
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 28
28
 4
4


@ 。
Nifi 官网地址 https://nifi.apache.org/ 。
Nifi 官网文档 https://nifi.apache.org/docs.html 。
Nifi GitHub源码地址 https://github.com/apache/nifi 。
Apache NiFi是一个易于使用、功能强大且可靠的系统,用于处理和分发数据,可以自动化管理系统间的数据流。最新版本为1.19.1 。
简单来说,NiFi是用来处理数据集成场景的数据分发。NiFi是基于Java的,使用Maven支持包的构建管理。 NiFi基于Web方式工作,后台在服务器上进行调度。用户可以为数据处理定义为一个流程,然后进行处理,后台具有数据处理引擎、任务调度等组件.
Apache NiFi支持数据路由、转换和系统中介逻辑的强大且可伸缩的有向图.
这种设计模型帮助NiFi成为构建强大且可伸缩的数据流的非常有效的平台,其好处如下:
NiFi的设计目的是充分利用它所运行的底层主机系统的功能,对IO、CPU、RAM高效使用,这种资源最大化在CPU和磁盘方面表现得尤为突出,详细信息在管理指南中的最佳实践和配置技巧中.
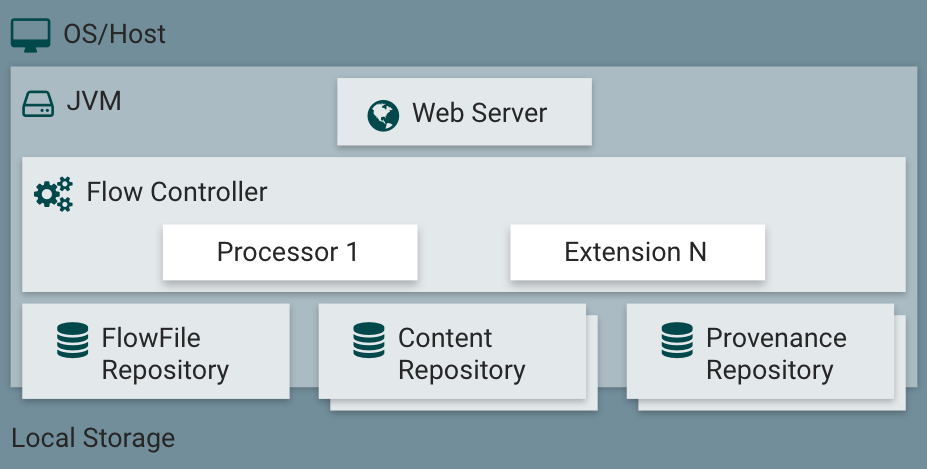
NiFi在主机操作系统上的JVM中执行,JVM上NiFi的主要组件如下
NiFi也能够在集群中运行,NiFi 采用了零领导者集群,NiFi集群中的每个节点在数据上执行相同的任务,但每个节点操作不同的数据集。Apache ZooKeeper选择一个节点作为Cluster Coordinator,故障转移由ZooKeeper自动处理。所有集群节点都向集群协调器报告心跳和状态信息。集群协调器负责断开和连接节点。此外,每个集群都有一个主节点,也由ZooKeeper选举产生。作为DataFlow管理器,可通过任何节点的用户界面(UI)与NiFi集群交互,操作更改复制到集群中的所有节点,允许多个入口点.
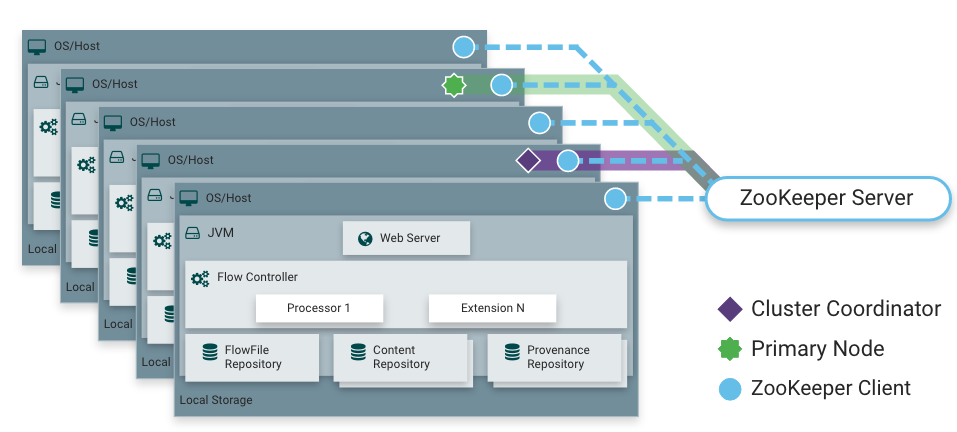
Nifi高级概述包括流管理、易用性、安全性、可扩展的体系结构和灵活的伸缩模型.
# 下载最新版本1.19.1的nifi
wget --no-check-certificate https://dlcdn.apache.org/nifi/1.19.1/nifi-1.19.1-bin.zip
# 由于下载很慢我就直接下载源码安装了,最低建议JDK 11.0.16、Apache Maven 3.8.6,最新需求是JDK 8 Update 251Apache Maven 3.6.0
wget
# 解压源码包
tar -xvf nifi-1.19.1.tar.gz
# 进入源码根目录
cd nifi-rel-nifi-1.19.1
# 执行编译命令
mvn clean install -DskipTests
等待编译完成 。
编译好的目录和包目录如下 。
# 复制编译好的安装包nifi-1.19.1-bin.zip
cp -rf nifi-1.19.1-bin.zip /home/commons/
cd /home/commons/
# 解压编译好的安装包
unzip nifi-1.19.1-bin.zip
# 进入安装目录
cd nifi-1.19.1
nifi主要配置文件在conf/nifi.properties,默认的https的端口为8443,修改host为本机IP地址 。
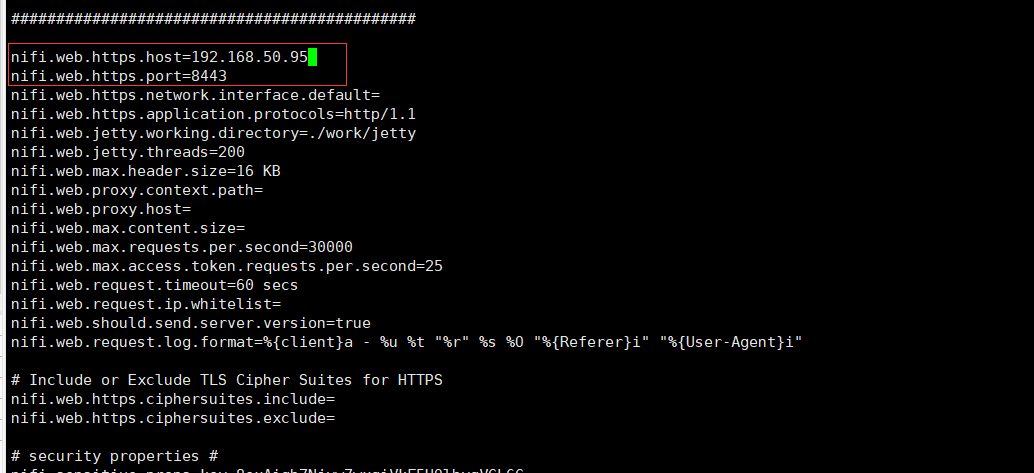
# 启动nifi
./bin/nifi.sh start
# 得等一小会时间后查看nifi进程状态
./bin/nifi.sh status
# 查看授权的密码信息
grep Generated logs/nifi-app*log
# 可以使用自定义凭证替换随机用户名和密码,使用如下命令
./bin/nifi.sh set-single-user-credentials <username> <password>
# 其他命令如下,停止nifi ./bin/nifi.sh stop,重启nifi./bin/nifi.sh restart

在web浏览器中打开以下链接以访问NiFi: https://192.168.50.95:8443/nifi ,看到登录页面后输入上面的用户名和密码就可以进入nifi的首页.
想到创建数据流必须了解可供使用的处理器类型,NiFi包含许多开箱即用的不同处理器,这些处理器提供了从许多不同系统摄取数据、路由、转换、处理、分割和聚合数据以及将数据分发到许多系统的功能。几乎在每一个NiFi发行版中,可用的处理器数量都会增加。因此将不尝试为每个可用的处理器命名,下面重点介绍一些最常用的处理器,并根据它们的功能对它们进行分类.
我们使用演示一个从本地源文件夹拷贝到本地目的文件夹,主要使用到GetFile文件数据摄取处理器和PutFile文件发送处理器.
GetFile文件数据摄取处理器,详细属性可以在官方文档https://nifi.apache.org/docs.html的左边处理器菜单下找,例如GetFile处理器,从目录中的文件创建FlowFiles,NiFi将忽略它至少没有读权限的文件 。
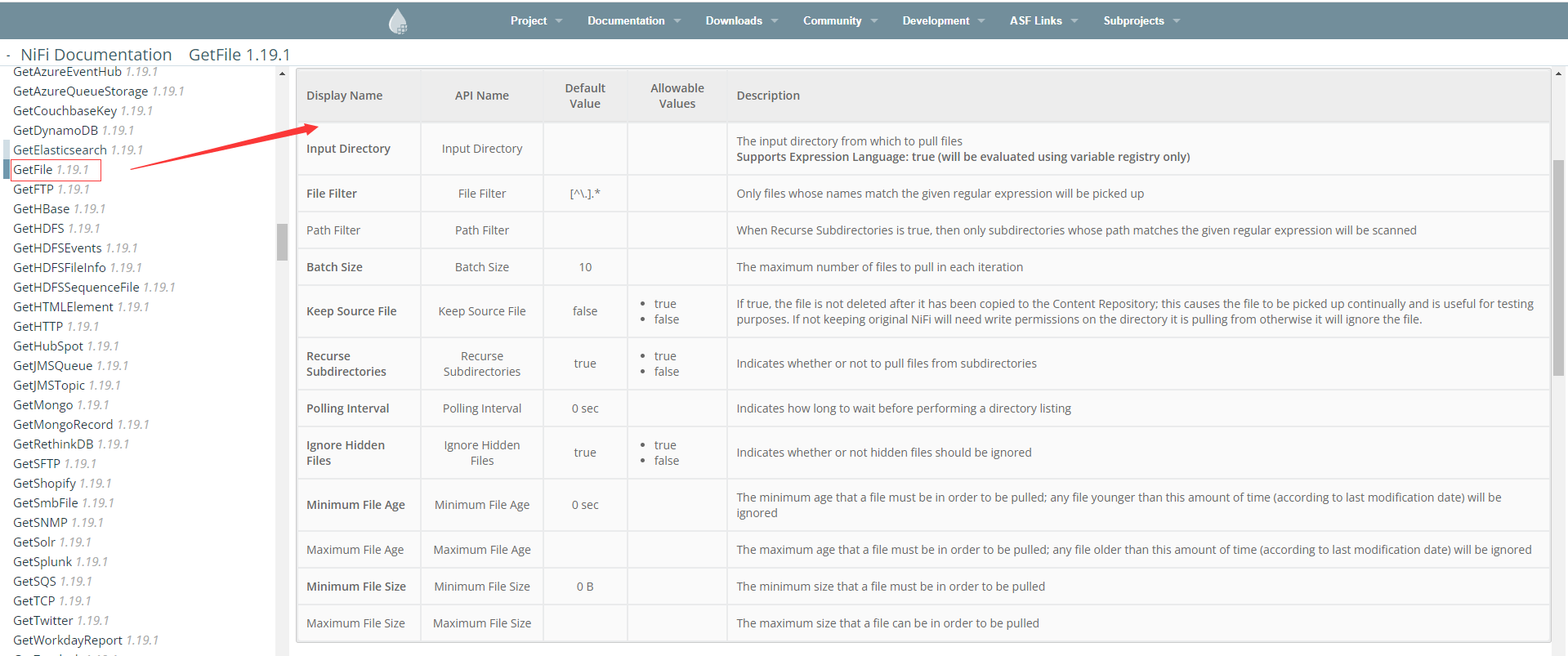
这里我们使用默认参数,主要配置输入目录,添加一个GetFile处理器 。

"设置"中填写名称为my-first-get-file,属性填写输入目录.
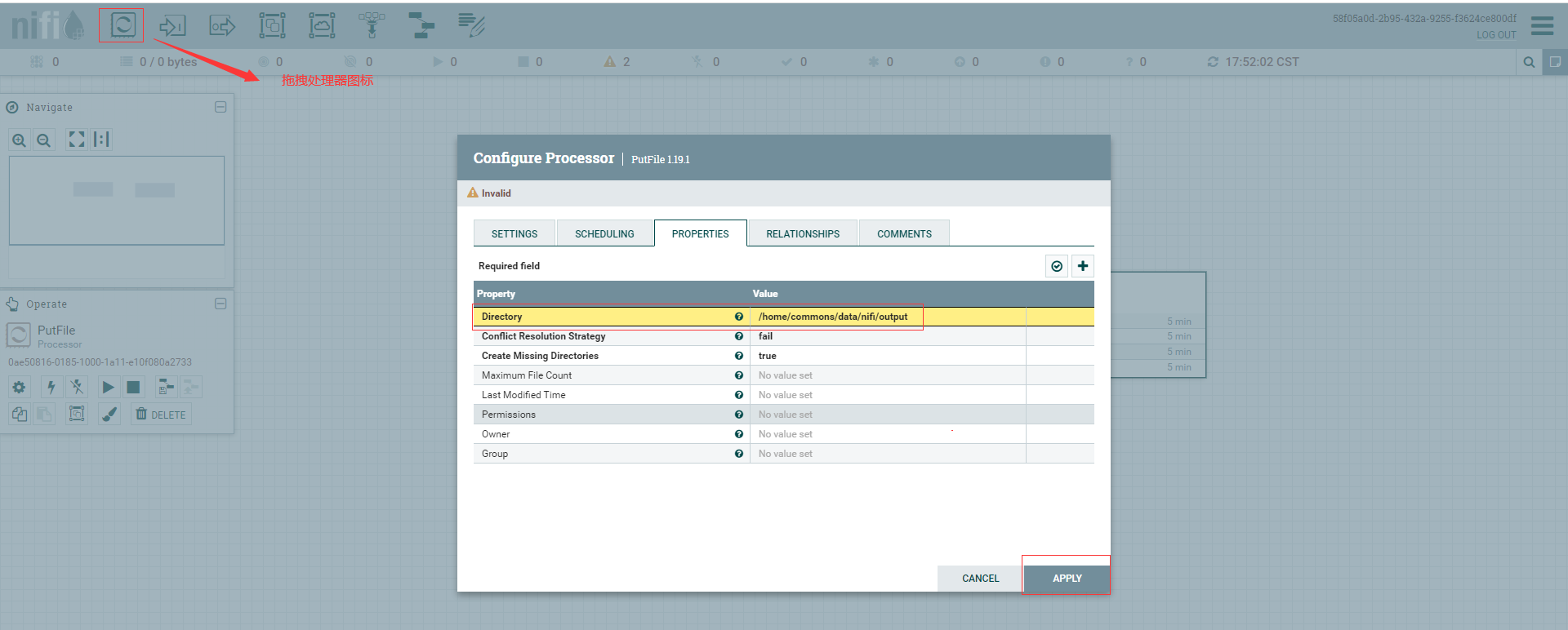
PutFile文件数据摄取处理器,将FlowFile的内容写入本地文件系统,详细属性可直接查阅官方文档 。
添加一个PutFile处理器,"设置"中填写名称为my-first-put-file,属性填写目录 。
# 创建上传文件目录,如果没有创建在my-first-put-file的会有感叹号提示信息
mkdir /home/commons/data/nifi/input
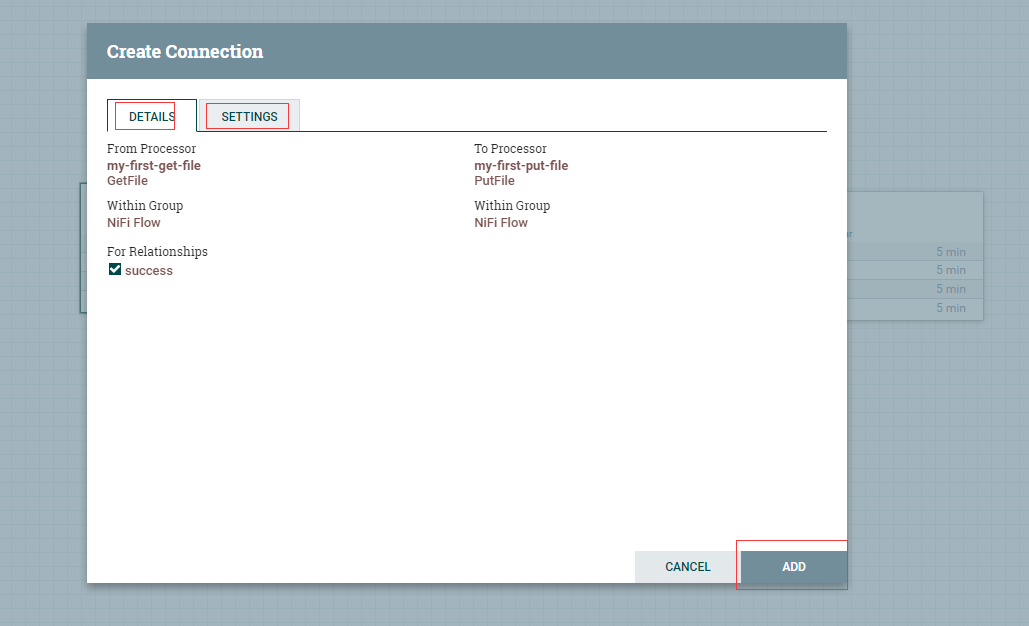
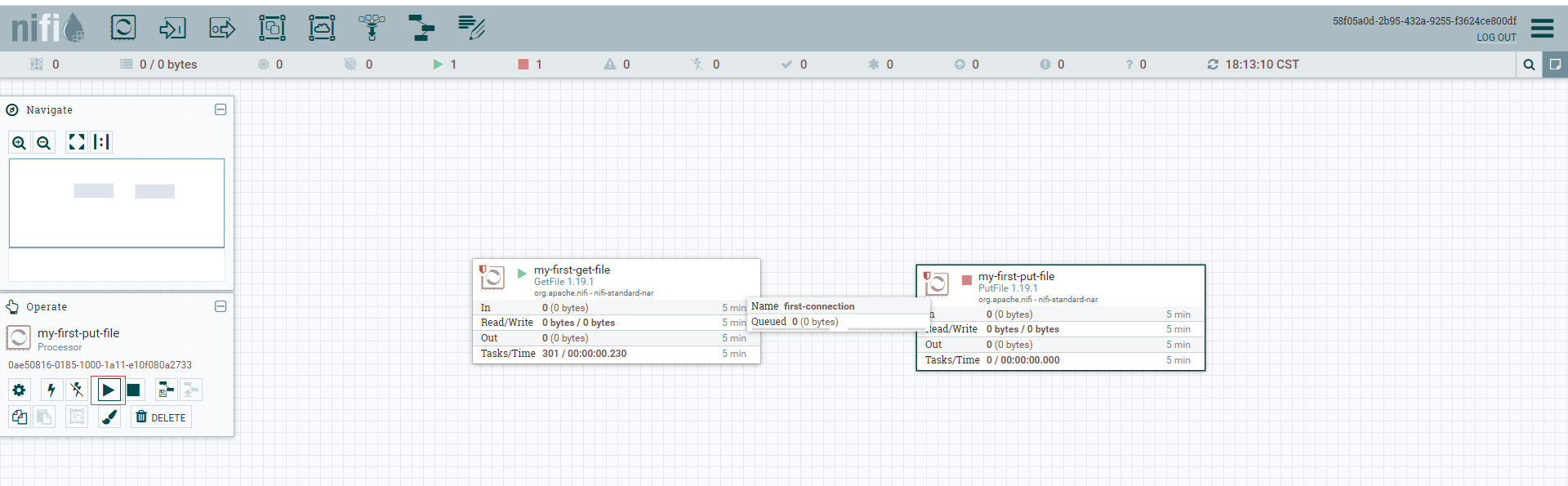
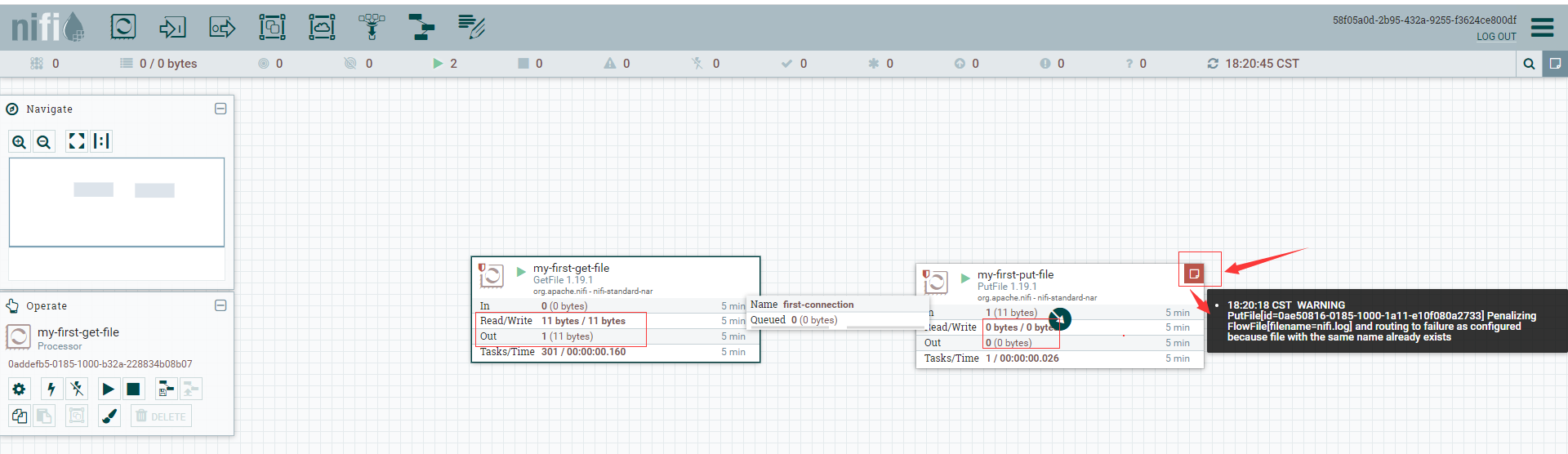
从my-first-get-file上点击拉动到my-first-put-file处理器形成连接,连接名称为first-connection 。
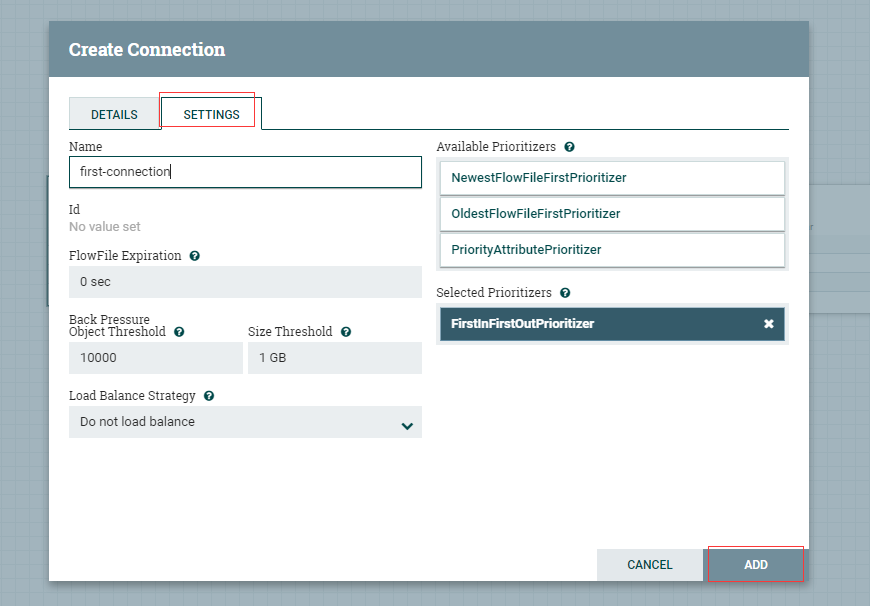
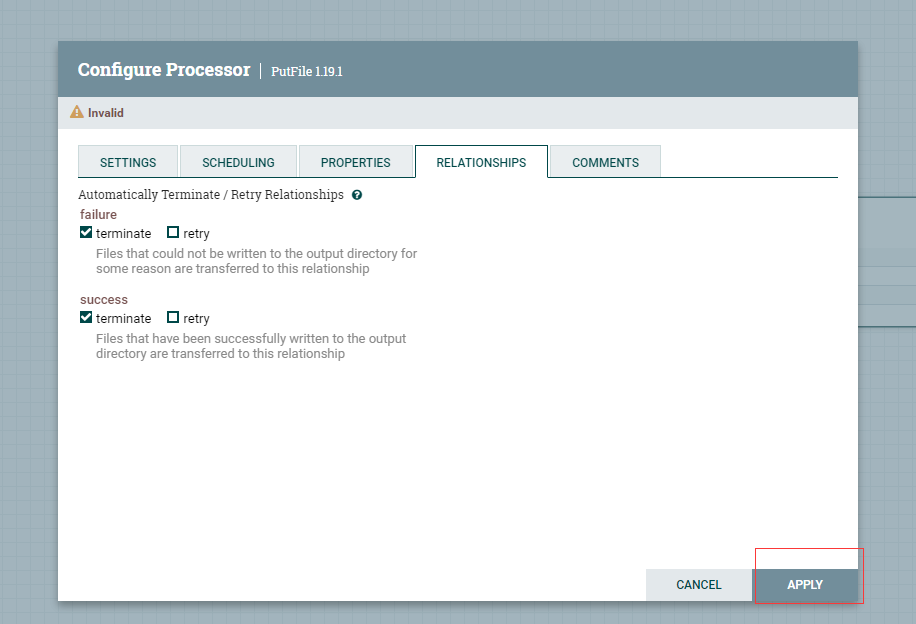
为my-first-put-file设置终止关联关系 。
分别点击my-first-get-file和my-first-put-file启动按钮,启动两个的处理器 。
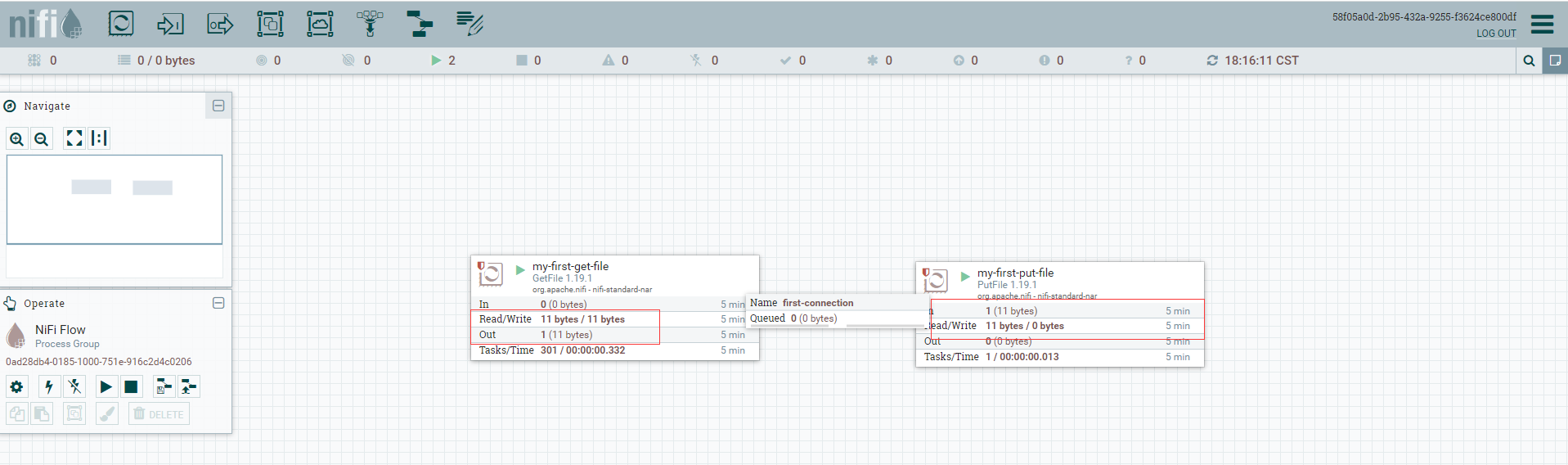
# 手工写入数据文件
echo "hello nifi" >> /home/commons/data/nifi/input/nifi.log
查看nifi上可以看到数据文件有复制数据 。
查看本地的output文件夹下也有上面手工写入后转移的nifi.log文件数据(由于PutFile创建缺失的目录默认属性设置是true,也即是会自动创建目录) 。
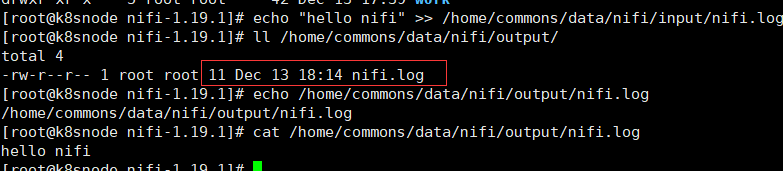
本地input文件转移就没有文件,重新执行上面写入一个重名的文件 。
echo "hello nifi" >> /home/commons/data/nifi/input/nifi.log
由于PutFile冲突解决的策略默认为false,所以同名文件不会放到输出目录下,就直接在页面出现警告信息,可设置为true就不会有警告信息了 。
本篇只是简单入门,nifi的功能非常强大,针对数据采集和数据集成场景需求可以满足大多数的场景 。
本人博客网站 IT小神 www.itxiaoshen.com 。
最后此篇关于可视化编排的数据集成和分发开源框架Nifi轻松入门-上的文章就讲到这里了,如果你想了解更多关于可视化编排的数据集成和分发开源框架Nifi轻松入门-上的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
28
4
 0
0
我需要开发一个简单的网站,我通常使用 bootstrap CSS 框架,但是我想使用 Gumbyn,它允许我使用 16 列而不是 12 列。 我想知道是否: 我可以轻松地改变绿色吗? 如何使用固定布局
这个问题在这里已经有了答案: 关闭 13 年前。 与直接编写 PHP 代码相比,使用 PHP 框架有哪些优点/缺点?
我开发了一个 Spring/JPA 应用程序:服务、存储库和域层即将完成。 唯一缺少的层是网络层。我正在考虑将 Playframework 2.0 用于 Web 层,但我不确定是否可以在我的 Play
我现有的 struts Web 应用程序具有单点登录功能。然后我将使用 spring 框架创建一个不同的 Web 应用程序。然后想要使用从 struts 应用程序登录的用户来链接新的 spring 应
我首先使用Spark框架和ORMLite处理网页上表单提交的数据,在提交中文字符时看到了unicode问题。我首先想到问题可能是由于ORMLite,因为我的MySQL数据库的字符集已设置为使用utf8
我有一个使用 .Net 4.5 功能的模块,我们的应用程序也适用于 XP 用户。所以我正在考虑将这个 .net 4.5 依赖模块移动到单独的项目中。我怎样才能有一个解决方案,其中有两个项目针对不同的版
我知道这是一个非常笼统的问题,但我想我并不是真的在寻找明确的答案。作为 PHP 框架的新手,我很难理解它。 Javascript 框架,尤其是带有 UI 扩展的框架,似乎通过将 JS 代码与设计分开来
我需要收集一些关于现有 ORM 解决方案的信息。 请随意编写任何编程语言。 你能谈谈你用过的最好的 ORM 框架吗?为什么它比其他的更好? 最佳答案 我使用了 NHibernate 和 Entity
除了 Apple 的 SDK 之外,还有什么强大的 iPhone 框架可供开始开发?有没有可以加快开发时间的方法? 最佳答案 此类框架最大的是Three20 。 Facebook 和许多其他公司都使用
有人可以启发我使用 NodeJS 的 Web 框架吗?我最近开始从免费代码营学习express js,虽然一切进展顺利,但我对express到底是什么感到困惑。是全栈框架吗?纯粹是为了后端吗?我发现您
您可以推荐哪种 Ajax 框架/工具包来构建使用 struts 的 Web 应用程序的 GUI? 最佳答案 我会说你的 AJAX/javascript 库选择应该较少取决于你的后端是如何实现的,而更多
我有生成以下错误的 python 代码: objc[36554]: Class TKApplication is implemented in both /Library/Frameworks/Tk.
首先,很抱歉,如果我问的问题很明显,因为我没有编程背景,那我去吧: 我想运行一系列测试场景并在背景部分声明了几个变量(我打印它们以仔细检查它们是否已正确声明),第一个是整数,另外两个字符串为你可以看到
在我们承担的一个项目中,我们正在寻找一个视频捕获和录制库。我们的基础工作(基于 google 搜索)表明 vlc (libvlc)、ffmpeg (libavcodec) 和 gstreamer 是三
我试过没有运气的情况下寻找某种功能来杀死/中断Play中的正常工作!框架。 我想念什么吗?还是玩了!实际没有添加此功能? 最佳答案 Java stop类中没有像Thread方法那样的东西,由于种种原因
我们希望在我们的系统中保留所有重大事件的记录。例如,在数据库可能存储当前用户状态的地方,事件日志应记录对该状态的所有更改以及更改发生的时间。 事件记录工具应该尽可能接近于事件引发器的零开销,应该容纳结
那里有 ActionScript 2.0/3.0 的测试框架列表吗? 最佳答案 2010-05-18 更新 由于这篇文章有点旧,而且我刚刚收到了赞成票,因此可能值得提供一些更新的信息,这样人们就不会追
我有一个巨大的 numpy 数组列表(一维),它们是不同事件的时间序列。每个点都有一个标签,我想根据其标签对 numpy 数组进行窗口化。我的标签是 0、1 和 2。每个窗口都有一个固定的大小 M。
我是 Play 的新手!并编写了我的第一个应用程序。这个应用程序有一组它依赖的 URL,从 XML 响应中提取数据并返回有效的 URL。 此应用程序需要在不同的环境(Dev、Staging 和 Pro
关闭。这个问题不满足Stack Overflow guidelines .它目前不接受答案。 想改善这个问题吗?更新问题,使其成为 on-topic对于堆栈溢出。 4年前关闭。 Improve thi

我是一名优秀的程序员,十分优秀!