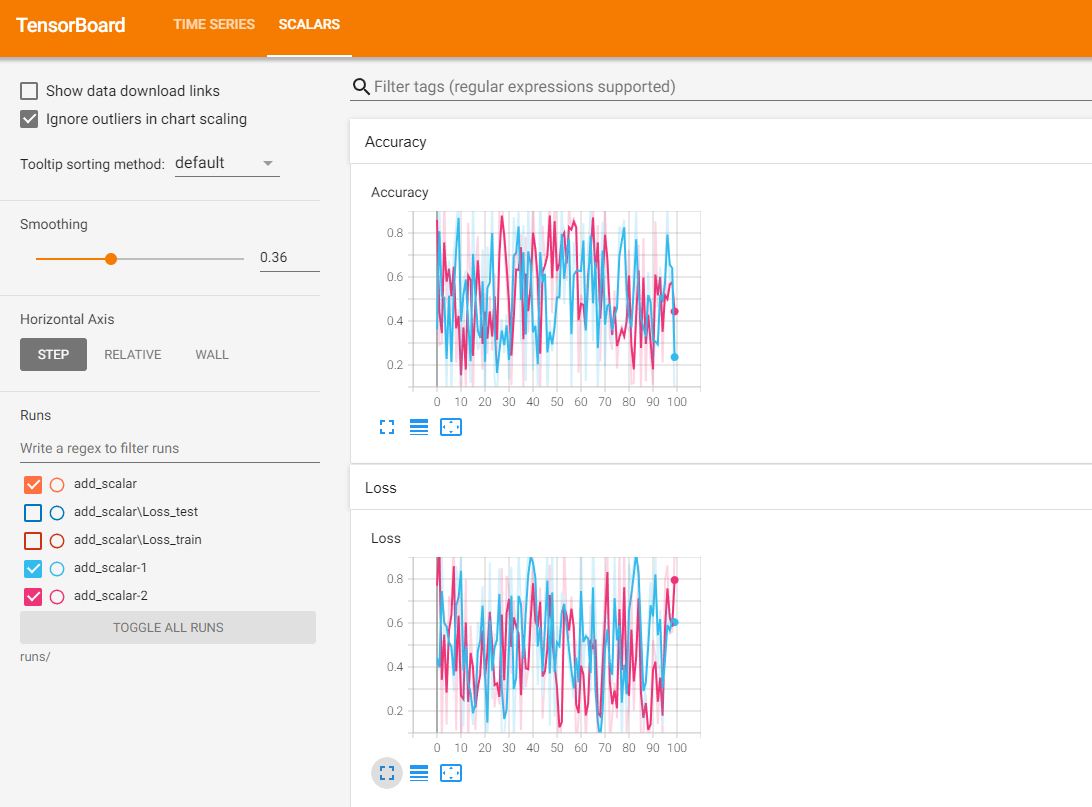
使用不同的SummaryWriter实例,相同的tag进行记录数据时,将可以实现在同一张图表中显示多条曲线。注意,实例化SummaryWriter时,必须指定不同的文件夹,否则多个记录数据虽然也是在同一图表中,但是图是混乱的.
# 两个Accuracy写入不同的文件夹中
writer1
=
SummaryWriter
(
'runs/add_scalar-1'
)
writer2
=
SummaryWriter
(
'runs/add_scalar-2'
)
for
n_iter
in
range
(
100
):
# 使用两个SummaryWriter分别记录LOSS和Accuracy,注意,tag必须一样
writer1
.
add_scalar
(
'Loss'
,
np
.
random
.
random
(),
n_iter
)
writer2
.
add_scalar
(
'Loss'
,
np
.
random
.
random
(),
n_iter
)
writer1
.
add_scalar
(
'Accuracy'
,
np
.
random
.
random
(),
n_iter
)
writer2
.
add_scalar
(
'Accuracy'
,
np
.
random
.
random
(),
n_iter
)
writer1
.
close
()
writer2
.
close
()
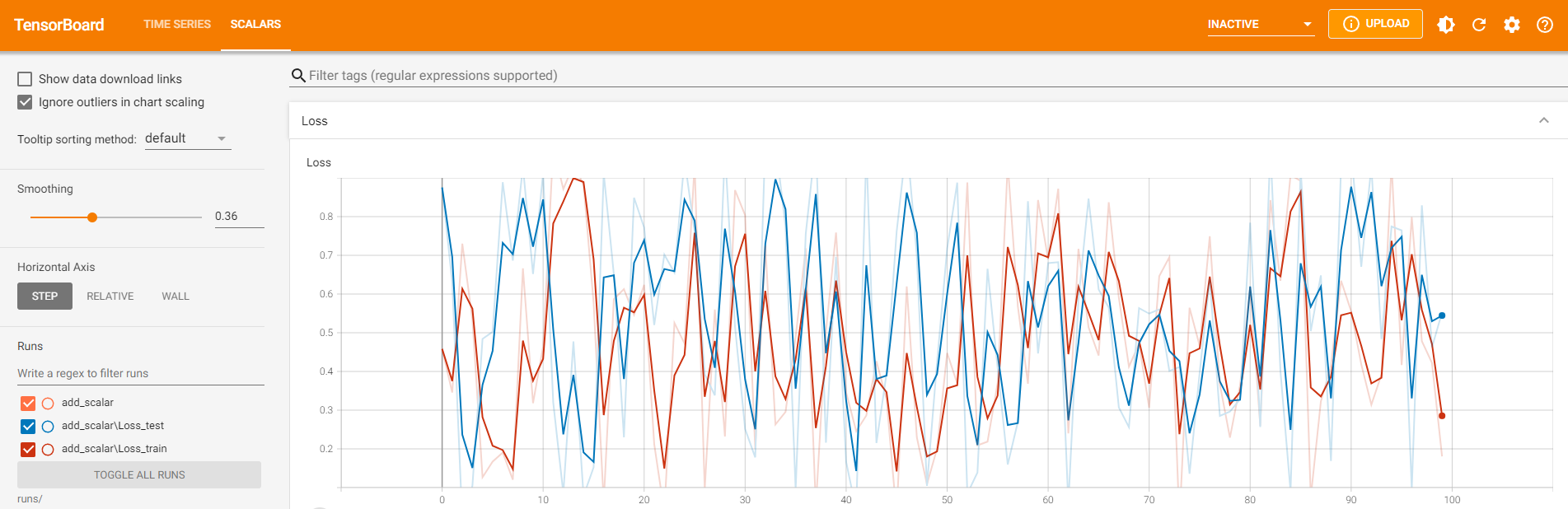
(2)add_scalars:一图多曲线 。
一张图显示多条曲线可以更加方便得对比数据,SummaryWriter中提供add_scalars方法实现在一张图中绘制多条曲线.
main_tag (str):多条曲线共用的标签 。
tag_scalar_dict (dict):多个需要记录的数据组成的键值对 。
global_step (int):训练的 step 。
walltime (float):从SummaryWriter实例化开始到当前数据被加入时候所经历时间(以秒计算) 。
writer
=
SummaryWriter
(
'runs/add_scalar'
)
for
n_iter
in
range
(
100
):
writer
.
add_scalars
(
'Loss'
,
{
'test'
:
np
.
random
.
random
(),
'train'
:
np
.
random
.
random
()},
n_iter
)
writer
.
close
()
(1)add_image 。
tag (str):数据标签 。
img_tensor:图像数据,数据类型可以使torch.Tensor, numpy.ndarray, string/blobname 。
global_step (int):训练的step 。
walltime (float):从SummaryWriter实例化开始到当前数据被加入时候所经历时间(以秒计算) 。
dataformats (str):图像数据的格式,可以是CHW, HWC, HW, WH等,默认为CHW,即Channel x Height x Width。通常来说,默认即可,但如果图像tensor不是CHW,就要通过这个参数指定了.
在本地文件夹有images下有多张图片,我们选择一张将其记录到tensorboard中:
from
torchvision.io
import
read_image
# 将图片打开为torch.Tensor类型
img
=
read_image
(
'images/0975.jpg'
)
img
.
shape
torch.Size([3, 224, 224])
可见,图片为CHW类型。我们将所有图片上传记录:
writer
=
SummaryWriter
(
'runs/add_image'
)
path_lst
=
[
os
.
path
.
join
(
'images'
,
i
)
for
i
in
os
.
listdir
(
'images'
)]
for
i
,
img
in
enumerate
(
path_lst
):
img
=
read_image
(
img
)
writer
.
add_image
(
'img'
,
img
,
i
)
writer
.
close
()
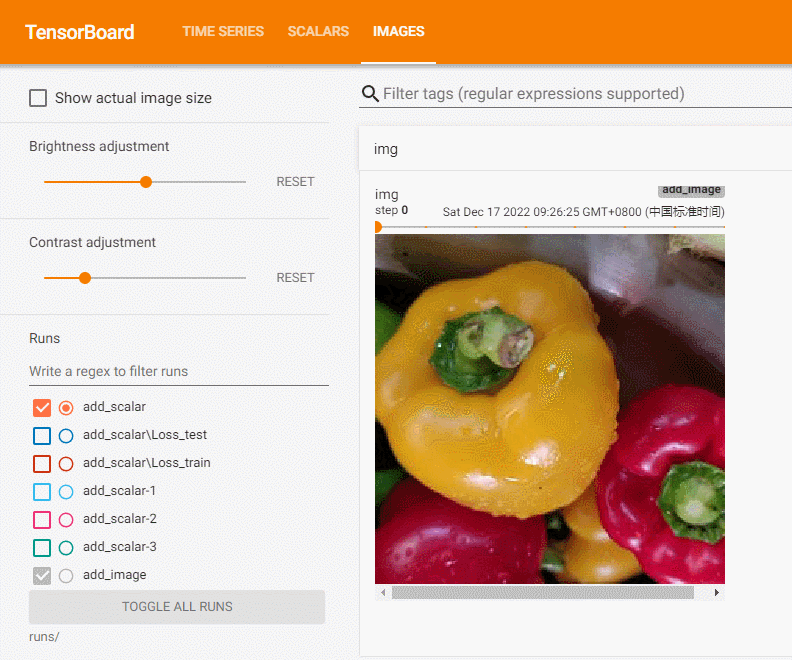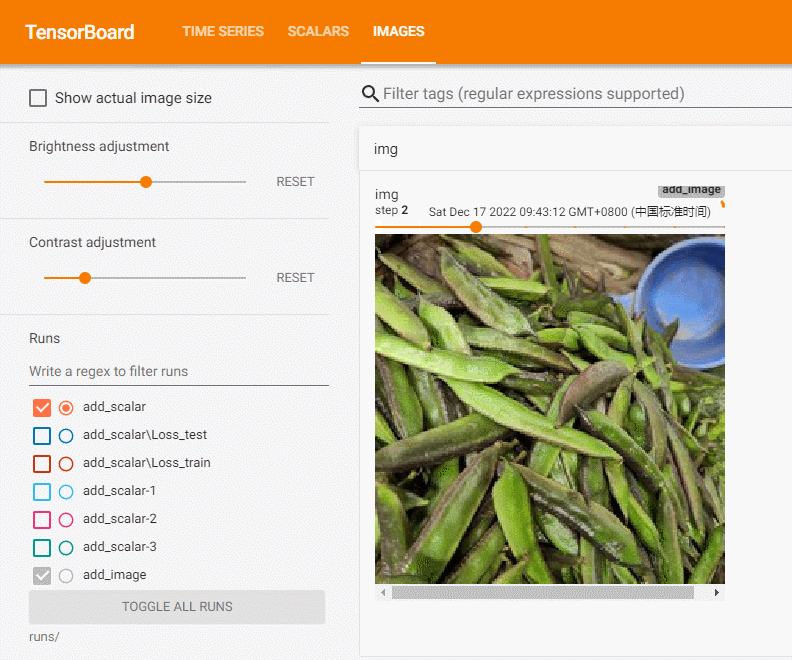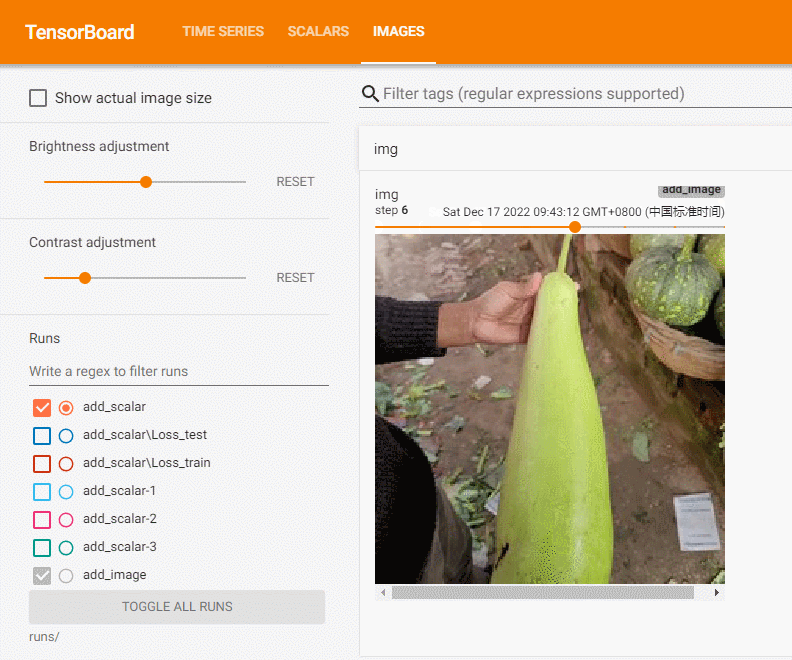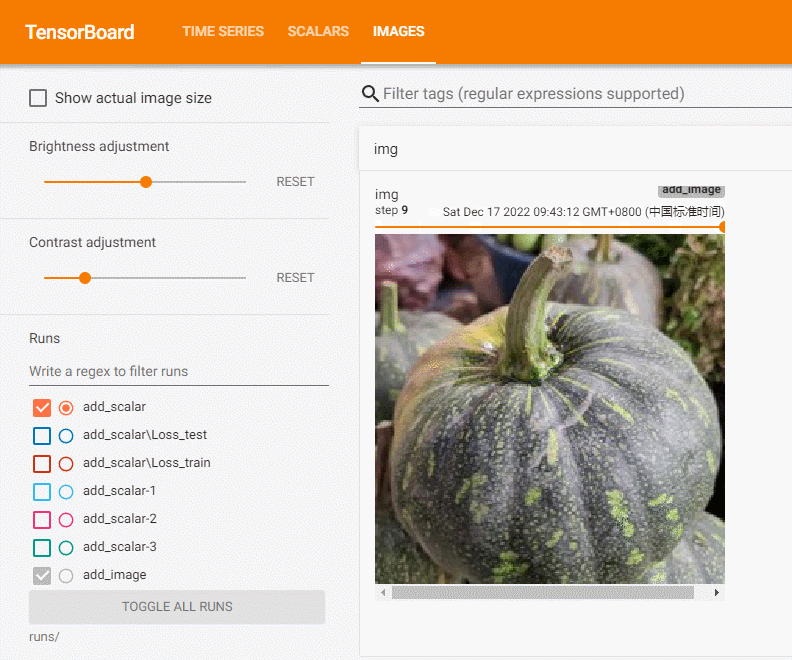
add_image方法一般情况下只能一次插入一张图片。如果要一次性插入多张图片,可以使用 torchvision 中的 make_grid 方法,将多张图片拼合成一张图片后,再调用 add_image 方法.
from
torchvision.utils
import
make_grid
path_lst
=
[
os
.
path
.
join
(
'images'
,
i
)
for
i
in
os
.
listdir
(
'images'
)]
img_lst
=
[]
for
i
,
img
in
enumerate
(
path_lst
):
img
=
read_image
(
img
)
img_lst
.
append
(
img
)
writer
=
SummaryWriter
(
'runs/add_image'
)
img_grid
=
make_grid
(
img_lst
,
nrow
=
5
)
writer
.
add_image
(
'img_grid'
,
img_grid
)
writer
.
close
()
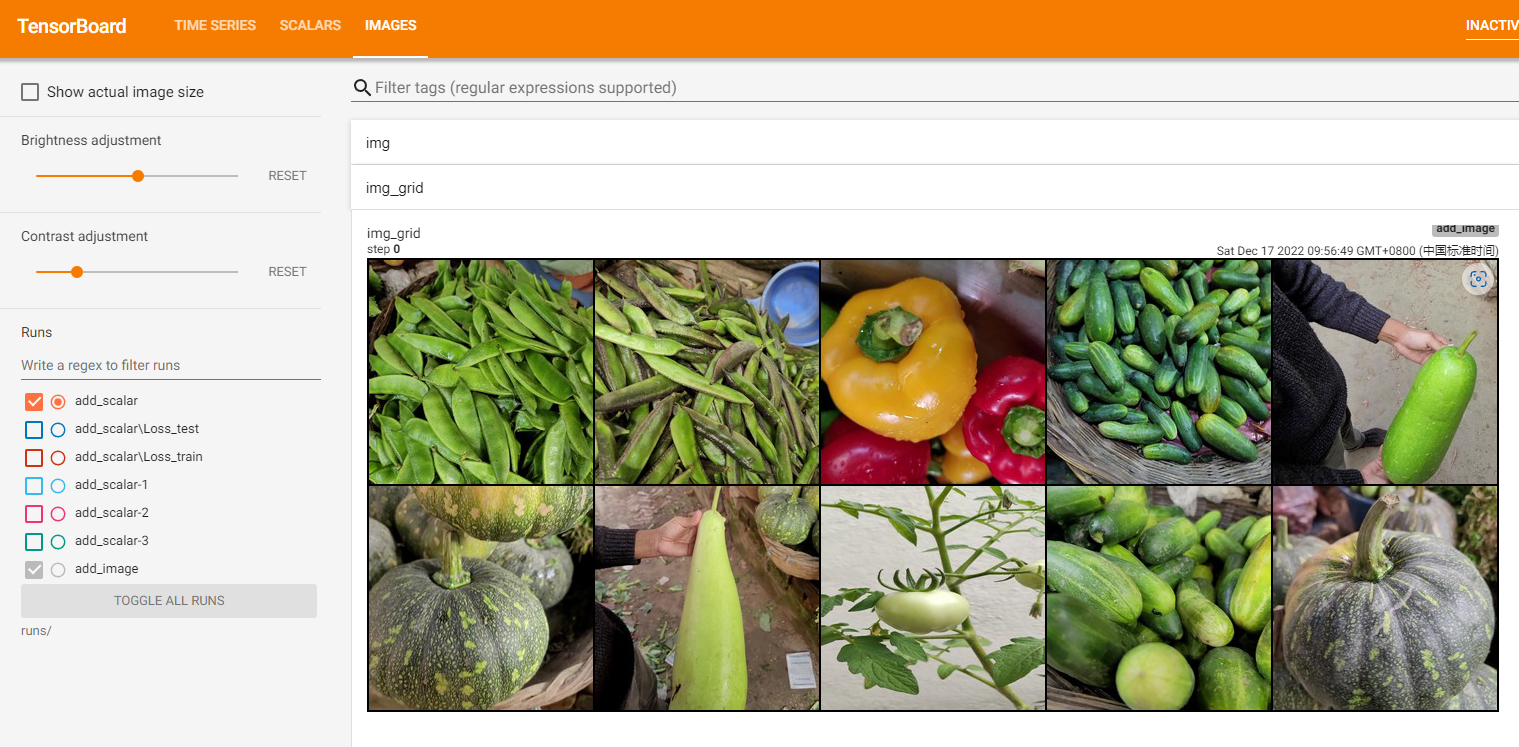
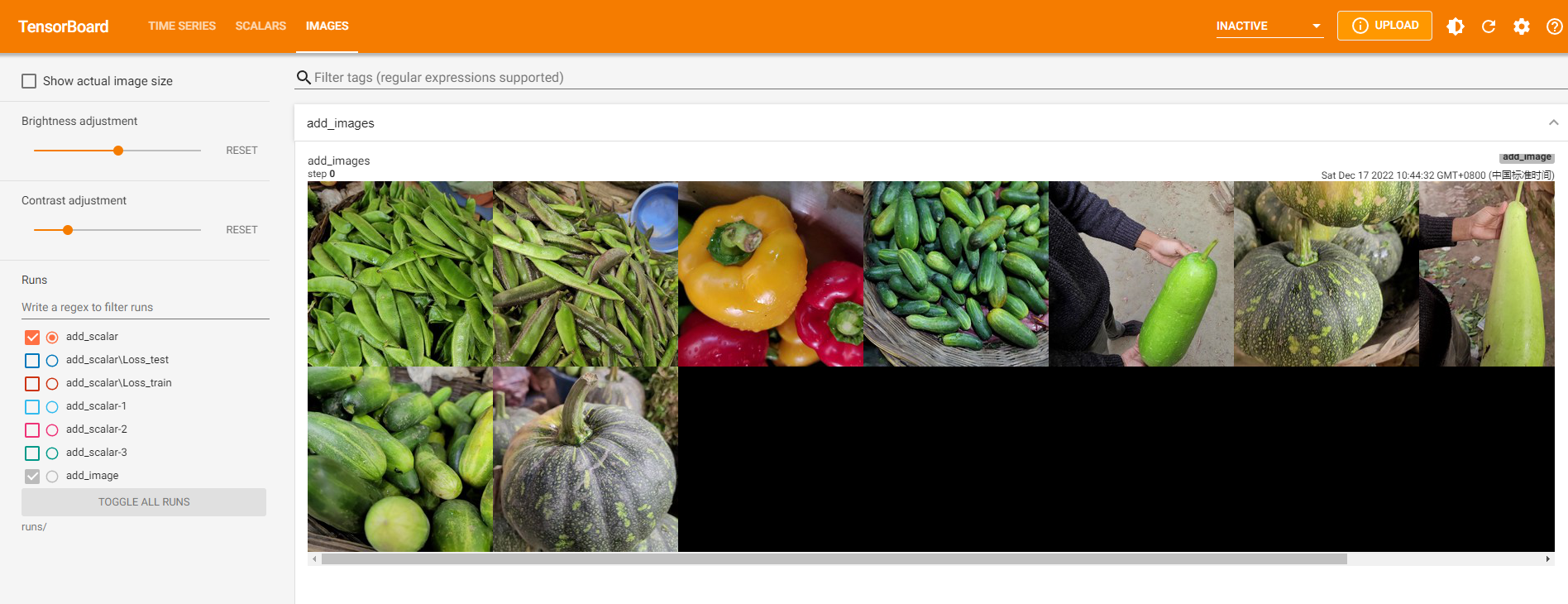
(2) add_images 。
add_images是tensorboard中提供直接一次性记录多张图片的方法,此方法参数与add_image基本一致,区别就在于记录的数据是多张图片组成的torch.Tensor或numpy.array, 数据的shape为(N,3,H,W),其中N为图片数量.
path_lst
=
[
os
.
path
.
join
(
'images'
,
i
)
for
i
in
os
.
listdir
(
'images'
)]
img_lst
=
[]
for
i
,
img
in
enumerate
(
path_lst
):
img
=
read_image
(
img
)
img_lst
.
append
(
img
)
imgs_tensor
=
torch
.
stack
(
img_lst
,
0
)
writer
=
SummaryWriter
(
'runs/add_image'
)
writer
.
add_images
(
'add_images'
,
imgs_tensor
)
writer
.
close
()
使用add_graph方法,可以绘制模型结构:
model (torch.nn.Module) :需要绘制的模型 。
input_to_model (torch.Tensor or list of torch.Tensor):传递给模型的一个数据 。
verbose (bool) :是否同时在命令行中绘制 。
import
torch.nn
as
nn
import
torch.nn.functional
as
F
from
torch.autograd
import
Variable
先定义一个模型:
class
Net1
(
nn
.
Module
):
def
__init__
(
self
):
super
(
Net1
,
self
)
.
__init__
()
self
.
conv1
=
nn
.
Conv2d
(
1
,
10
,
kernel_size
=
5
)
self
.
conv2
=
nn
.
Conv2d
(
10
,
20
,
kernel_size
=
5
)
self
.
conv2_drop
=
nn
.
Dropout2d
()
self
.
fc1
=
nn
.
Linear
(
320
,
50
)
self
.
fc2
=
nn
.
Linear
(
50
,
10
)
self
.
bn
=
nn
.
BatchNorm2d
(
20
)
def
forward
(
self
,
x
):
x
=
F
.
max_pool2d
(
self
.
conv1
(
x
),
2
)
x
=
F
.
relu
(
x
)
+
F
.
relu
(
-
x
)
x
=
F
.
relu
(
F
.
max_pool2d
(
self
.
conv2_drop
(
self
.
conv2
(
x
)),
2
))
x
=
self
.
bn
(
x
)
x
=
x
.
view
(
-
1
,
320
)
x
=
F
.
relu
(
self
.
fc1
(
x
))
x
=
F
.
dropout
(
x
,
training
=
self
.
training
)
x
=
self
.
fc2
(
x
)
x
=
F
.
softmax
(
x
,
dim
=
1
)
return
x
dummy_input
=
Variable
(
torch
.
rand
(
13
,
1
,
28
,
28
))
model
=
Net1
()
with
SummaryWriter
(
'runs/Net1'
)
as
w
:
w
.
add_graph
(
model
,
(
dummy_input
,
))
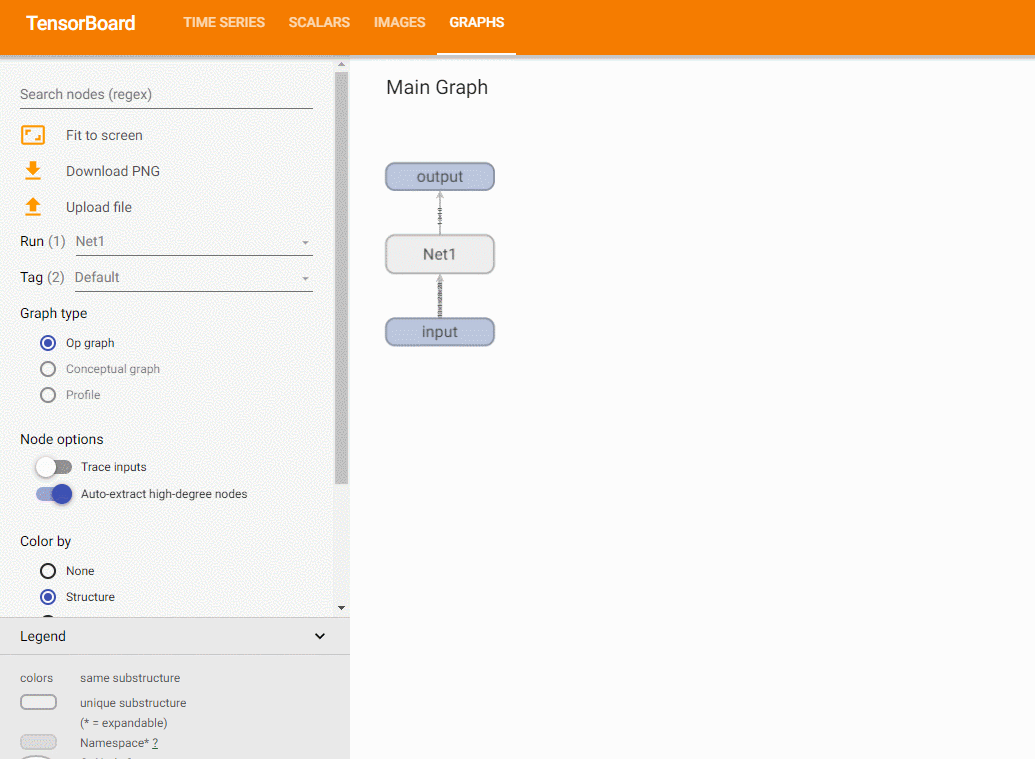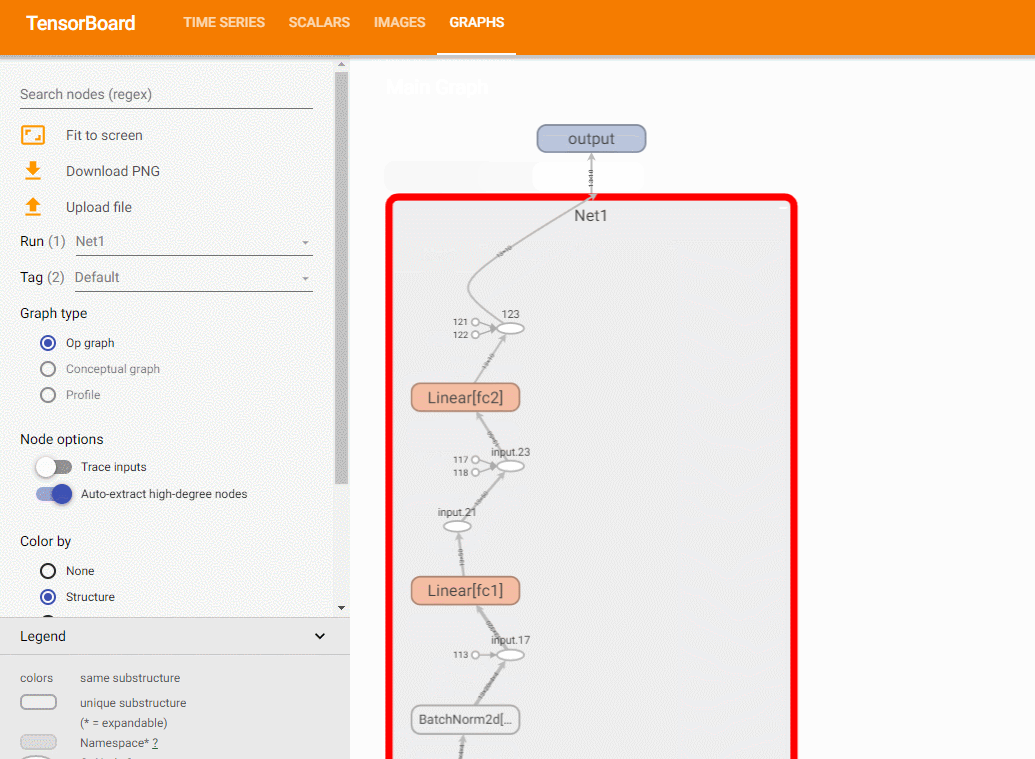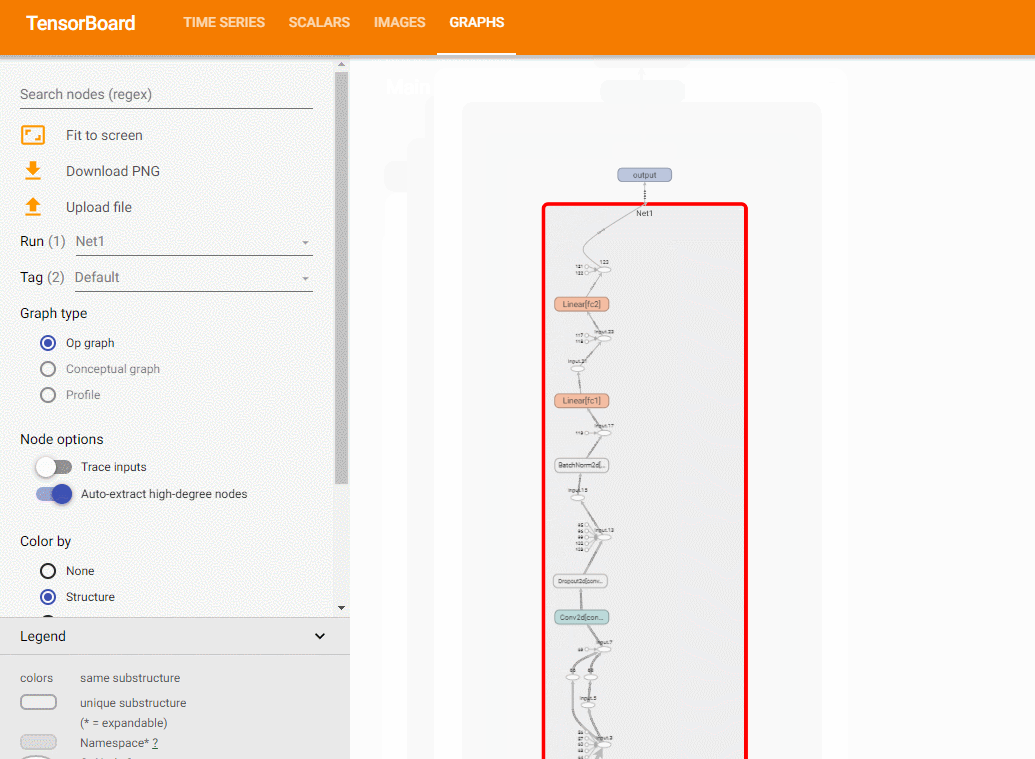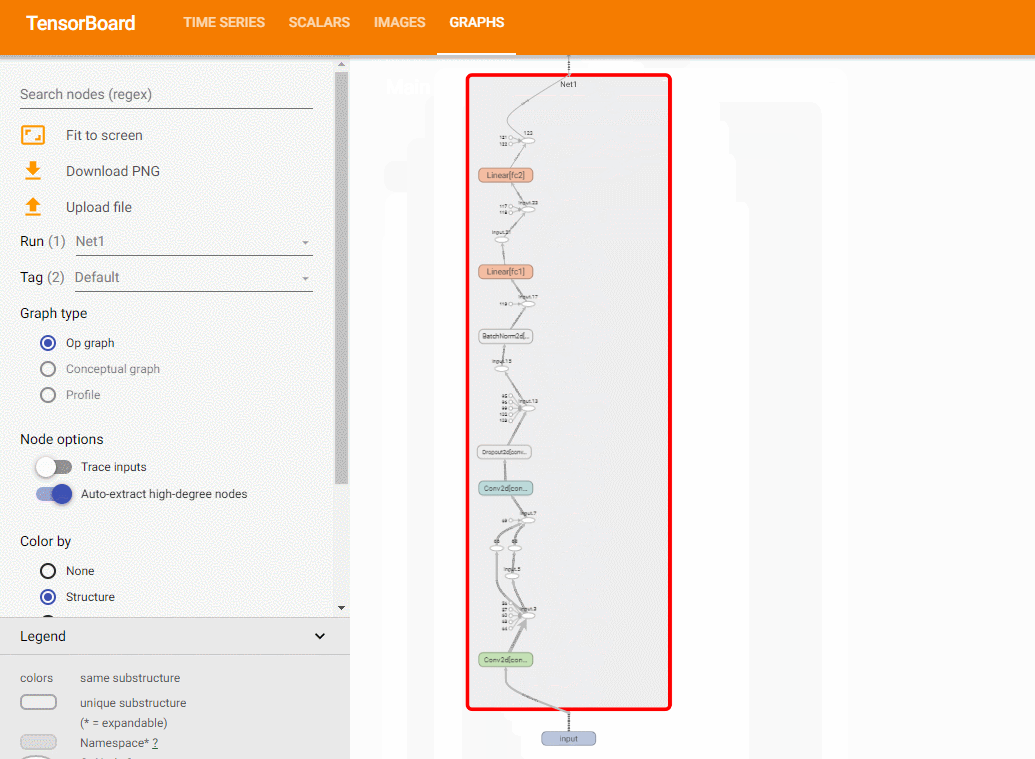
关于add_graph的例子,可以参考 这里 .
除了上述介绍到的方法外,tensorboard还提供许多其他方法,但我认为用到不多,这里就不介绍了,可以参考 官方文档 。另外,tensorboardX虽然不在维护了,但是却提供了很多使用tensorboard的例子可以学习,用法与pytorch的tensorboard完全一样,地址在 这里 。
最后此篇关于Pytorch优化过程展示:tensorboard的文章就讲到这里了,如果你想了解更多关于Pytorch优化过程展示:tensorboard的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
29
4
 0
0
我创建了一个邻接链表来显示城市之间的航类。该程序从 2 个文件中读取,一个包含城市名称,另一个包含不同航类的来源和目的地。我为所服务的城市创建了一个数组,并为数组的每个城市索引创建了一个连接城市的链接
我正在寻找可以让我更好地了解着色器在游戏中的用途、它们可以做什么,甚至更重要的是,它们不能做什么的资源。我了解图形管道的工作原理以及所有这些,并且我在 GLSL 中制作了一些非常基本的着色器(主要是为
我正在尝试根据单选按钮的选择制作显示两个 div 之一的东西。就单选按钮而言,我有这段代码: 然后是我的DIV: Purchase and Sale Purchase or Sale 我
谁能告诉我应该使用哪些 GitHub API 来检索 GitHub 展示?谢谢。 为了获取GitHub的列表showcases ,我应该使用什么确切的 GitHub API? 选择主题后,要检索该主题
我添加了 showcaseview jar 到我的项目中并像这样使用它 ShowcaseView.ConfigOptions co = new ShowcaseView.ConfigOptio
如果这不可能,那么在使用应用程序 3 分钟后我该如何做?这将用于“给我们评分”提醒,但我希望用户在要求他们评分之前有一些时间实际使用该应用程序。 最佳答案 - (BOOL)application:(U
除了选择 0-4 之间的随机数,如果它的 3 显示广告,是否有更好的方式来展示插页式广告? 此方法有其缺点,因为有时广告不会展示一段时间,有时它们会连续展示 3 次,这非常烦人。任何帮助将不胜感激!
我们正在尝试在我们的 Android 应用程序中监控 Firebase 云消息传递功能的状态。我们经常收到用户的反馈,他们说他们没有。 通过检查 Google Firebase 报告工具,我们发现在过
我制作了一个加载苹果测试广告的测试应用程序。我想知道如何加载实时广告而不是苹果测试广告。加载实时 iAd 的机制是什么?任何人都可以在这方面帮助我吗? 问候阿卜杜勒·萨马德 最佳答案 作为docume
我正在尝试让我的应用程序在屏幕上休眠。 我研究过 pmset 但没有成功,我什至尝试过 IOHIDPostEvent。我可以让 IOHIDPostEvent 按下 Eject 键,但设置 Shift
有没有办法使用 manim 显示 latex 表并为其设置动画? 例如 \begin{table}[] \centering \begin{tabular}{lllll} & & \multico
有没有办法使用 manim 显示 latex 表并为其设置动画? 例如 \begin{table}[] \centering \begin{tabular}{lllll} & & \multico
此代码调用新数据并将其放入 div,但不会替换旧的 htm。它只是增加了它。代码中有错误,但我找不到它们。如何获取它来替换 htm 文件而不仅仅是添加到数据中? .click(function ()
我想检测网络状态,当网络状态发生变化时,在当前 Controller 中显示错误 View 。但是使用协议(protocol)有一个问题。这是代码: private func networkingDe
我被要求创建一个小环境,展示使用 NoSQL - SQL 混合数据库相对于仅使用 SQL 数据库的优势。由于我的背景主要是管理/DevOps,所以我对数据库有基本的了解,但我从未做过这样的事情。 我想
我有一个使用模式的表单。似乎在任何浏览器上,当我单击图标(上传链接)时,模式弹出,然后页面向左缩小一点。 此处为实例:http://dev.handyvet.org/VetProsDevSite/_M
我正在准备一个大师类,向工作中的一组技术美 worker 员展示。小组中的每个人以前都使用 C/C++/MEL/MAXScript/Python 进行过编程。该类(class)的目的是共同将每个人的技
几天前,我将我的 Beta (公开 Beta 测试) 应用程序提升到生产环境。一切顺利。我可以在 Playstore 中搜索我的应用程序。但是有一个问题,Playstore 没有删除我的应用程序名称旁
使用 Bootstrap 3,我想要一个方形的平铺菜单,看起来像 Bootstrap 的缩略图 (http://getbootstrap.com/components/#thumbnails)。获得平
我想显示 admob Ad通过mopub sdk在我的一个 iPhone 应用程序中,但我找不到 API Password和API Key通过 Ad Mob。 谁能帮我将 Admob 网络集成到 mo

我是一名优秀的程序员,十分优秀!