
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


RocketMQ 优异的性能表现,必然绕不开其优秀的存储模型 .
这篇文章,笔者按照自己的理解 , 尝试分析 RocketMQ 的存储模型,希望对大家有所启发.
首先温习下 RocketMQ 架构.
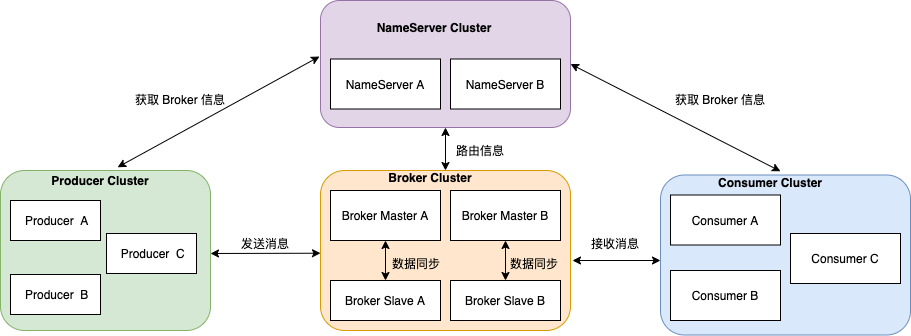
整体架构中包含四种角色
Producer :消息发布的角色,Producer 通过 MQ 的负载均衡模块选择相应的 Broker 集群队列进行消息投递,投递的过程支持快速失败并且低延迟.
Consumer :消息消费的角色,支持以 push 推,pull 拉两种模式对消息进行消费.
NameServer :名字服务是一个非常简单的 Topic 路由注册中心,其角色类似 Dubbo 中的 zookeeper ,支持 Broker 的动态注册与发现.
BrokerServer :Broker 主要负责消息的存储、投递和查询以及服务高可用保证 .
本文的重点在于分析 BrokerServer 的消息存储模型。我们先进入 broker 的文件存储目录 .

消息存储和下面三个文件关系非常紧密:
数据文件 commitlog 。
消息主体以及元数据的存储主体 ; 。
消费文件 consumequeue 。
消息消费队列,引入的目的主要是提高消息消费的性能 ; 。
索引文件 index 。
索引文件,提供了一种可以通过 key 或时间区间来查询消息.
RocketMQ 采用的是混合型的存储结构,Broker 单个实例下所有的队列共用一个数据文件(commitlog)来存储.
生产者发送消息至 Broker 端,然后 Broker 端使用同步或者异步的方式对消息刷盘持久化,保存至 commitlog 文件中。只要消息被刷盘持久化至磁盘文件 commitlog 中,那么生产者发送的消息就不会丢失.
Broker 端的后台服务线程会不停地分发请求并异步构建 consumequeue(消费文件)和 indexFile(索引文件).
RocketMQ 的消息数据都会写入到数据文件中, 我们称之为 commitlog .
所有的消息都会顺序写入数据文件,当文件写满了,会写入下一个文件 .

如上图所示,单个文件大小默认 1G , 文件名长度为 20 位,左边补零,剩余为起始偏移量,比如 00000000000000000000 代表了第一个文件,起始偏移量为 0 ,文件大小为1 G = 1073741824.
当第一个文件写满了,第二个文件为 00000000001073741824,起始偏移量为 1073741824,以此类推.
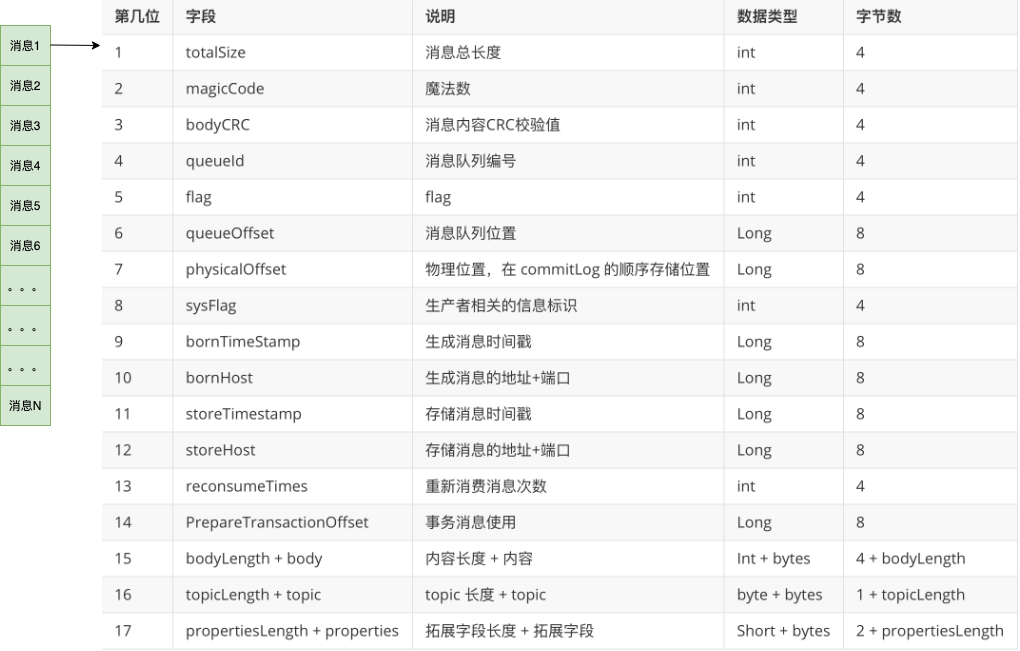
从上图中,我们可以看到消息是一条一条写入到文件,每条消息的格式是固定的.
这样设计有三点优势:
顺序写 。
磁盘的存取速度相对内存来讲并不快,一次磁盘 IO 的耗时主要取决于:寻道时间和盘片旋转时间,提高磁盘 IO 性能最有效的方法就是:减少随机 IO,增加顺序 IO .
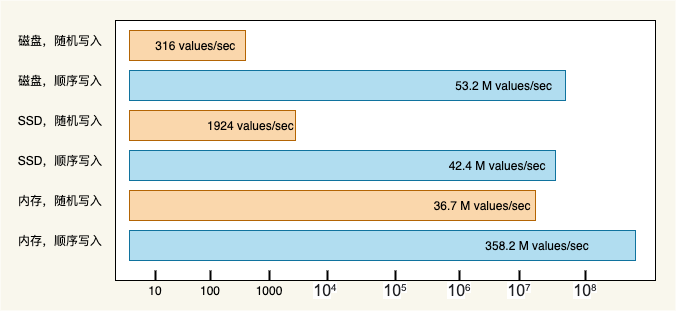
《 The Pathologies of Big Data 》这篇文章指出:内存随机读写的速度远远低于磁盘顺序读写的速度。磁盘顺序写入速度可以达到几百兆/s,而随机写入速度只有几百 KB /s,相差上千倍.
快速定位 。
因为消息是一条一条写入到 commitlog 文件 ,写入完成后,我们可以得到这条消息的物理偏移量.
每条消息的物理偏移量是唯一的, commitlog 文件名是递增的,可以根据消息的物理偏移量通过 二分查找 ,定位消息位于那个文件中,并获取到消息实体数据.
通过消息 offsetMsgId 查询消息数据 。
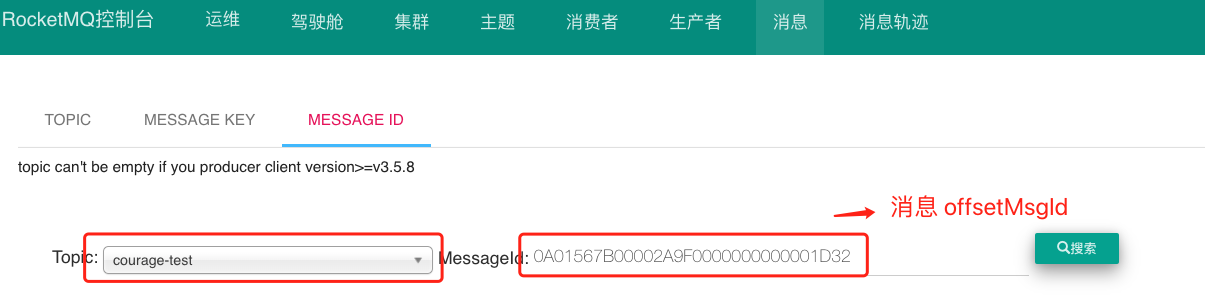
消息 offsetMsgId 是由 Broker 服务端在写入消息时生成的 ,该消息包含两个部分:
Broker 服务端 ip + port 8个字节; 。
commitlog 物理偏移量 8个字节 .
我们可以通过消息 offsetMsgId ,定位到 Broker 的 ip 地址 + 端口 ,传递物理偏移量参数 ,即可定位该消息实体数据.
在介绍 consumequeue 文件之前, 我们先温习下消息队列的传输模型- 发布订阅模型 , 这也是 RocketMQ 当前的传输模型.
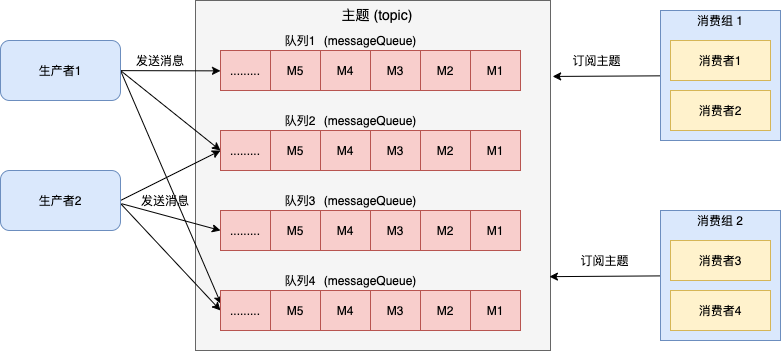
发布订阅模型具有如下特点:
因此, rocketmq 的文件设计必须满足发布订阅模型的需求.
那么仅仅 commitlog 文件是否可以满足需求吗 ?
假如有一个 consumerGroup 消费者,订阅主题 my-mac-topic ,因为 commitlog 包含所有的消息数据,查询该主题下的消息数据,需要遍历数据文件 commitlog , 这样的效率是极其低下的.
进入 rocketmq 存储目录,显示见下图:
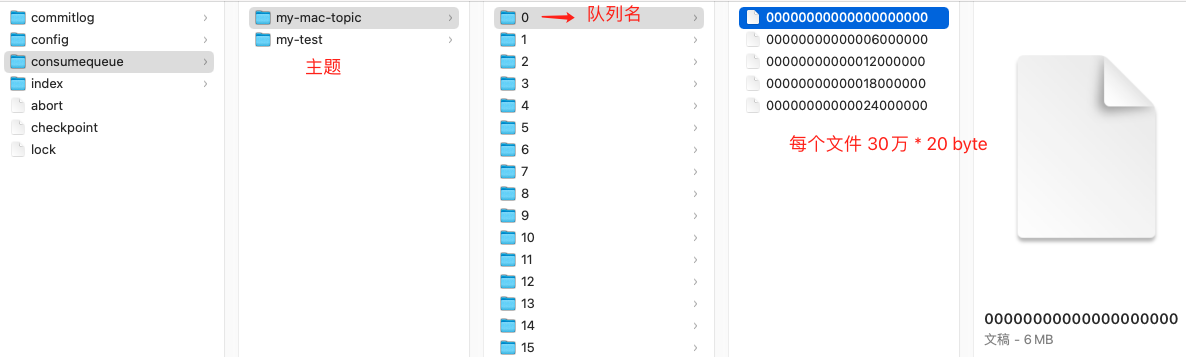

每个 consumequeue 包含 30 万个条目,每个条目大小是 20 个字节,每个文件的大小是 30 万 * 20 = 60万字节,每个文件大小约5.72M 。和 commitlog 文件类似,consumequeue 文件的名称也是以偏移量来命名的,可以通过消息的逻辑偏移量定位消息位于哪一个文件里.
消费文件按照 主题-队列 来保存 ,这种方式特别适配 发布订阅模型 .
消费者从 broker 获取订阅消息数据时,不用遍历整个 commitlog 文件,只需要根据逻辑偏移量从 consumequeue 文件查询消息偏移量 , 最后通过定位到 commitlog 文件, 获取真正的消息数据.
这样就可以简化消费查询逻辑,同时因为同一主题下,消费者可以订阅不同的队列或者 tag ,同时提高了系统的可扩展性.
每个消息在业务层面的唯一标识码要设置到 keys 字段,方便将来定位消息丢失问题。服务器会为每个消息创建索引(哈希索引),应用可以通过 topic、key 来查询这条消息内容,以及消息被谁消费.
由于是哈希索引,请务必保证key尽可能唯一,这样可以避免潜在的哈希冲突.
//订单Id
String orderId = "1234567890";
message.setKeys(orderId);
从开源的控制台中根据主题和 key 查询消息列表:
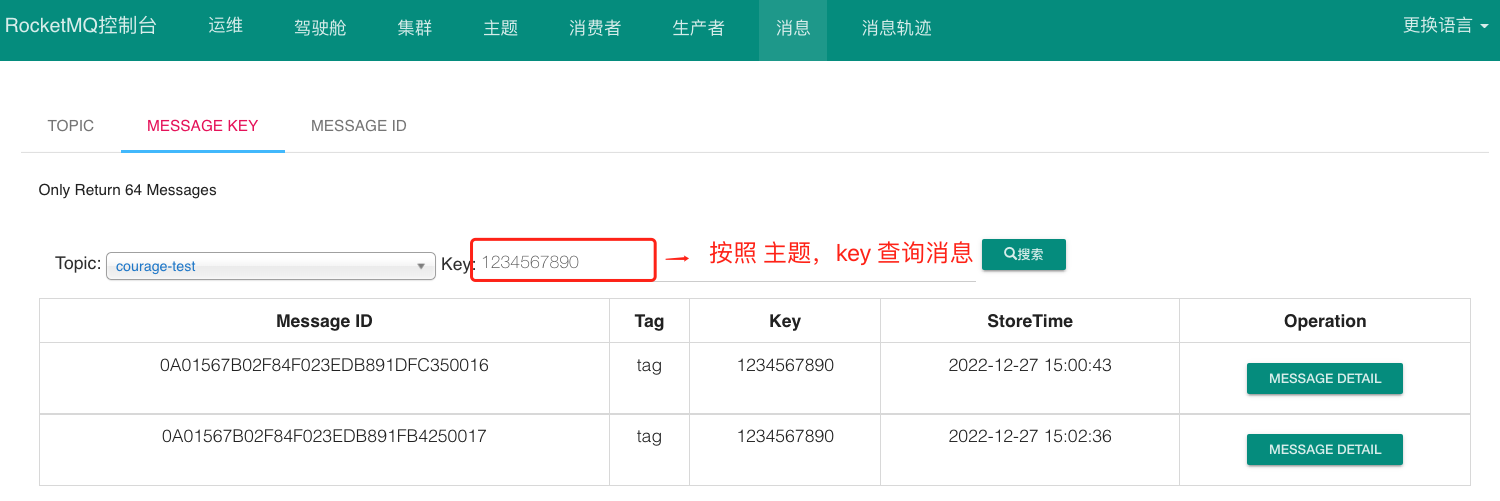
进入索引文件目录 ,如下图所以:
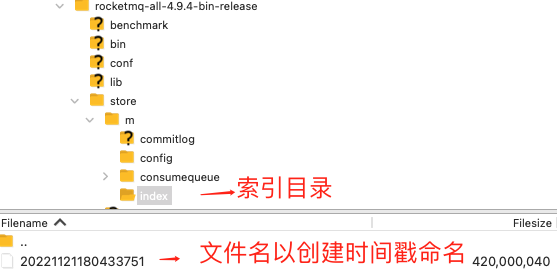
索引文件名 fileName 是以创建时的时间戳命名的,固定的单个 IndexFile 文件大小约为 400 M .
IndexFile 的文件逻辑结构类似于 JDK 的 HashMap 的 数组加链表 结构.
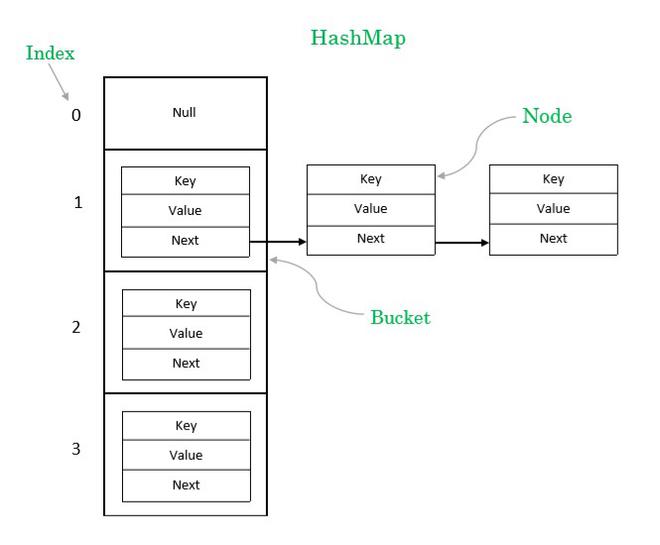
索引文件主要由 Header、Slot Table (默认 500 万个条目)、Index Linked List(默认最多包含 2000万个条目)三部分组成 .
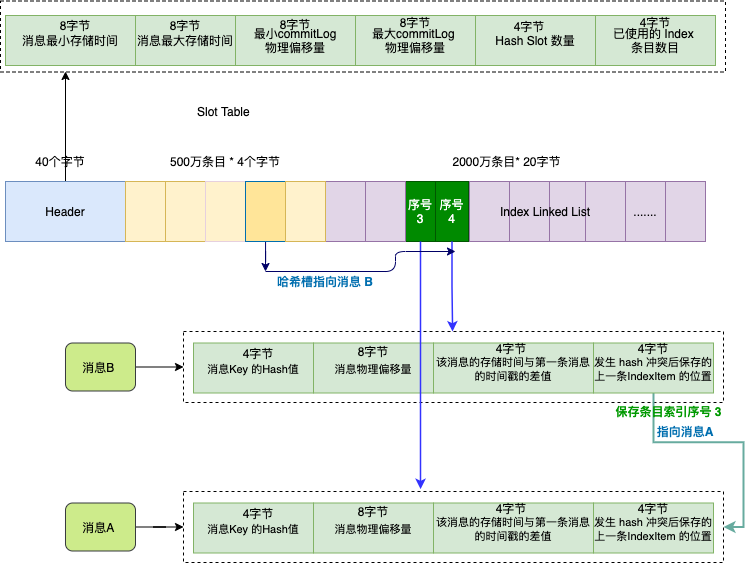
假如订单系统发送两条消息 A 和 B , 他们的 key 都是 "1234567890" ,我们依次存储消息 A , 消息 B .
因为这两个消息的 key 的 hash 值相同,它们对应的哈希槽(深黄色)也会相同,哈希槽会保存的最新的消息 B 的索引条目序号 , 序号值是 4 ,也就是第二个深绿色条目.
而消息 B 的索引条目信息的最后 4 个字节会保存上一条消息对应的索引条目序号,索引序号值是 3 , 也就是消息 A .
Databases are specializing – the “one size fits all” approach no longer applies ------ MongoDB设计哲学 。
RocketMQ 存储模型设计得非常精巧,笔者觉得每种设计都有其底层思考,这里总结了三点 :
如果我的文章对你有所帮助,还请帮忙 点赞、在看、转发 一下,你的支持会激励我输出更高质量的文章,非常感谢! 。

最后此篇关于终于弄明白了RocketMQ的存储模型的文章就讲到这里了,如果你想了解更多关于终于弄明白了RocketMQ的存储模型的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
可不可以命名为MVVM模型?因为View通过查看模型数据。 View 是否应该只与 ViewModelData 交互?我确实在某处读到正确的 MVVM 模型应该在 ViewModel 而不是 Mode
我正在阅读有关设计模式的文章,虽然作者们都认为观察者模式很酷,但在设计方面,每个人都在谈论 MVC。 我有点困惑,MVC 图不是循环的,代码流具有闭合拓扑不是很自然吗?为什么没有人谈论这种模式: mo
我正在开发一个 Sticky Notes 项目并在 WPF 中做 UI,显然将 MVVM 作为我的架构设计选择。我正在重新考虑我的模型、 View 和 View 模型应该是什么。 我有一个名为 Not
不要混淆:How can I convert List to Hashtable in C#? 我有一个模型列表,我想将它们组织成一个哈希表,以枚举作为键,模型列表(具有枚举的值)作为值。 publi
我只是花了一些时间阅读这些术语(我不经常使用它们,因为我们没有任何 MVC 应用程序,我通常只说“模型”),但我觉得根据上下文,这些意味着不同的东西: 实体 这很简单,它是数据库中的一行: 2) In
我想知道你们中是否有人知道一些很好的教程来解释大型应用程序的 MVVM。我发现关于 MVVM 的每个教程都只是基础知识解释(如何实现模型、 View 模型和 View ),但我对在应用程序页面之间传递
我想realm.delete() 我的 Realm 中除了一个模型之外的所有模型。有什么办法可以不列出所有这些吗? 也许是一种遍历 Realm 中当前存在的所有类型的方法? 最佳答案 您可以从您的 R
我正在尝试使用 alias 指令模拟一个 Eloquent 模型,如下所示: $transporter = \Mockery::mock('alias:' . Transporter::class)
我正在使用 stargazer 创建我的 plm 汇总表。 library(plm) library(pglm) data("Unions", package = "pglm") anb1 <- pl
我读了几篇与 ASP.NET 分层架构相关的文章和问题,但是读得太多后我有点困惑。 UI 层是在 ASP.NET MVC 中开发的,对于数据访问,我在项目中使用 EF。 我想通过一个例子来描述我的问题
我收到此消息错误: Inceptionv3.mlmodel: unable to read document 我下载了最新版本的 xcode。 9.4 版测试版 (9Q1004a) 最佳答案 您没有
(同样,一个 MVC 验证问题。我知道,我知道......) 我想使用 AutoMapper ( http://automapper.codeplex.com/ ) 来验证我的创建 View 中不在我
需要澄清一件事,现在我正在处理一个流程,其中我有两个 View 模型,一个依赖于另一个 View 模型,为了处理这件事,我尝试在我的基本 Activity 中注入(inject)两个 View 模型,
如果 WPF MVVM 应该没有代码,为什么在使用 ICommand 时,是否需要在 Window.xaml.cs 代码中实例化 DataContext 属性?我已经并排观看并关注了 YouTube
当我第一次听说 ASP.NET MVC 时,我认为这意味着应用程序由三个部分组成:模型、 View 和 Controller 。 然后我读到 NerdDinner并学习了存储库和 View 模型的方法
Platform : ubuntu 16.04 Python version: 3.5.2 mmdnn version : 0.2.5 Source framework with version :
我正在学习本教程:https://www.raywenderlich.com/160728/object-oriented-programming-swift ...并尝试对代码进行一些个人调整,看看
我正试图围绕 AngularJS。我很喜欢它,但一个核心概念似乎在逃避我——模型在哪里? 例如,如果我有一个显示多个交易列表的应用程序。一个列表向服务器查询匹配某些条件的分页事务集,另一个列表使用不同
我在为某个应用程序找出最佳方法时遇到了麻烦。我不太习惯取代旧 TLA(三层架构)的新架构,所以这就是我的来源。 在为我的应用程序(POCO 类,对吧??)设计模型和 DAL 时,我有以下疑问: 我的模
我有两个模型:Person 和 Department。每个人可以在一个部门工作。部门可以由多人管理。我不确定如何在 Django 模型中构建这种关系。 这是我不成功的尝试之一 [models.py]:

我是一名优秀的程序员,十分优秀!