
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 28
28
 4
4


MySQL锁系列文章已经鸽了挺久了,最近赶紧挤了挤时间,和大家聊一聊MySQL的锁.
只要学计算机,「 锁 」永远是一个绕不过的话题。MySQL锁也是一样.
一句话解释MySQL锁:
MySQL锁是 解决资源竞争 的一种方案.
短短一句话却包含了3点值得我们注意的事情:
这篇文章开始带你循序渐进地理解这几个问题.
MySQL对资源的操作无非就是 读 、 写 两种方式,但是由于事务并发执行的存在,因此对同一资源的并发访问存在3种形式:
假设一种情形,一个事务先对某个资源进行读操作,然后另一个事务再对该资源进行写操作,如果两个事务到此为止,必然不会导致并发问题.
可是事务这种东西,一般情况下就是包含有很多个子操作啊.
想象一下啊,假设事务 T1 和 T2 并发执行, T1 先查找了所有 name 为「王刚蛋」的用户信息,此时发现拥有这个硬汉名字的用户只有一个。然后 T2 插入了一个同样叫做「王刚蛋」的用户的信息,并且提交了.
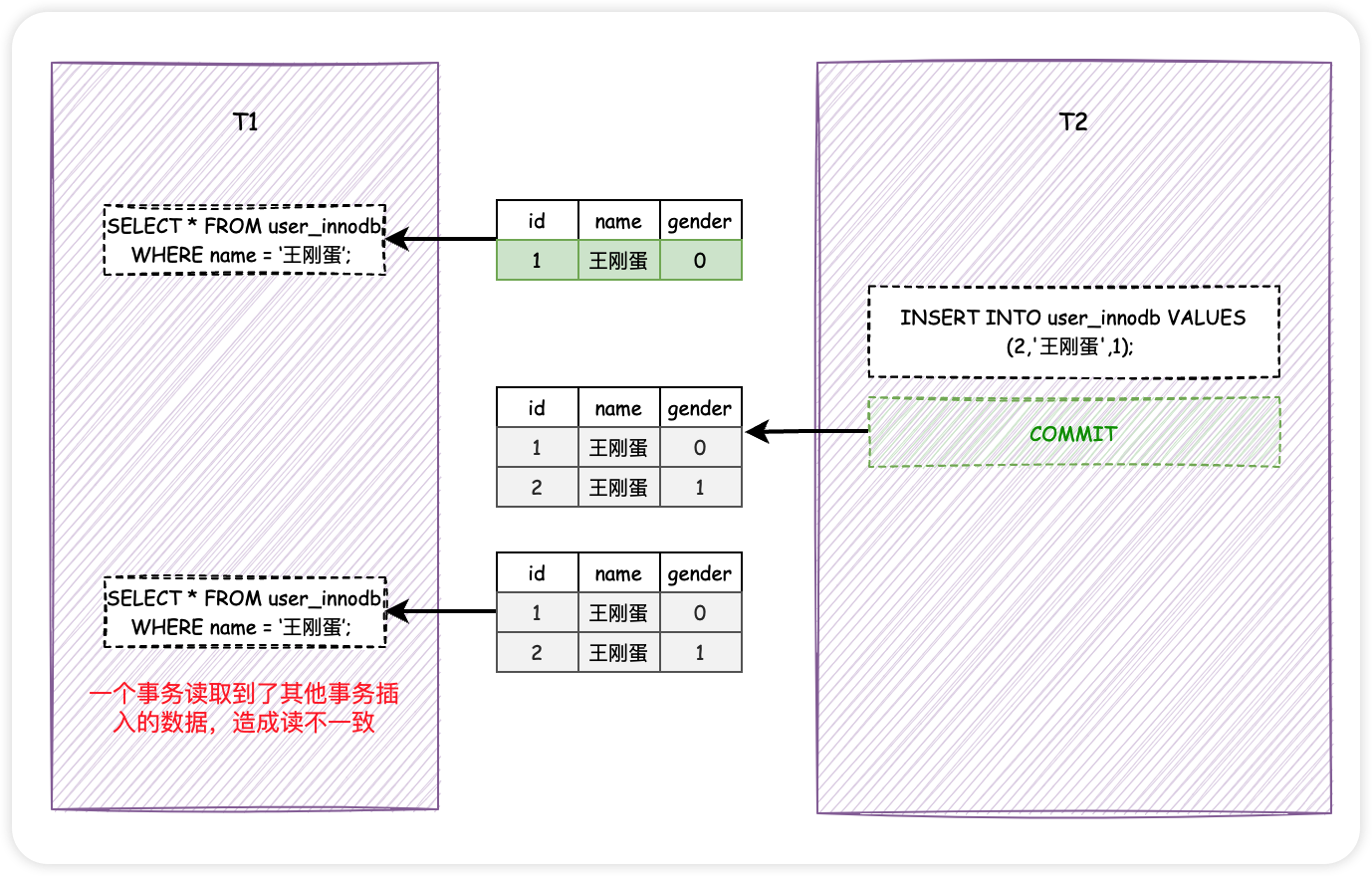

再来,同样是 T1 和 T2 两个事务, T1 通过 id = 1 查询到了一条数据,然后 T2 紧接着 UPDATE ( DELETE 也可以)了该条记录,不同的是, T2 紧接着通过 COMMIT 提交了事务.
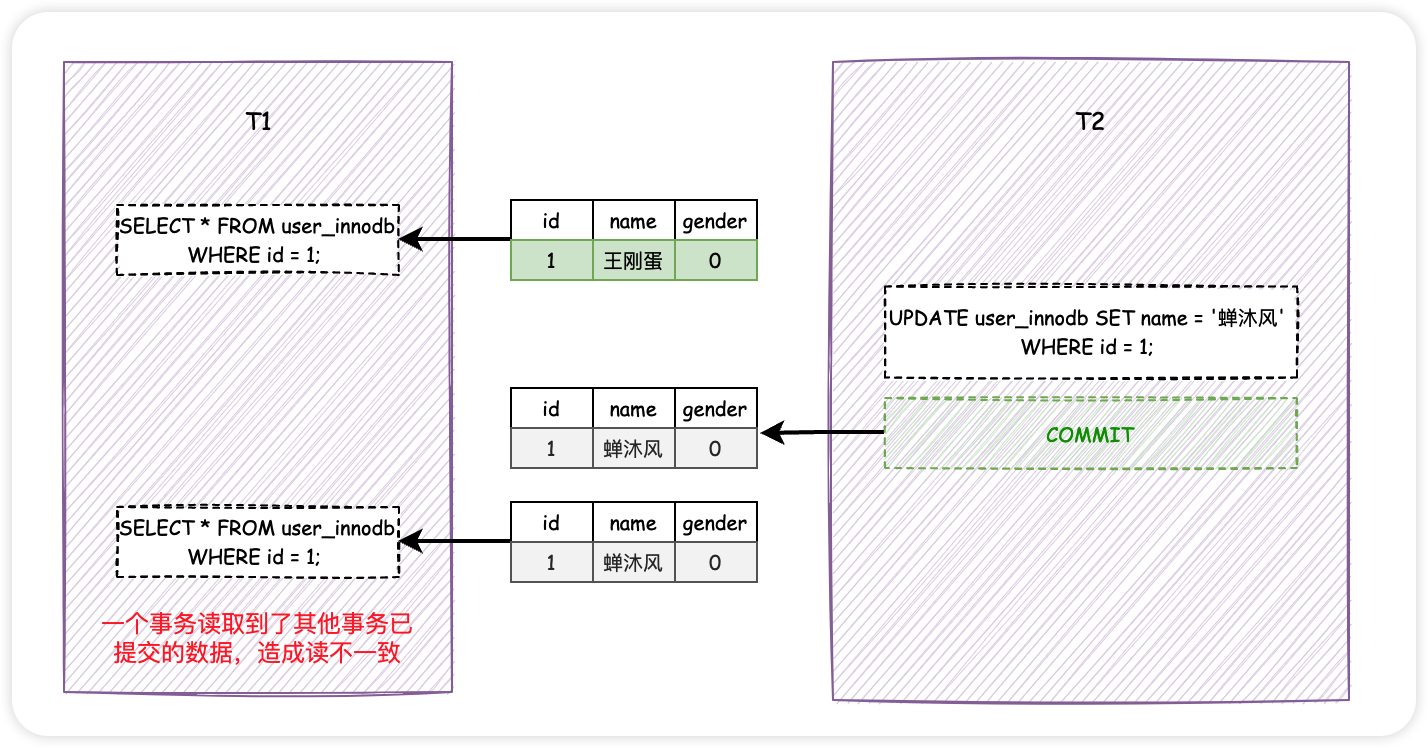
此时, T1 再次执行相同的查询操作,会发现数据发生了变化, name 字段由「王刚蛋」变成了「蝉沐风」.
如果一个事务读到了另一个 已提交事务 修改过的(或者是删除的)数据,而导致了前后两次读取的数据不一致的情况,这种事务并发问题叫做 不可重复读 .
事情还没结束,假设 T1 和 T2 都要访问 user_innodb 表中 id 为 1 的数据,不同的是 T1 先读取数据,紧接着 T2 修改了数据的 name 字段,需要注意的是, T2 并没有提交! 。
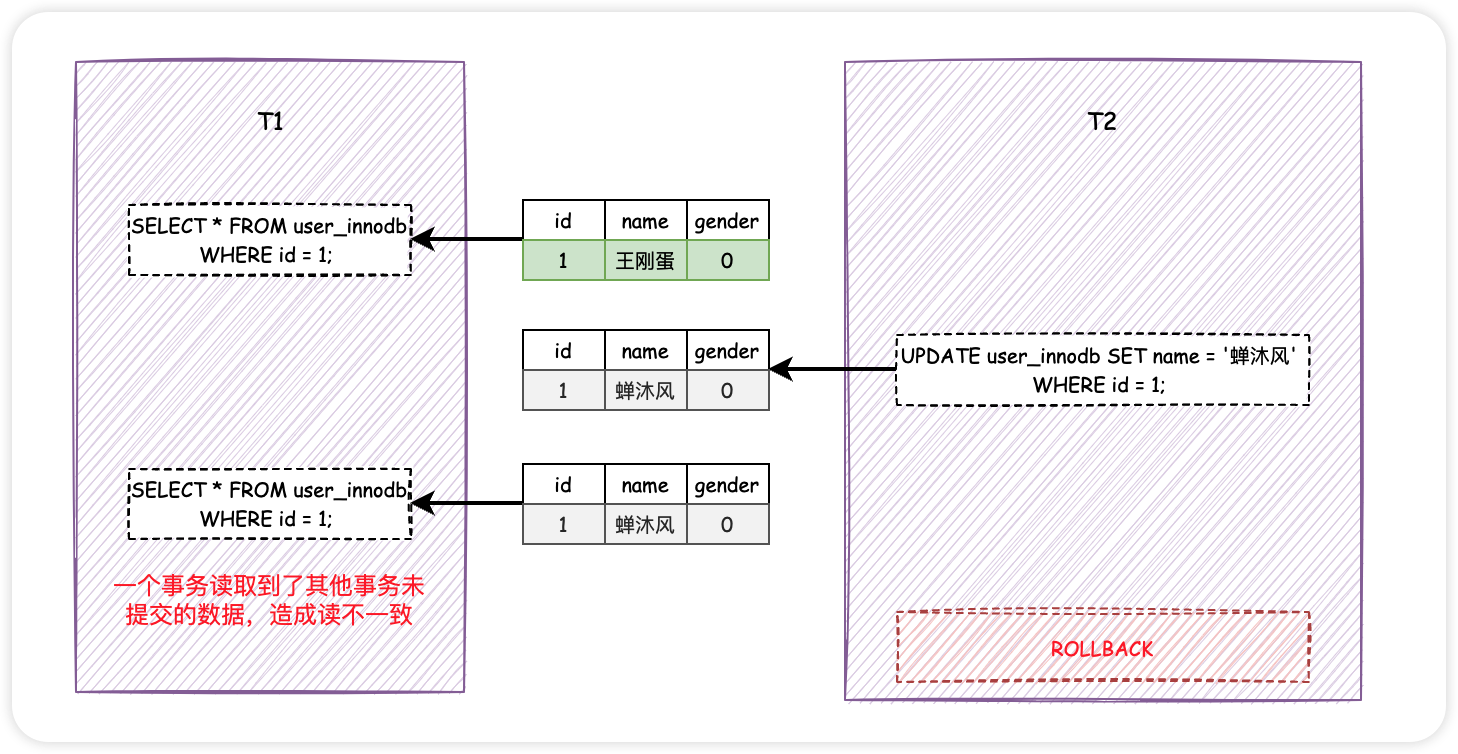
此时, T1 再次执行相同的查询操作,会发现数据发生了变化, name 字段由「王刚蛋」变成了「蝉沐风」.
如果一个事务读到了另一个 未提交事务 修改过的数据,而导致了前后两次读取的数据不一致的情况,这种事务并发问题叫做 脏读 .
总结一下:我们在读—写,写—读的情况下会遇到3种读不一致性的问题,脏读、不可重复读以及幻读.
那写—写呢?很显然,在不做任何措施的情况下,并发会出现更大的问题。那该怎么办呢?
一切的并发问题都可以通过串行化解决,但是串行化效率太低了! 。
再优化一下,一切并发问题都可以通过加锁来解决,这种方案我们称为 基于锁的并发控制 ( Lock Bases Concurrency Control , LBCC )!但是在读多写少的环境下,客户端连读取几条记录都需要排队,效率还是太低了! 。
因此,MySQL的设计者为事务之间的隔离性提供了不同的级别,使得开发者可以根据自己的业务场景设置不同的隔离级别,来解决(或者部分解决)读—写/写—读下的读一致性问题,而不是一上来就加锁.
这种机制叫做 MVCC ,如果你对这个概念不是很了解,我建议你暂停一下,读一下我的 事务的隔离性与MVCC 这篇文章,写得贼好!!(自卖自夸一下) 。
那有了MVCC是不是在读—写/写—读的情况下就不需要锁了呢?那也不是.
MVCC解决的是读—写/写—读中“ 比较纯粹的读 ”遇到的一致性问题,原谅我,这是我自己编的词儿。那什么是不纯粹的?拿存款业务举个例子.
假设陀螺要存一笔钱,系统需要先把陀螺的余额读出来,然后在余额的基础上加上本次存款的金额,最后再写入到数据库中。在将余额读出来之后,如果不想让其他事务继续访问该余额,直到整个存款事务完成之后,其他事务才可以对该余额继续进行操作,这种情况下就必须为余额的读取操作添加锁.
再总结一下: MVCC是MySQL默认的解决读—写/写—读下一致性问题的方式,不需要加锁。而锁是实现一致性的最终兜底方案,在某些特殊场景下,锁的使用不可避免 .
说得更准确一点,MVCC是MySQL在 READ COMMITTED 、 REPEATABLE READ 这两种隔离级别之下执行普通 SELECT 操作时默认解决一致性问题的方式.
具体为什么只是这两种隔离级别,建议你看看 事务的隔离性与MVCC .
事务是多个操作的集合,比如我们可以把「把大象装冰箱」这件事情作为一个事务.

事务有 A (原子性)、 C (一致性)、 I (隔离性)、 D (持久性)4大特性,而锁就是实现隔离性的其中一种方案(比如还有MVCC等方案).
事务的隔离性针对不同场景需求又实现了不同的隔离级别,不同的隔离级别下,事务使用锁的方式又会有所不同。举个例子.
在 READ COMMITTED 、 REPEATABLE READ 这两种隔离级别之下, SELECT 操作是不需要加锁的,直接使用MVCC机制即可满足当前隔离级别的需求。但是在 SERIALIZABLE 隔离级别,并且在禁用自动提交时(autocommit=0),MySQL会将普通的 SELECT 语句转化为 SELECT ... LOCK IN SHARE MODE 这样的加锁语句,如果你看不懂这句话也没关系,你只需要知道MySQL自动加锁了就行,更详细的下文再说.
另外,一个事务可能会加很多个锁,但是某个锁一定只属于一个事务。这就好比一个管理员可以管理多个保险柜,一个保险柜一定只被一个管理员管理.
写—写的情况下肯定要加锁的了,所以接下来终于要聊一聊锁了.
我们首先研究一下锁住的东西的大小,也就是锁的粒度.
举一个非常应景的例子。疫情防控的时候,是封锁整个小区还是封锁某栋楼的某个单元,这完全是两种概念.
对应到MySQL锁的粒度,那就是 表锁 和 行锁 .
很容易想到,封锁小区的行为远比封锁某栋楼某单元的行为粗旷,因此, 。
从锁定粒度上来看,表锁 > 行锁 。
直接堵住小区的门口要比进入小区找到具体某栋楼的某个单元要快不少,因此, 。
从加锁效率上来看,表锁 > 行锁 。
直接锁住小区大概率会影响其他楼居民的正常生活和各种社会活动的开展,而锁住某栋楼某单元顶多影响这一个单元的居民的生活,因此, 。
从冲突概率来看,表锁 > 行锁 。
从并发性能来看,表锁 < 行锁 。
MySQL支持很多存储引擎,而不同的存储引擎对锁的支持也不尽相同。对于 MyISAM 、 MERGE 、 MEMORY 这些存储引擎而言,只支持表锁;而 InnoDB 存储引擎既支持表锁也支持行锁,下文讨论的所有内容均针对InnoDB存储引擎.
说完锁的粒度,还有一件事情需要我们仔细考虑一下。上文说过, READ COMMITTED 、 REPEATABLE READ 这两种隔离级别之下, SELECT 操作默认采用MVCC机制就可以了,压根儿不需要加锁,那么问题来了,万一我就是想加锁呢?
你可能会说,“简单啊,那就加锁!把数据锁死!除了我谁也别动!” 。
很好,但是对于大部分读—读而言,由于不会出现读一致性问题,所以不让其他事务进行读操作并不合理.
你可能又说,“那行吧,那就让读操作加锁的时候允许其他事务对锁住的数据进行读操作,但是不允许写操作。” 。
嗯,想得确实更细致了一些。但是再想想我上文中举过的陀螺存钱的例子,有时候 SELECT 操作需要独占数据,其他事务既不能读,更不能写.

我们把这种 共享 和 排他 的性质称为锁的基本模式.
共享锁(Shared Lock),简称 S 锁,可以同时被多个事务共享,也就是说,如果一个事务给某个数据资源添加了 S 锁,其他事务也被允许获取该数据资源的 S 锁.
由于 S 锁通常被用于读取数据,因此也被称为 读锁 .
那怎么给数据添加 S 锁呢?
我们可以用 SELECT ... LOCK IN SHARE MODE; 的方式,在读取数据之前就为数据添加一把 S 锁。如果当前事务执行了该语句,那么会为读取到的记录添加 S 锁,同时其他事务也可以使用 SELECT ... LOCK IN SHARE MODE; 方式继续获取这些数据的 S 锁.
我们通过以下的例子验证一下 S 锁是否可以重复获取.

排他锁(Exclusive Lock),简称 X 锁。只要一个事务获取了某数据资源的 X 锁,其他的事务就不能再获取该数据的 X 锁和 S 锁.
由于 X 锁通常被用于修改数据,因此也被称为 写锁 .
X 锁的添加方式有两种, 。
自动添加 X 锁 。
我们对记录进行增删改时,通常情况下会自动对其添加 X 锁.
手动加锁 。
我们可以用 SELECT ... FOR UPDATE; 的方式,在读取数据之前就为数据添加一把 X 锁。如果当前事务执行了该语句,那么会为读取到的记录添加 X 锁,这样既不允许其他事务获取这些记录的 S 锁,也不允许获取这些记录的 X 锁.
我们用下面的例子验证一下 X 锁的排他性.
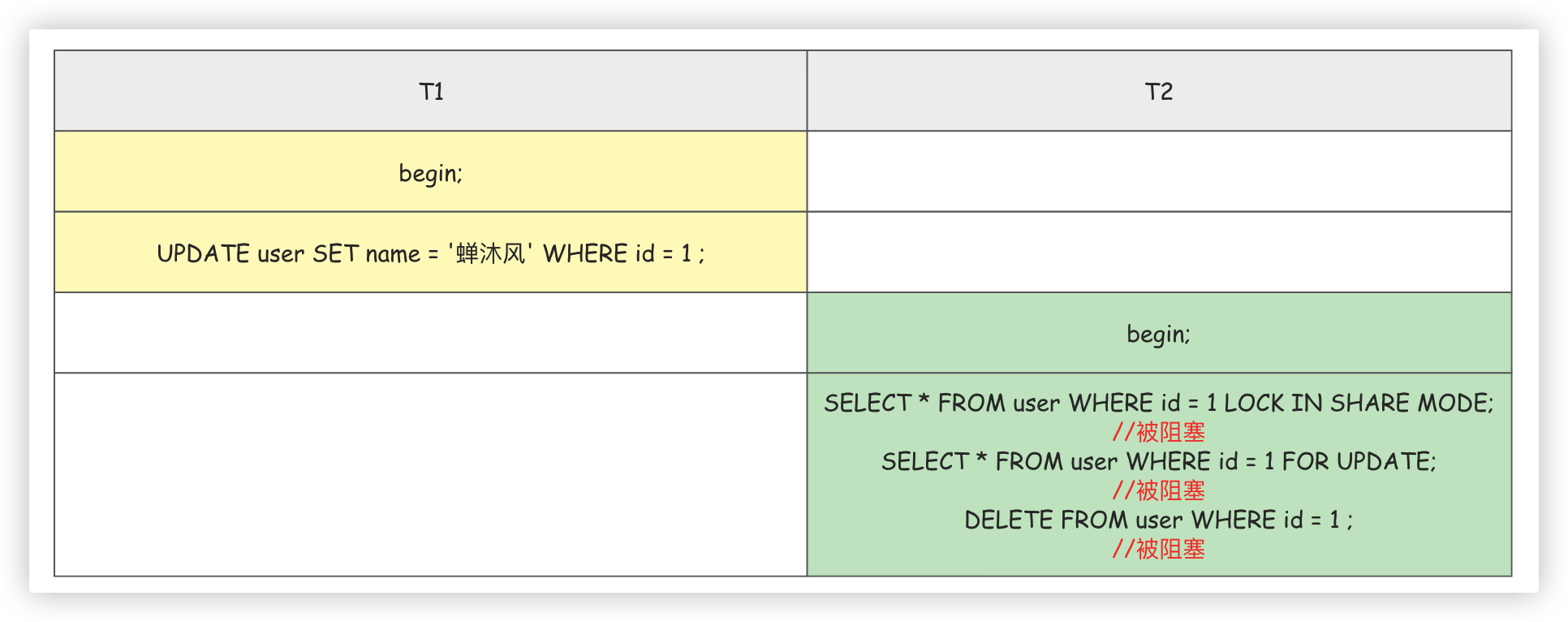
通常情况下,事务提交或结束事务时,锁会被释放.
前面提到的 S 锁和 X 锁的语法规则其实是针对记录的,也就是行锁,原因是InnoDB中行锁用的最多。如果将锁的粒度和锁的基本模式排列组合一下,就会出现如下4种情况:
S 锁 X 锁 S 锁 X 锁 那么接下来的描述,也就顺理成章了.
如果事务给一个表添加了表级 S 锁,则:
S 锁,但是无法获取该表的 X 锁; S 锁,但是无法获取该表某些行的 X 锁。 如果事务给一个表添加了表级 X 锁,则:
S 锁、 X 锁,还是该表某些行的 S 锁、 X 锁,其他事务都只能干瞪眼儿,啥也获取不了。 挺好理解的吧,总之就是 S锁只能和S锁相容,X锁和其他任何锁都互斥 。问题来了,虽然用的不多,但是万一我真的想给整个表添加一个 S 锁或者 X 锁怎么办?
假如我要给表 user 添加一个 S 锁,那就必须保证 user 在表级别上和行级别上都不能有 X 锁,表级别上还好说一点,无非就是1个内存结构罢了,但是行 X 锁呢?必须得逐行遍历是否有行 X 锁吗?
同理,假如我要给表 user 添加一个 X 锁,那就必须保证 user 在表级别上和行级别上都不能有任何锁( S 和 X 都不能有),难不成得逐行遍历是否有 S 或 X 锁吗?
遍历是不可能遍历的!这辈子都不可能遍历的!于是, 意向锁 (Intension Lock)诞生了.
我们要避免遍历,那最好的办法就是在给行加锁时,先在表级别上添加一个标识.
IS 锁,当事务试图给行添加 S 锁时,需要先在表级别上添加一个 IS 锁; IX 锁,当事务试图给行添加 X 锁时,需要先在表级别上添加一个 IX 锁。 这样一来:
user 表添加一个 S 锁(表级锁),就先看一下 user 表有没有 IX 锁;如果有,就说明 user 表的某些行被加了 X 锁(行锁),需要等到行的 X 锁释放,随即 IX 锁被释放,才可以在 user 表中添加 S 锁; user 表添加一个 X 锁(表级锁),就先看一下 user 有没有 IS 锁或 IX 锁;如果有,就说明 user 表的某些行被加了 S 锁或 X 锁(行锁),需要等到所有行锁被释放,随即 IS 锁或 IX 锁被释放,才可以在 user 表中添加 X 锁。 需要注意的是,意向锁和意向锁之间是不冲突的,意向锁和行锁之间也不冲突.
只有在对表添加 S 锁或 X 锁时才需要判断当前表是否被添加了 IS 锁或 IX 锁,当为表添加 IS 锁或 IX 锁时,不需要关心当前表是否已经被添加了其他 IS 锁或 IX 锁.
目前为止MySQL锁的基本模式就介绍完了,接下来回到这片文章的题目,MySQL锁,锁住的到底是什么?由于InnoDB的行锁用的最多,这里的锁自然指的是行锁.
既然都叫行锁了,我们姑且猜测一下,行锁锁住的是一行数据。我们做个实验.
我们先创建一张没有任何索引的普通表,语句如下 。
CREATE TABLE `user_t1` (
`id` int DEFAULT NULL,
`name` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
表中数据如下:
mysql> SELECT * FROM user_t1;
+------+-------------+
| id | name |
+------+-------------+
| 1 | chanmufeng |
| 2 | wanggangdan |
| 3 | wangshangju |
| 4 | zhaotiechui |
+------+-------------+
接下来我们在两个session中开启两个事务.
WHERE id = 1 “锁住”第1行数据; WHERE id = 2 "锁住"第2行数据。 
一件诡异的事情是,第2个加锁的操作被阻塞了。实际上, T2 中不管我们要给 user_t1 中哪行数据加锁,都会失败! 。
为什么我 SELECT 一条数据,却给我锁住了整个表?这个实验直接推翻了我们的猜测, InnoDB的行锁并非直接锁定Record行 .
为什么没有索引的情况下,给某条语句加锁会锁住整个表呢?别急,我们继续.
我们再创建一个表 user_t2 ,语句如下:
CREATE TABLE `user_t2` (
`id` int NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
和 user_t1 的不同之处在于为 id 创建了一个主键索引。表中数据依然如下:
mysql> SELECT * FROM user_t2;
+------+-------------+
| id | name |
+------+-------------+
| 1 | chanmufeng |
| 2 | wanggangdan |
| 3 | wangshangju |
| 4 | zhaotiechui |
+------+-------------+
同样开启两个事务:
WHERE id = 1 “锁住”第1行数据; WHERE id = 1 尝试加锁,加锁失败; WHERE id = 2 尝试加锁,加锁成功。 
既然锁的不是Record行,难不成锁的是 id 这一列吗?
我们再做最后一个实验.
我们再创建一个表 user_t3 ,语句如下:
CREATE TABLE `user_t3` (
`id` int NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY (`uk_name`) (`name`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
和 user_t2 的不同之处在于为 name 列创建了一个唯一索引。表中数据依然如下:
mysql> SELECT * FROM user_t3;
+------+-------------+
| id | name |
+------+-------------+
| 1 | chanmufeng |
| 2 | wanggangdan |
| 3 | wangshangju |
| 4 | zhaotiechui |
+------+-------------+

两个事务:
name 字段 “锁住” name 为“chanmufeng”的数据; WHERE name = “chanmufeng” 尝试加锁,可以预料,加锁失败; WHERE id = 1 尝试给同样的行加锁,加锁失败。 通过3个实验我们发现,行锁锁住的既不是Record行,也不是Column列,那到底锁住的是什么?我们对比一下,上文的3张表的不同点在于索引不同,其实 InnoDB的行锁,就是通过锁住索引来实现的 .
索引是个啥?再给你推荐一下我之前写的文章, 。
图解|12张图解释MySQL主键查询为什么这么快 。
图解|这次,彻底理解MySQL的索引 。
接下来回答3个问题.
你说锁住索引?如果我不创建索引,MySQL锁定个啥?
如果我们没有设置主键,InnoDB会优先选取一个不包含NULL值的 Unique键 作为主键,如果表中连 Unique键 也没有的话,就会自动为每一条记录添加一个叫做 DB_ROW_ID 的列作为默认主键,只不过这个主键我们看不到罢了.
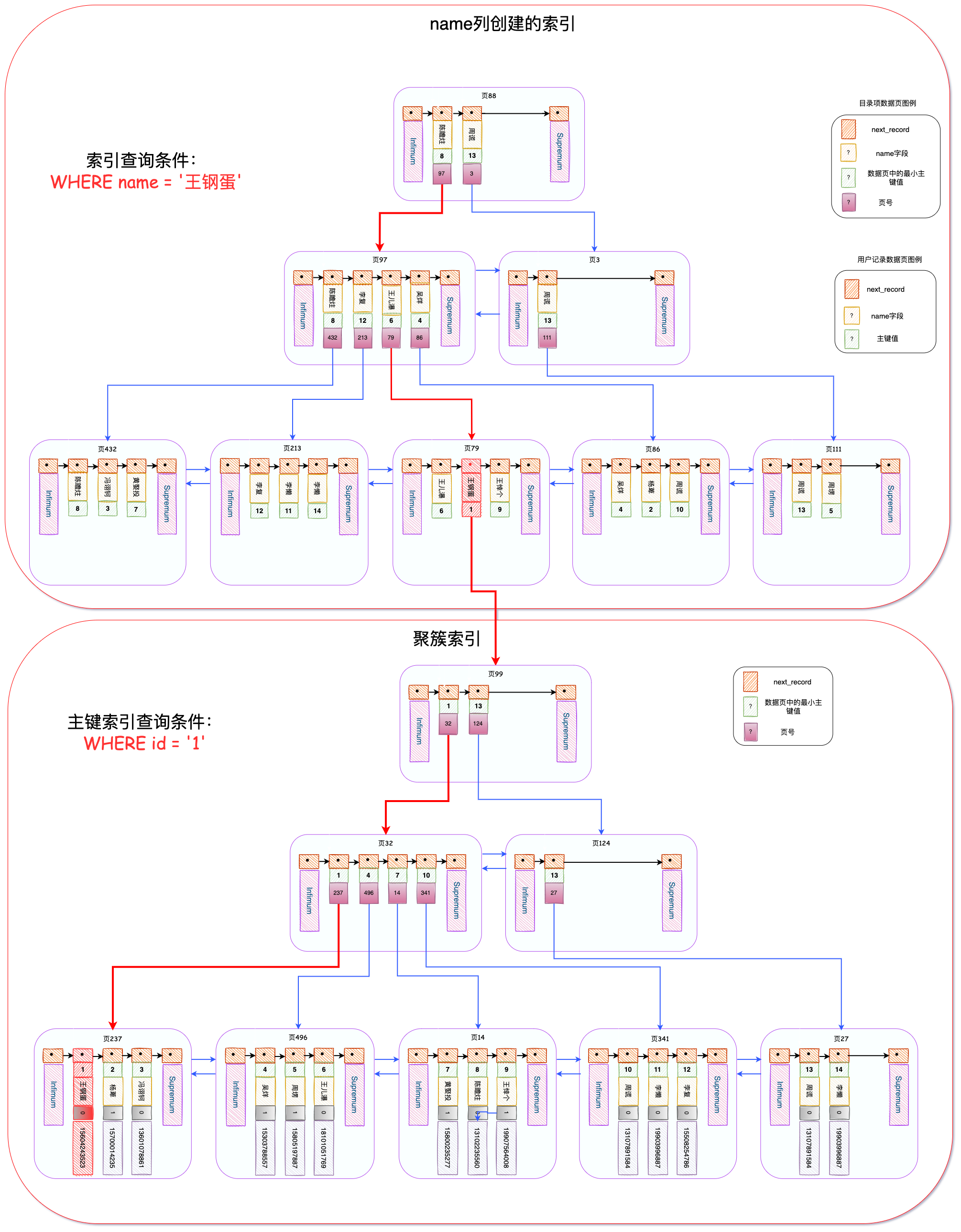
下图是数据的行格式。看不懂的话强烈推荐看一下我上面给出的两篇文章,说得非常明白.

因为 SELECT 没有用到索引,会进行全表扫描,然后把 DB_ROW_ID 作为默认主键的聚簇索引都给锁住了.
不管是 Unique 索引还是普通索引,它们的叶子结点中存储的数据都不完整,其中只是存储了作为索引并且排序好的列数据以及对应的主键值.
因此我们通过索引查找数据数据实际上是在索引的B+树中先找到对应的主键,然后根据主键再去主键索引的B+树的叶子结点中找到完整数据,最后返回。所以虽然是两个索引树,但实际上是同一行数据,必须全部锁住.
下面给了一张图,让不了解索引的朋友大致了解一下。上半部分是 name 列创建的唯一索引的B+树,下半部分是主键索引(也叫聚簇索引).
假如我们通过 WHERE name = '王钢蛋' 对数据进行查询,会先用到 name 列的唯一索引,最终定位到主键值为 1 ,然后再到主键索引中查询 id = 1 的数据,最终拿到完整的行数据.
这两张图在我索引文章中都有哦~ 。
至此,我已经回答了文章开头的绝大多数问题.
MySQL锁,是解决资源竞争问题的一种手段。有哪些竞争呢?读—写/写—读,写—写中都会出现资源竞争问题,不同的是前者可以通过MVCC的方式来解决,但是某些情况下你也不得不用锁,因此我也顺便解释了锁和MVCC的关系.
然后介绍了MySQL锁的基本模式,包括共享锁( S 锁)和排他锁( X 锁),还引入了意向锁.
最后解释了锁到底锁的是什么的问题。通过3个实验,最终解释了InnoDB锁本质上锁的是索引.
本文并没有介绍MySQL中具体的锁算法,也就是如何解决资源竞争的,比如 Record Locks 、 Gap Locks 、 Next-Key Locks 等,更细节的内容下期见喽~ 。
作者:蝉沐风 个人站点:https; //www.chanmufeng.com 公众号:蝉沐风的码场 。
最后此篇关于MySQL锁,锁的到底是什么?的文章就讲到这里了,如果你想了解更多关于MySQL锁,锁的到底是什么?的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
28
4
 0
0
这对你们来说可能很简单,但由于我是java新手,所以我想知道实际上什么是 接下来的部分会发生什么? if (args.length > 0) { file = args[0]; } publi
在我的 View Controller 中,我将 UITapGestureRecognizer 添加到 self.view。我在 self.view 之上添加了一个小 View 。当我点击小 View
我今天尝试从 Obj-C 开始并转到 Swift,我正在阅读文档。我试图在 Swift 中创建一个简单的 IBOutlet,但它不断给我这些错误。 View Controller 没有初始化器 req
我正在尝试使用 VIM 完成(字典和当前缓冲区),但我遇到了问题?和 !在方法名称的末尾。我能以某种方式向 vim 解释方法名称(基本上是单词)最后只能有它,而且只有一个,即 method_name

我是一名优秀的程序员,十分优秀!