
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


文章都在个人博客网站: https://www.ikeguang.com/ 同步,欢迎访问.
最近看到有人在用flink sql的页面管理平台,大致看了下,尝试安装使用,比原生的flink sql界面确实好用多了,我们看下原生的,通过bin/sql-client.sh命令进入那个黑框,一只松鼠,对,就是那个界面。。。.
这个工具不是Flink官方出的,是一个国内的小伙伴写的,Github地址:
https://github.com/zhp8341/flink-streaming-platform-web 。
根据github上,作者的描述,flink-streaming-patform-web主要功能:
是不是觉得很强大,很多同学已经摩拳擦掌想试试了.
这里只介绍flink on yarn模式的安装,如果你的hadoop集群已经安装好了,大概半个小时就能好;否则,安装hadoop集群可老费事儿了。总体步骤如下:
这里假设你的hadoop集群是好的,yarn是可以正常使用的,8088端口可以访问,如下:
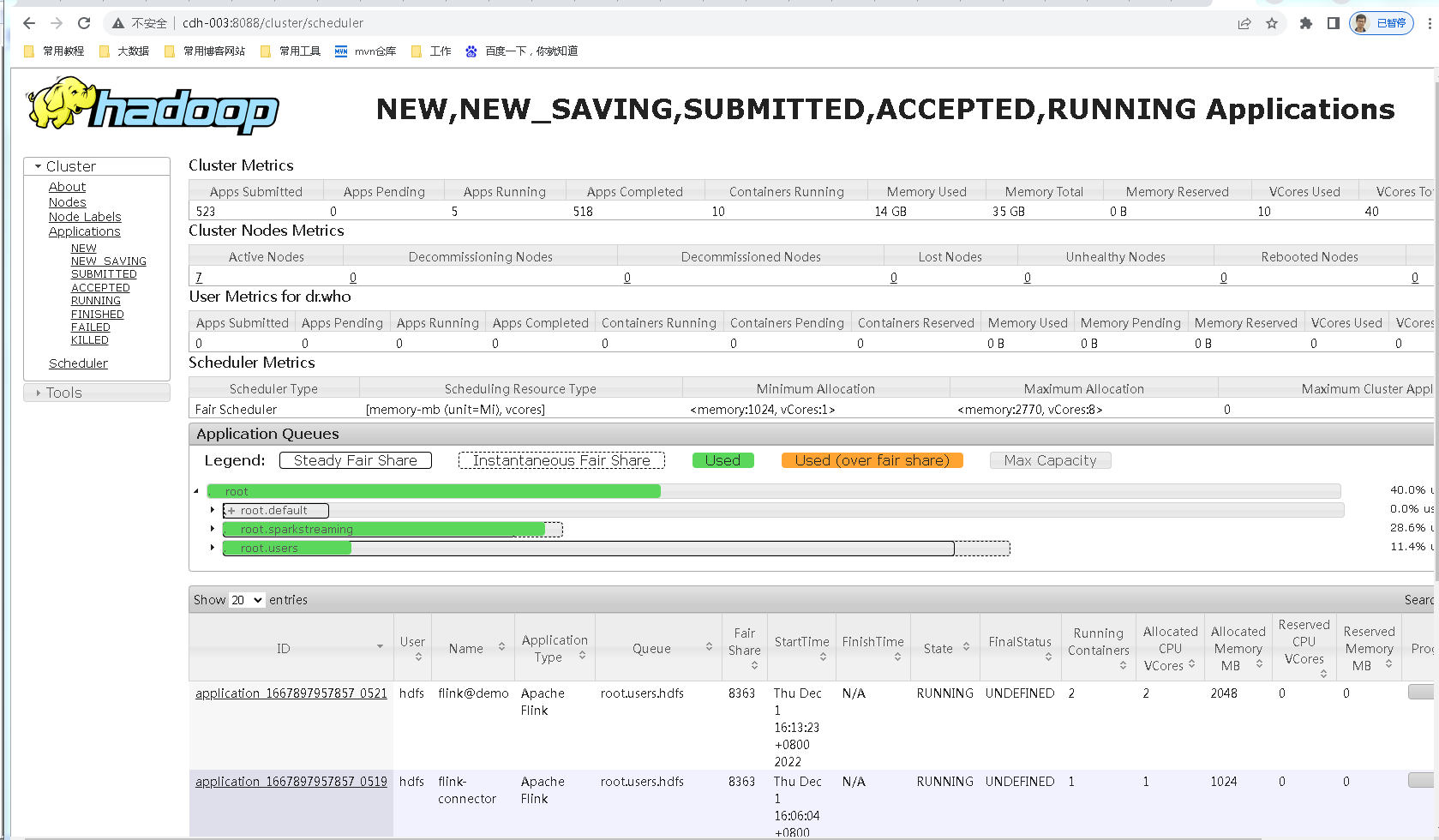
flink on yarn,只需要下载一个flink安装包即可使用,下载命令:
http://archive.apache.org/dist/flink/flink-1.13.5/flink-1.13.5-bin-scala_2.11.tgz
解压 。
tar -xvf flink-1.13.5-bin-scala_2.11.tgz
关键 :这里问题来了,我的flink怎么识别hadoop呢,需要配置一个环境变量,编辑 /etc/profile,键入内容:
export HADOOP_CONF_DIR=填你的hadoop配置文件目录,比如我的是/usr/local/hadoop2.8/etc/hadoop/conf
export HADOOP_CLASSPATH=`hadoop classpath`
好了,这样一个flink on yarn的环境就搭建好了.
官方地址文章开头已经给出,在github找到下载地址: https://github.com/zhp8341/flink-streaming-platform-web/releases/,我下载的版本是这个.
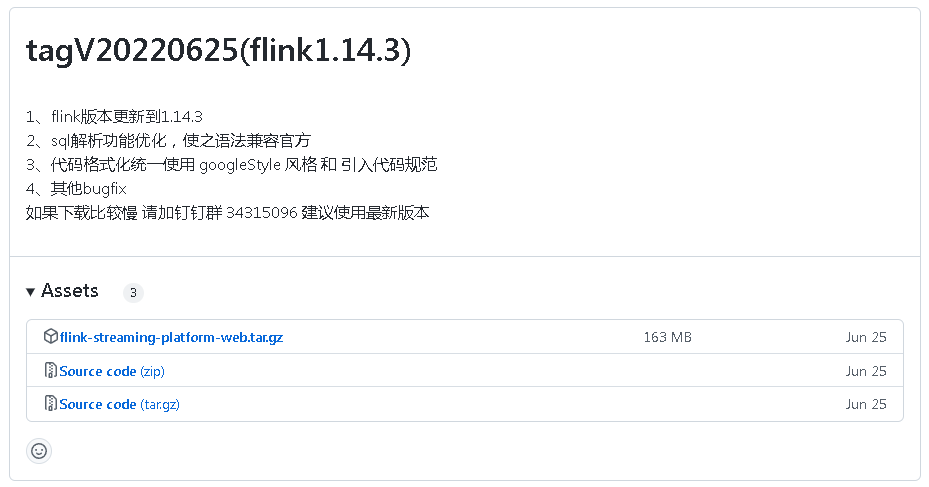
为什么我下的是适配flink 1.14.3的,我前面安装flink1.13.5,我也是下了一堆flink,经过尝试,才发现flink1.13.5这个版本,适配flink-streaming-platform-web tagV20220625.
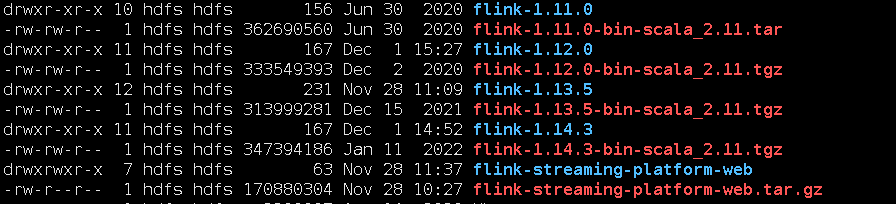
解压后,修改配置文件:application.properties,懂的人知道这个其实是个springboot的配置文件.
#### jdbc信息
server.port=9084
spring.datasource.url=jdbc:mysql://192.168.1.1:3306/flink_web?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.username=bigdata
spring.datasource.password=bigdata
这里配置了一个数据库,需要自己新建一下,建表语句作者给出了: https://github.com/zhp8341/flink-streaming-platform-web/blob/master/docs/sql/flink_web.sql,把这段sql执行一下,在flink_web数据库建相应的一些整个系统运行需要的表.
启动web服务 。
# bin目录下面的命令
启动 : sh deploy.sh start
停止 : sh deploy.sh stop
服务启动后,通过9084端口在浏览器访问 。

这一步很关键,页面上点击系统设置,进入配置页面:

这里的参数意义:
经过测试,配置这3个参数即可使用.
这里以 官方demo 为例,[ demo1 单流kafka写入mysqld 参考 ]( https://github.com/zhp8341/flink-streaming-platform-web/blob/master/docs/sql_demo/demo_1.md ),这是一个通过flink sql消费kafka,聚合结果写入mysql的例子.
CREATE TABLE sync_test_1 (
`day_time` varchar(64) NOT NULL,
`total_gmv` bigint(11) DEFAULT NULL,
PRIMARY KEY (`day_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
因为涉及到kafka和mysql,需要对应的connector依赖jar包,下图中标注出来了,放在Flink的lib目录(/var/lib/hadoop-hdfs/flink-1.13.5/lib)下面:
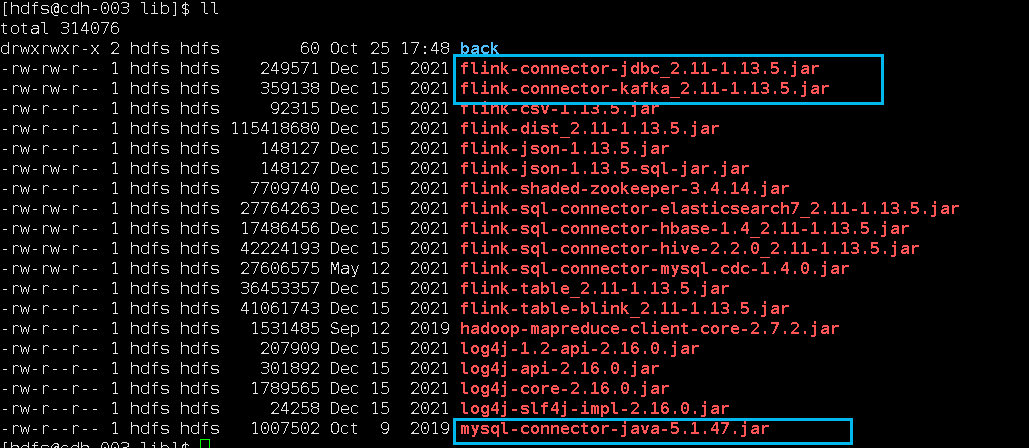
wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-jdbc_2.11/1.13.5/flink-connector-jdbc_2.11-1.13.5.jar
https://repo1.maven.org/maven2/org/apache/flink/flink-connector-kafka_2.11/1.13.5/flink-connector-kafka_2.11-1.13.5.jar
技巧 :下载Flink的依赖jar包,有个地方下载很方便,地址是:
https://repo1.maven.org/maven2/org/apache/flink/ 。
这样依赖,一切都准备好了.
在web页面新建sql流任务:
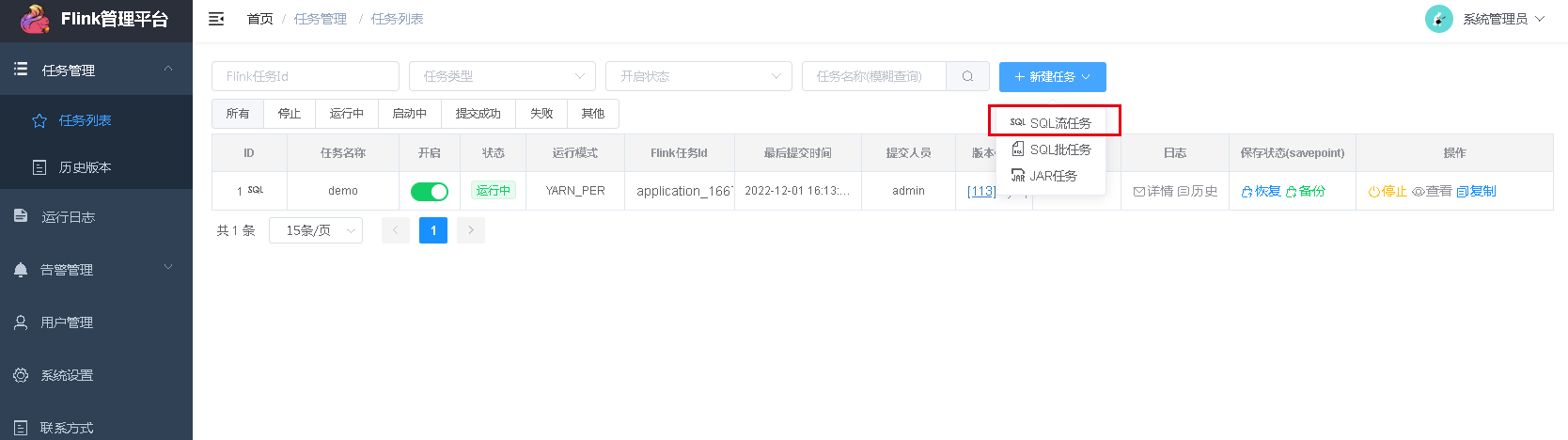
我建的一个,任务属性我是这样填写的:
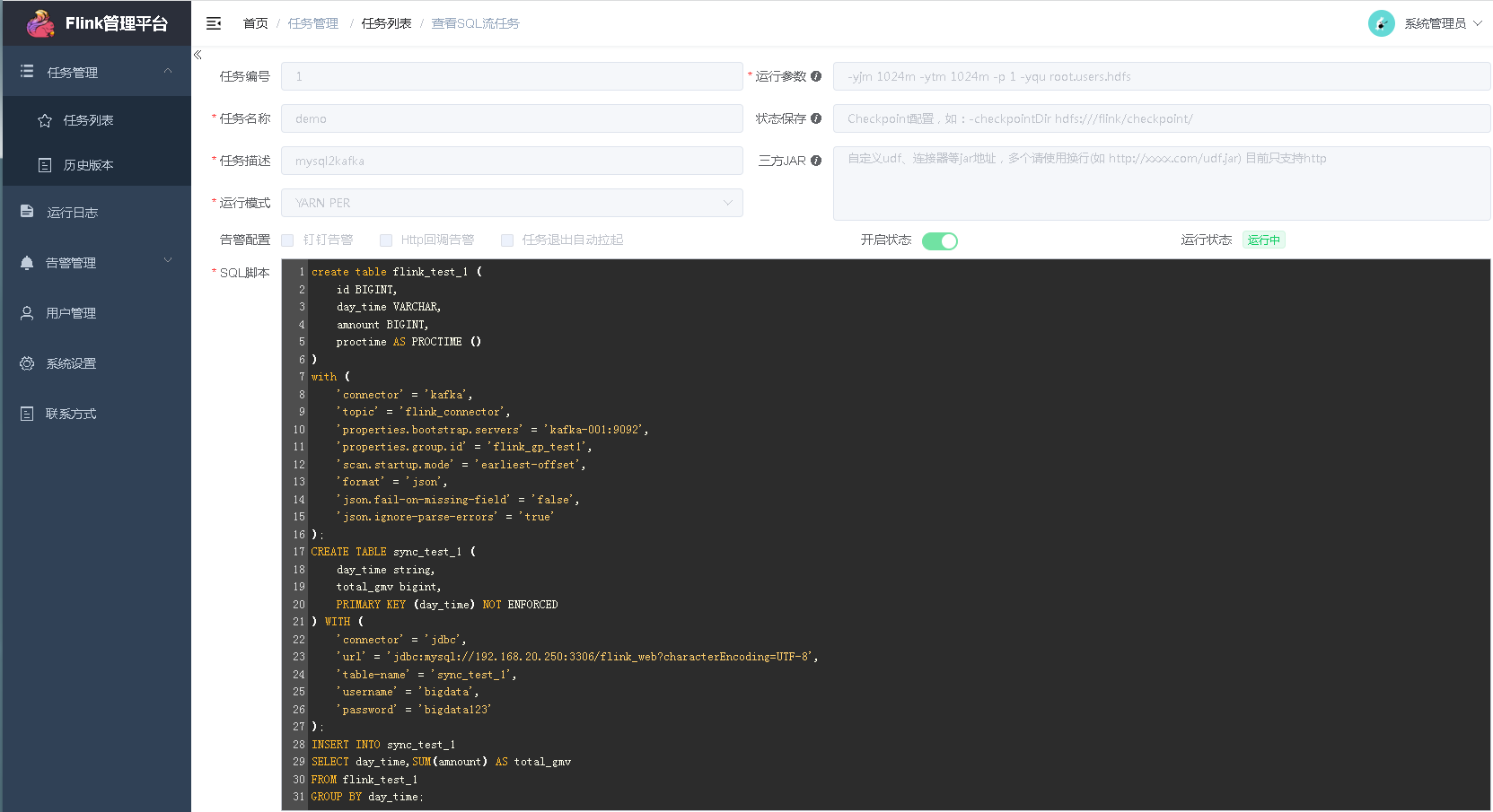
sql脚本内容:
create table flink_test_1 (
id BIGINT,
day_time VARCHAR,
amnount BIGINT,
proctime AS PROCTIME ()
)
with (
'connector' = 'kafka',
'topic' = 'flink_connector',
'properties.bootstrap.servers' = 'kafka-001:9092',
'properties.group.id' = 'flink_gp_test1',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true'
);
CREATE TABLE sync_test_1 (
day_time string,
total_gmv bigint,
PRIMARY KEY (day_time) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.168.1.1:3306/flink_web?characterEncoding=UTF-8',
'table-name' = 'sync_test_1',
'username' = 'bigdata',
'password' = 'bigdata'
);
INSERT INTO sync_test_1
SELECT day_time,SUM(amnount) AS total_gmv
FROM flink_test_1
GROUP BY day_time;
创建好任务后,启动任务吧.
启动后,可以在yarn的8088端口页面看到起了一个application,名称是新建任务填写的名称加flink@前缀:
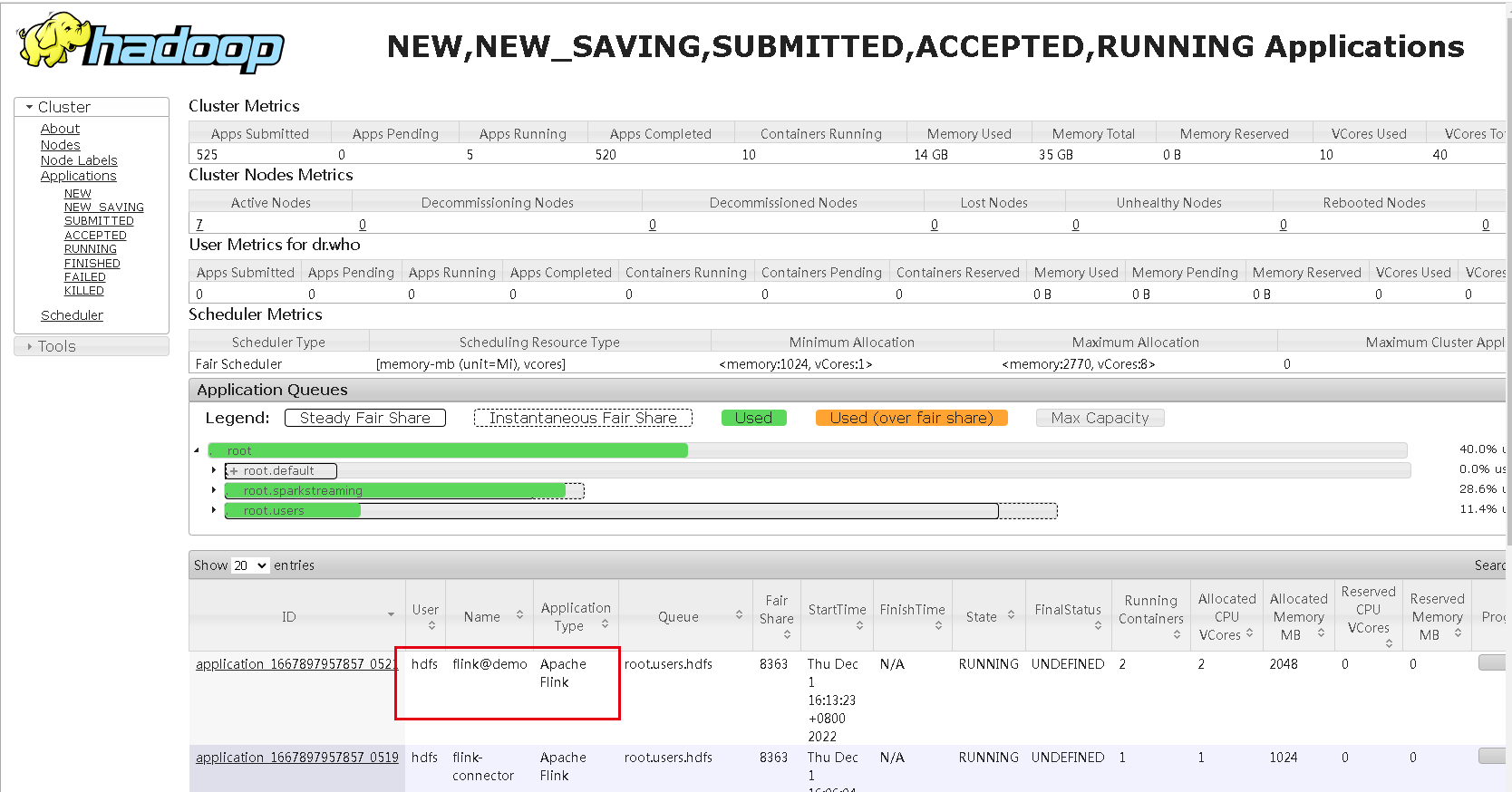
这个任务,我们点进去看,通过管理平台提交的sql任务确实跑起来了,这个页面了解Flink的同学就很熟悉了:

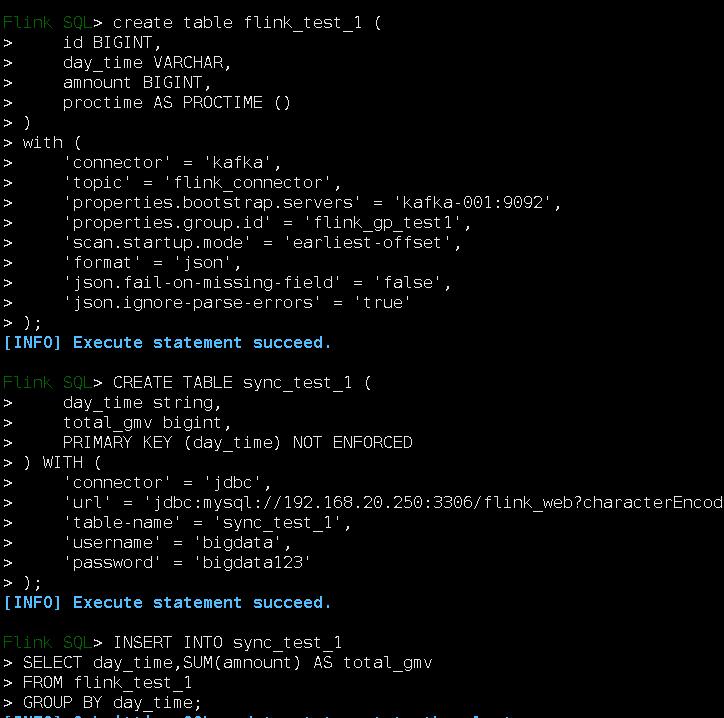
其实,这段sql脚本,我们可以在flink的bin/sql-client.sh进入的那个小松鼠的黑框里面执行的,你们可以试一下.
kafka控制台往主题里面写数据,主题不存在会自动创建:

我们再看看mysql里面:
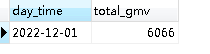
数据已经进来了.
我们可以看到,flink-streaming-platform-web这个工具只是让我们不需要在这个黑框里面写sql了,而是在网页上面写sql,系统会把写的sql进行校验给flink去执行,不管是flink-streaming-platform-web网页也好,还是那个黑框sql控制台,都是客户端,本质上都是flink提供的一些table api去执行任务.
最后此篇关于FlinkSQL管理平台flink-streaming-platform-web安装搭建的文章就讲到这里了,如果你想了解更多关于FlinkSQL管理平台flink-streaming-platform-web安装搭建的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
为了构建 CentOS 6.5 OSM 切片服务器,我正在寻找一些文档和/或教程。 我试过this one正如我在我的 previous post 中所说的那样但它适用于 Ubuntu 14.04,而
我正在寻找可用于集成任何源代码控制管理系统的通用 git 桥(如 git-svn、git-p4、git-tfs)模板。 如果没有这样的模板,至少有一些关于如何在 git 端集成基本操作的说明(对于其他
1、前言 redis在我们企业级开发中是很常见的,但是单个redis不能保证我们的稳定使用,所以我们要建立一个集群。 redis有两种高可用的方案: High availabilit
简介 前提条件: 确保本机已经安装 VS Code。 确保本机已安装 SSH client, 并且确保远程主机已安装 SSH server。 VSCode 已经安装了插件 C/
为什么要用ELK ELK实际上是三个工具,Elastricsearch + Logstash + Kibana,通过ELK,用来收集日志还有进行日志分析,最后通过可视化UI进行展示。一开始业务量比
在日常办公当中,经常会需要一个共享文件夹来存放一些大家共享的资料,为了保证文件数据的安全,最佳的方式是公司内部服务器搭建FTP服务器,然后分配多个用户给相应的人员。今天给大家分享FileZilla搭
最近由于业务需要,开始进行 Flutter 的研究,由于 Flutter 的环境搭建在官网上有些细节不是很清楚,笔者重新整理输出 1. 配置镜像 由于在国内访问 Flutter
目录 1. 安装go软件包 2. 配置系统变量 3. 安装git 4. 设置go代理 5. 下载gin框架 6. 创建项目 7.
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任
上篇文章给大家介绍了使用docker compose安装FastDfs文件服务器的实例详解 今天给大家介绍如何使用 docker compose 搭建 fastDFS文件服务器,内容详情如下所示:
目录 1.创建Maven 2.Maven目录和porm.xml配置 3.配置Tomcat服务器 1.创建Maven
laravel 官方提供 homestead 和 valet 作为本地开发环境,homestead 是一个官方预封装的 vagrant box,也就是一个虚拟机,但是跟 docker 比,它占用体积
这个tutorial显示了 Razor Pages 在 Asp.Net Core 2 中的实现。但是,当我运行 CLI 命令时: dotnet aspnet-codegenerator razorp
我创建了一个单独的类库项目来存储数据库上下文和模型类。在同一解决方案中,我创建了一个 ASP.NET MVC 项目并引用了类库项目,并在项目的 Web.config 文件中包含了数据库上下文的连接字符
关于代码托管,公司是基于Gitlab自建的,它功能全而强大,但是也比较重,我个人偏向于开源、小巧、轻便、实用,所以就排除了Github,在Gogs和Gitea中选者。Gogs在Github有38
目录 1、高可用简介 1.1 高可用整体架构 1.2 基于 QJM 的共享存储系统的数据同步机制分析 1.3 NameNode 主
Nginx 是由 Igor Sysoev 为俄罗斯访问量第二的 Rambler.ru 站点开发的,它已经在该站点运行超过两年半了。Igor 将源代码以类BSD许可证的形式发布。 在高并发连接的情况
对于我们的 ASP.NET Core 项目,我们使用包管理器控制台中的 Scaffold-DbContext 搭建现有数据库。 每次我们做脚手架时,上下文类与所有实体一起生成,它包含调用 option
我正在使用 .net 核心 2.0。我已经安装了以下 nuget 包:1: Microsoft.AspNetCore.All2: Microsoft.EntityFrameworkCore.Tools
我正在使用 NetBeans 及其 RAD 开发功能开发 JEE6 JSF 应用程序。我想使用脚手架来节省更新 Controller 和模型 View 的时间。 OneToMany 关联在 View

我是一名优秀的程序员,十分优秀!