
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


本篇论文主要介绍DALL·E 2模型,它是OpenAI在2022年4月推出的一款模型,OpenAI在2021年1月推出了DALL·E模型,2021年年底推出了GLIDE模型.
DALL·E 2可以根据文本描述去生成原创性的、真实的图像,这些图像从来没有在训练集里出现过,模型真的学习到了文本图像特征,可以任意地组合其概念、属性、风格.
DALL·E 2除了根据文本生成图像,还能根据文本对已有的图像进行编辑和修改——可以任意添加或者移除图像里的物体,修改时甚至可以把阴影、光线和物体纹理都考虑在内.
DALL·E 2可以在没有文本输入的情况下,做一些图像生成的工作——比如给定一张图像,它可以根据已有的图像和它的风格,去生成很多类似这种风格的图像.
DALL·E 2颠覆了人们对于AI的传统理解——AI不止可以处理重复性工作,也能胜任创造性工作.
DALL·E 2和DALL·E相比,分辨率是前者的四倍,且生成的图像更真实,与文本描述更贴切.
考虑到安全性和伦理性方面,DALL·E 2没有开源,连API也没有开放.

基于CLIP的分层文本条件图像生成——使用CLIP训练好的特征,来做层级式的依托于文本的图像生成工作.
所谓的层级式,意思是DALL·E 2模型是先生成一个64 * 64的小分辨率图像,再利用一个模型上采样到256 * 256,然后继续利用一个模型上采样到1024 * 1024,得到最终的一个高清大图,所以说是一个层级式的结构.
本文提出了一个两阶段的模型:
该模型有两个亮点:
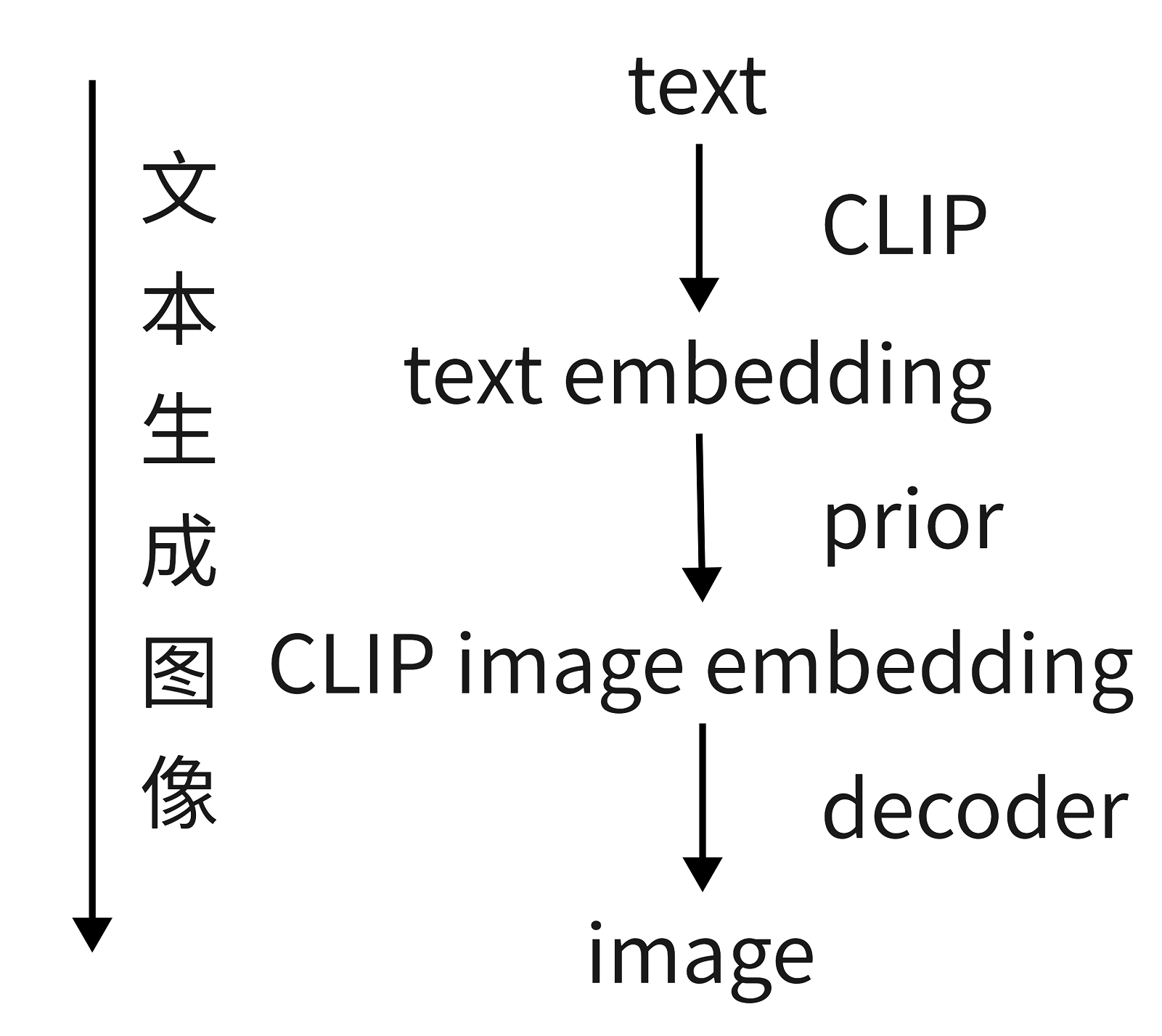
CLIP的优点:
生成扩散模型的优点:
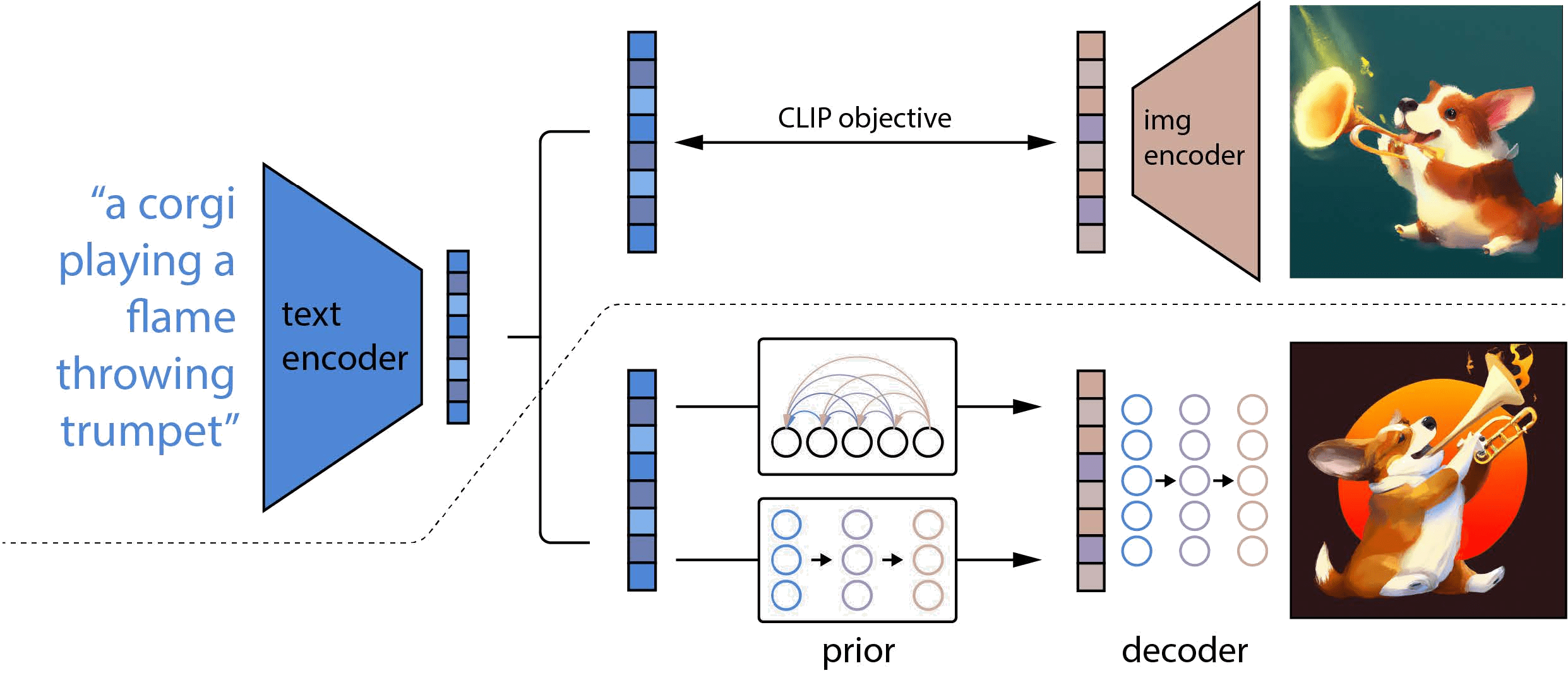
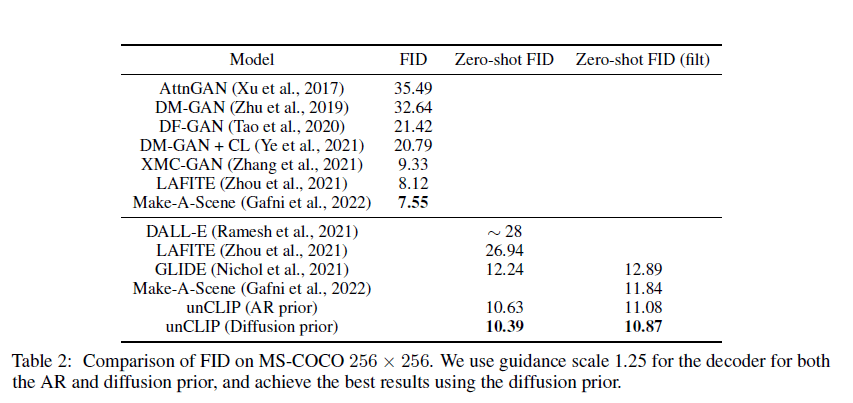
在图示中,虚线的上半部分是CLIP的训练过程,虚线的下半部分描述的DALL·E 2的训练过程.
对于CLIP,在训练时,将文本以及对应的图像分别输入文本编码器和图像编码器,然后得到输出的文本特征和图像特征,这两个特征就是一个正样本,该文本特征与其他图像生成的图像特征就是负样本,通过对比学习,训练文本编码器和图像编码器,从而实现文本的特征和图像的特征联系在一起,成为一个合并的多模态的特征空间。一旦CLIP模型训练结束,文本编码器和图像编码器就冻结了。在DALL·E 2的训练过程中,CLIP就处于冻结状态,没有进行任何训练和微调.
对于DALL·E 2,在训练时,首先将文本和对应的图像分别输入CLIP的文本编码器和图像编码器,在拿到文本特征后,将其喂入prior模型,由它生成图像特征,在这个过程中,由CLIP图像编码器生成的图像特征充当了ground truth的角色进行监督;在推理时,也就是只有文本没有配对图像的时候,其过程就是将文本输入CLIP文本编码器生成文本特征,文本特征通过prior模型生成图像特征,图像特征通过扩散模型生成最后的图像。DALL·E 2其实就是把CLIP和GLIDE合在一起,GLIDE模型是一个基于扩散模型的文本图像生成的方法.
DALL·E 2也被作者称为unCLIP。对于CLIP来说,它是给定文本和图像,然后得到特征,可以拿特征去做图像匹配、图像检索之类的工作,是一个从输入到特征的过程;对于DALL·E 2来说,它是通过文本特征,然后到图像特征,最后到图像的过程,其实就是CLIP的反过程,把特征又还原到数据,所以整个框架叫做unCLIP.
训练数据集采用图像文本对,给定图像x,用z i 表示从CLIP出来的图像特征,z t 表示从CLIP出来的文本特征,整个模型的网络结构被分成prior模型和decoder模型.
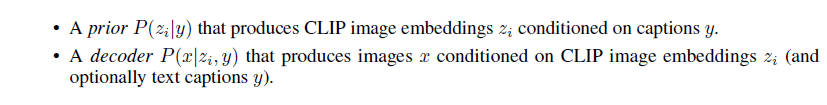
首先准备一个CLIP模型,然后训练DALL·E 2的图像生成模型——给定任意文本将它通过CLIP的文本编码器,得到一个文本特征,然后用prior模型把文本特征变成图像特征,再通过一个解码器,把图像特征变成了几张图像.
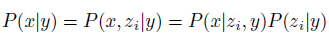
P(x|y)表示给定一个文本y,生成图像x的概率; 。
P(x,z i |y)表示给定一个文本y,生成图像x和图像特征z i 的概率。因为图像特征z i 和图像是一对一的关系,所以z i 和x是对等的,所以左边第一个等号成立; 。
P(x|z i ,y)表示给定一个文本y和图像特征z i 去生成图像x的概率(decoder); 。
P(z i |y)表示给定一个文本y,生成图像特征z i 的概率(prior).
本文的解码器其实就是GLIDE模型的变体,用了CLIP guidance和classifier-free guidance.
guidance信号要么来自CLIP模型,要么来自于文本,作者随机设10%的时间令CLIP的特征为0,并且训练的时候有50%的时间把文本直接丢弃.
在生成图像时采用级联式生成的方法,由64 * 64逐步生成得到1024 * 1024的高清大图,为了训练的稳定性,在训练时加了很多噪声.

prior模型不论是用自回归模型还是扩散模型,都使用了classifier-free guidance.
对于扩散prior来说,作者训练了一个Transformer的decoder,因为它的输入输出是embedding,所以不合适用U-Net,选择直接用Transformer处理这个序列.
生成给定图像的很多类似图像,所生成的图像风格和原始图像一致,图像中所出现的物体也大体一致.
其方法是当用户给定一张图像的时候,通过CLIP的图像编码器得到一个图像特征,把图像特征变成文本特征,再把文本特征输入给prior模型生成另外一个图像特征,这个图像特征再生成新的图像.

给定两张图像,在两张图像的图像特征之间做内插,当插出来的特征更偏向于某个图像时,所生成的图像也就更多地具有该图像的特征.


不能很好地把物体和属性联系起来(很有可能是CLIP模型的原因).

当生成的图像里有文字时,文字是错误的(有可能是文本编码器使用了BPE编码).

不能生成特别复杂的场景,很多细节生成不出来.

GAN包含有两个模型,一个是生成模型(generative model),一个是判别模型(discriminative model).
生成模型的任务是生成看起来自然真实的、和原始数据相似的实例。判别模型的任务是判断给定的实例看起来是自然真实的还是人为伪造的(真实实例来源于数据集,伪造实例来源于生成模型).
这可以看做一种零和游戏,生成模型像“一个造假团伙,试图生产和使用假币”,而判别模型像“检测假币的警察”。生成器(generator)试图欺骗判别器(discriminator),判别器则努力不被生成器欺骗。模型经过交替优化训练,两种模型都能得到提升,但最终我们要得到的是效果提升到很高很好的生成模型(造假团伙),这个生成模型(造假团伙)所生成的产品能达到真假难分的地步。因为GAN的目标函数是用来以假乱真的,所以截至目前为止,GAN生成的图像保真度非常高,引燃了DeepFakes的火爆,但是它的多样性不好,且不太具备原创性,这也是最近的模型如DALL·E 2和Imagen都是用扩散模型的原因,因为扩散模型多样性好,还有创造力.
GAN的缺点 。
是一种无监督式的学习模型,它基于反向传播算法与最优化方法(如梯度下降法),利用输入数据X本身作为监督,来指导神经网络尝试学习一个映射关系,从而得到一个重构输出X R .
算法模型包含Encoder(编码器)和Decoder(解码器).
编码器的作用是把高维输入X编码成低维隐变量h从而强迫神经网络学习最有信息量的特征; 。
解码器的作用是把隐藏层的隐变量h还原到初始维度,最好的状态就是解码器的输出能够完美地或者近似恢复出原来的输入, 即X R ≈X .
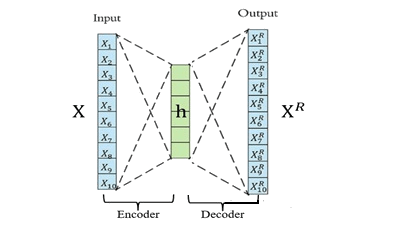
从输入层 ->隐藏层的原始数据X的编码过程:
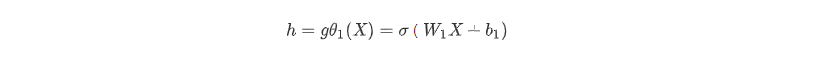
从隐藏层 -> 输出层的解码过程:
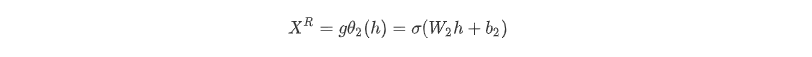
算法的优化目标函数:
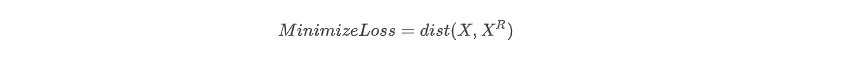
其中dist为二者的距离度量函数,通常用MSE(均方方差).
自编码可以实现类似于PCA等数据降维、数据压缩的特性。如果输入层神经元的个数n大于隐层神经元个数m,那么就相当于把数据从n维降到了m维;然后可以利用这m维的特征向量,重构原始的数据。这个跟PCA降维一模一样,只不过PCA是通过求解特征向量进行降维,是一种线性的降维方式,而自编码是一种非线性降维.
先向输入注入噪声,然后把经过扰乱的输入传给编码器,让解码器重构不含噪声的输入.
这种方法可以让训练的模型非常稳健,不容易过拟合,部分原因是因为图像像素冗余度太高了,所以即使把原来的图像做一些污染,模型还是能抓住它的本质,将它重建出来.
VAE其实跟AE很不一样,它不再是学习固定的隐藏层特征了,而是在学习一种分布,比如假设这个分布是一个高斯分布,可以用均值和方差描述,编码器不再直接输出h,而是输出h分布的均值和方差,再从这个分布中采样得到h,然后h再通过解码器。简而言之,VAE预测的是一个分布.
就是把VAE做量化,它采用的是离散的隐变量,不像VAE那样采用连续的隐变量.
把隐空间分成了两个,一个上层隐空间(top latent space),一个下层隐空间(bottom latent space)。上层隐向量 用于表示全局信息,下层隐向量 用于表示 局部信息.
由OpenAI提出的能根据文本描述生成类似超现实主义图像的图像生成器.
自回归模型是统计上一种处理时间序列的方法,用同一变数例如x的之前各期,亦即x 1 至x t-1 来预测本期x t 的表现,并假设它们为线性关系。因为这是从回归分析中的线性回归发展而来,只是不用x预测y,而是用x预测 x(自己),所以叫做自回归。神经网络中的自回归模型,将联合概率拆成了条件概率累乘的形式.
diffusion models名字来源于热力学的启发,工作原理从本质上来说是通过连续添加高斯噪声来破坏训练数据,然后通过反转这个噪声过程,来学习恢复数据.
它是Encoder-Decoder架构的模型,分为扩散阶段和逆扩散阶段.
在扩散阶段,通过不断对原始数据添加噪声,使数据从原始分布变为我们期望的分布,例如通过不断添加高斯噪声将原始数据分布变为正态分布.
在逆扩散阶段,使用神经网络(U-Net,一个CNN)将数据从正态分布恢复到原始数据分布.
训练后,可以使用该模型将原始输入的图像去噪生成新图像.
优点是正态分布上的每个点都是真实数据的映射,模型具有更好的可解释性。缺点是迭代采样速度慢,导致模型训练和预测效率低.
扩散模型早在2015年或者更早的时候就被提出来了,但当时只是一个想法,一直到2020年6月DDPM提出来后,扩散模型才开始火爆,DDPM算是扩散模型的开山之作.
DDPM对原始的扩散模型做了一些改进,把优化过程变得简单,有两个最重要的贡献:
DDPM和VAE有很多相似之处,都是编码器、解码器的结构,不同点在于:
improved DDPM相较于DDPM做了一些改进:
基于improved DDPM的第三个改进,有人发表了论文《Diffusion model beats GAN》,即扩散模型比GAN强。在文中:
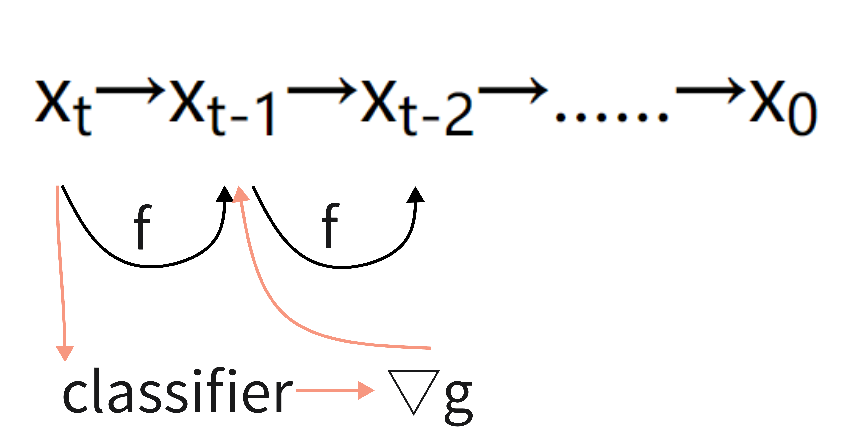
classifier guidance diffusion是说在我们训练扩散模型的同时,再训练一个图像分类器,这个分类器是在ImagNet上的图像加上噪声训练来的。分类器的作用是对于图像x t ,它可以计算一个交叉熵目标函数,得到一些梯度,然后使用这个梯度,去帮助模型进行采样和图像生成。分类器可以根据需求进行选择,把分类器换成CLIP模型,那么文本和图像就联系起来了,此时我们不光可以利用梯度去引导模型的采样和生成,甚至可以利用文本去控制图像的采样和生成.
classifier guidance diffusion的成本很高,它要求我们要么有一个pre-trained的模型,要么得重新训练一个模型,所以引出来后续的classifier-free guidance.
classifier-free guidance不使用分类器,而是在训练模型的时候让它生成两个输出,一个是在有条件时生成的,一个是在无条件时生成的。比如用图像文本对训练的时候,用文本去做这个guidance信号,生成一个图像,然后不用这个文本,而用一个空的序列,再去生成另外一个图像。假设生成的两个图像在一个空间里,那么就会有一个方向能从这种无文本得到的图像指向有文本得到的图像,通过训练得到二者之间的距离,那么等到反向扩散的时候,即使我们的图像输出是没有使用文本生成的,我们也能做出一个比较合理的推理,从一个没有条件生成的x变成一个有条件生成的x,摆脱分类器的限制。这个方法因为产生两个输出,模型的训练成本是很大的。在GLIDE、DALL·E 2、Imagen都使用了classifier-free guidance.
是一种自监督学习方法,用于在没有标签的情况下,通过让模型学习哪些数据点相似或不同来学习数据集的一般特征.
它是利用训练集数据训练模型,使得模型能够对测试集的对象进行分类,但是训练集类别和测试集类别之间没有交集,期间是借助类别的描述,来建立训练集和测试集之间的联系,从而使得模型有效。对于要分类的类别对象,是一次也不学习的.
是一种使用最广泛的数据降维算法。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴.
它能把万物嵌入万物,是沟通两个世界的桥梁。数学定义即:它是单射且同构的.
简单来说,我们常见的地图就是对于现实地理的Embedding,现实的地理地形的信息其实远远超过三维,但是地图通过颜色和等高线等来最大化表现现实的地理信息。通过它,我们在现实世界里的文字、图像、语言、视频就能转化为计算机能识别、能使用的语言,且转化的过程中信息不丢失.
可以通过矩阵乘法进行降维,假如我们有一个100W X10W的矩阵,用它乘上一个10W X 20的矩阵,我们可以把它降到100W X 20,瞬间量级降了10W/20=5000倍;也可以进行升维,对低维的数据进行升维时,可能把一些其他特征给放大了,或者把笼统的特征给分开了.
将数据转换(降维)为固定大小的特征表示(矢量),以便于处理和计算(如求距离).
将图像转换成n维的特征向量.
将非结构化的文本转换为n维结构化的特征向量.
原始数据压缩(编码)后的表示(即特征向量)所在的空间,即为潜在空间.
表示效果最好的方法.
最后此篇关于《HierarchicalText-ConditionalImageGenerationwithCLIPLatents》阅读笔记的文章就讲到这里了,如果你想了解更多关于《HierarchicalText-ConditionalImageGenerationwithCLIPLatents》阅读笔记的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
概括 模型总述 本篇论文主要介绍DALL·E 2模型,它是OpenAI在2022年4月推出的一款模型,OpenAI在2021年1月推出了DALL·E模型,202

我是一名优秀的程序员,十分优秀!