
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


本文已收录到 AndroidFamily ,技术和职场问题,请关注公众号 [彭旭锐] 提问.
大家好,我是小彭.
在上一篇文章里 ,我们聊到了ArrayList 的线程安全问题,其中提到了 CopyOnWriteArrayList 的解决方法。那么 CopyOnWriteArrayList 是如何解决线程安全问题的,背后的设计思想是什么,今天我们就围绕这些问题展开.
本文源码基于 Java 8 CopyOnWriteArrayList.
小彭的 Android 交流群 02 群已经建立啦,扫描文末二维码进入~ 。
思维导图:
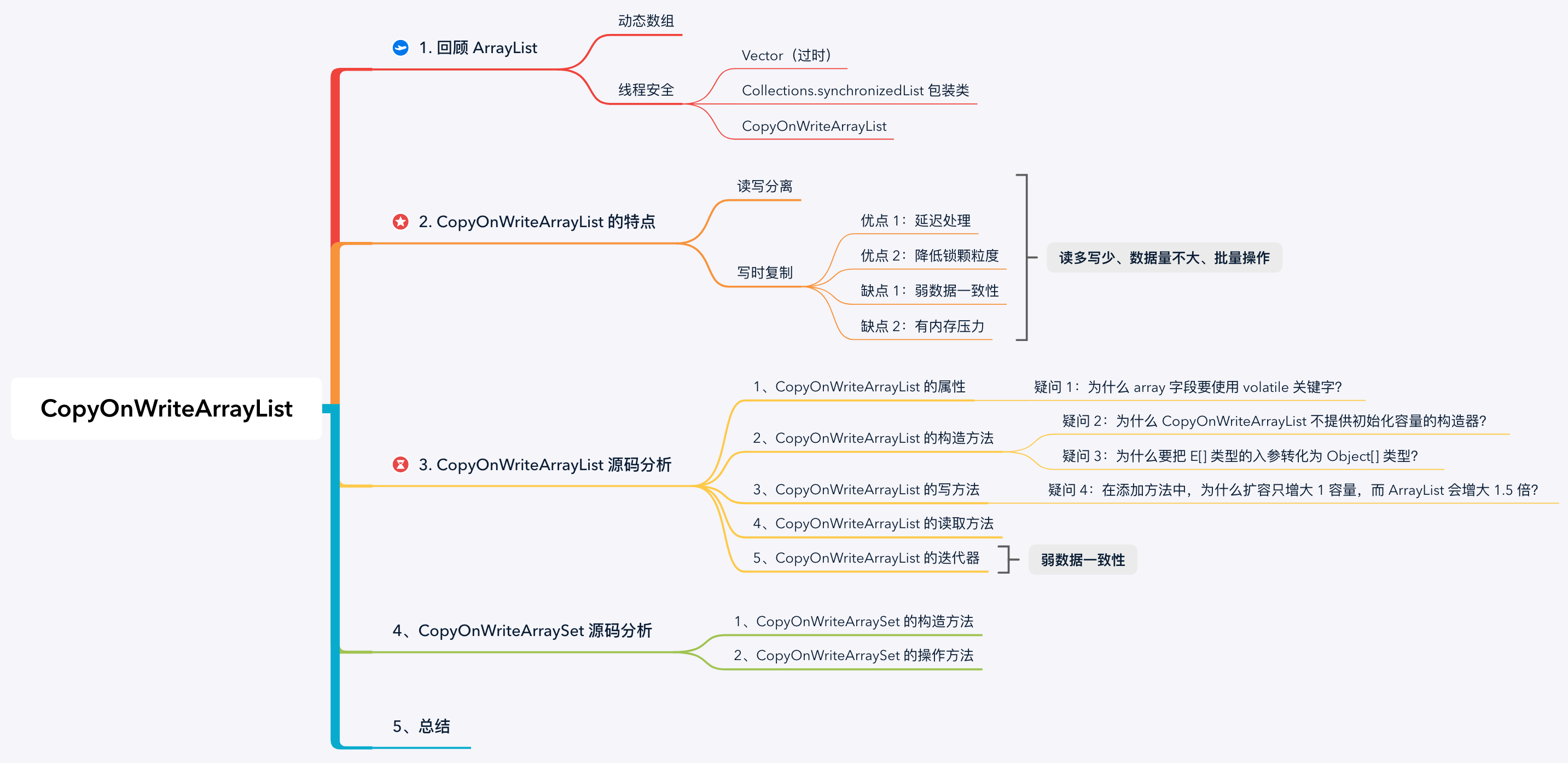
ArrayList 是基于数组实现的动态数据,是线程不安全的。例如,我们在遍历 ArrayList 的时候,如果其他线程并发修改数组(当然也不一定是被其他线程修改),在迭代器中就会触发 fail-fast 机制,抛出 ConcurrentModificationException 异常.
示例程序 。
List<String> list = new ArrayList();
list.add("xiao");
list.add("peng");
list.add(".");
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
// 可能抛出 ConcurrentModificationException 异常
iterator.next();
}
要实现线程安全有 3 种方式:
Collections.synchronizedList 包装类的原理很简单,就是使用 synchronized 加锁,源码摘要如下:
Collections.java 。
public static <T> List<T> synchronizedList(List<T> list) {
return (list instanceof RandomAccess ?
new SynchronizedRandomAccessList<>(list) :
new SynchronizedList<>(list));
}
// 使用 synchronized 实现线程安全
static class SynchronizedList<E> extends SynchronizedCollection<E> implements List<E> {
final List<E> list;
public boolean equals(Object o) {
if (this == o) return true;
synchronized (mutex) {return list.equals(o);}
}
public int hashCode() {
synchronized (mutex) {return list.hashCode();}
}
public E get(int index) {
synchronized (mutex) {return list.get(index);}
}
public E set(int index, E element) {
synchronized (mutex) {return list.set(index, element);}
}
public void add(int index, E element) {
synchronized (mutex) {list.add(index, element);}
}
public E remove(int index) {
synchronized (mutex) {return list.remove(index);}
}
...
}
如果我们将 ArrayList 替换为 CopyOnWriteArrayList,即使其他线程并发修改数组,也不会抛出 ConcurrentModificationException 异常,这是为什么呢?
CopyOnWriteArrayList 和 ArrayList 都是基于数组的动态数组,封装了操作数组时的搬运和扩容等逻辑。除此之外,CopyOnWriteArrayList 还是用了基于加锁的 “读写分离” 和 “写时复制” 的方案解决线程安全问题:
所以,使用 CopyOnWriteArrayList 的场景一定要保证是 “读多写少” 且数据量不大的场景,而且在写入数据的时候,要做到批量操作。否则每个写入操作都会触发一次复制,想想就可怕。举 2 个例子:
这一节,我们来分析 CopyOnWriteArrayList 中主要流程的源码.
ArrayList 的属性很好理解,底层是一个 Object 数组,我要举手提问 🙋🏻♀️:
// 锁
final transient ReentrantLock lock = new ReentrantLock();
// 在 Java 11 中,ReentrantLock 被替换为 synchronized 锁
// The lock protecting all mutators. (We have a mild preference for builtin monitors over ReentrantLock when either will do.)
final transient Object lock = new Object();
// 底层数组
// 疑问 1:为什么 array 要使用 volatile 关键字?
private transient volatile Object[] array;
这个问题我们在分析源码的过程中回答。有了 ArrayList 的分析基础,疑问也变少了,CopyOnWriteArrayList 真香.
构造器的源码不难,但小朋友总有太多的问号,举手提问 🙋🏻♀️:
这是因为 CopyOnWriteArrayList 建议我们使用批量操作写入数据。如果提供了带初始化容量的构造器,意味着开发者预期会一个个地写入数据,这不符合 CopyOnWriteArrayList 的正确使用方法。所以,不提供这个构造器才是合理的.
如果不转化数组类型,那么在 toArray() 方法返回的数组中插入 Object 类型对象时,会抛出 ArrayStoreException .
提示: 这个问题与 “奇怪” 分支的原因相同,具体分析可以看讲 《Java 面试题:ArrayList 可以完全替代数组吗?》 的文章中,这里不重复讲了.
// 疑问 2:为什么 CopyOnWriteArrayList 不提供预初始化容量的构造器?
// 无参构造方法
public CopyOnWriteArrayList() {
// 创建空数组
setArray(new Object[0]);
}
// 带集合的构造方法
public CopyOnWriteArrayList(Collection<? extends E> c) {
Object[] elements;
if (c.getClass() == CopyOnWriteArrayList.class)
elements = ((CopyOnWriteArrayList<?>)c).getArray();
else {
elements = c.toArray();
// 这个“奇怪”的分支在 ArrayList 文章中分析过,去看看
if (elements.getClass() != Object[].class)
elements = Arrays.copyOf(elements, elements.length, Object[].class);
}
setArray(elements);
}
// 带数组的构造方法
public CopyOnWriteArrayList(E[] toCopyIn) {
// 疑问 3:为什么要把 E[] 类型的入参转化为 Object[] 类型
setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, *Object[]*.class));
}
final Object[] getArray() {
return array;
}
final void setArray(Object[] a) {
array = a;
}
public Object[] toArray() {
Object[] elements = getArray();
return Arrays.copyOf(elements, elements.length);
}
我们将 CopyOnWriteArrayList 的添加、删除和修改方法统一为 “写方法”,三种写方法的模板其实是一样的:
小朋友总是有太多问号,举手提问 🙋🏻♀️:
这还是因为 CopyOnWriteArrayList 建议我们使用批量操作写入数据。ArrayList 额外扩容 1.5 倍是为了避免每次 add 都扩容,而 CopyOnWriteArrayList 并不建议一个个地添加数据,而是建议批量操作写入数据,例如 addAll 方法。所以,CopyOnWriteArrayList 不额外扩容才是合理的.
另外,网上有观点看到 CopyOnWriteArrayList 没有限制数组最大容量, 就说 CopyOnWriteArrayList 是无界的,没有容量限制 。这显然太表面了。数组的长度限制是被虚拟机固化的,CopyOnWriteArrayList 没有限制的原因是:它没有做额外扩容,而且不适合大数据的场景,所以没有限制的必要.
最后还剩下 1 个问题:
volatile 变量是 Java 轻量级的线程同步原语,volatile 变量的读取和写入操作中会加入内存屏障,能够保证变量写入的内存可见性,保证一个线程的写入能够被另一个线程观察到.
添加方法 。
// 在数组尾部添加元素
public boolean add(E e) {
final ReentrantLock lock = this.lock;
// 获取锁
lock.lock();
// 复制新数组
Object[] elements = getArray();
int len = elements.length;
// 疑问 4:在添加方法中,为什么扩容只增大 1 容量,而 ArrayList 会增大 1.5 倍?
Object[] newElements = Arrays.copyOf(elements, len + 1 /* 容量 + 1*/);
// 在新数组上添加元素
newElements[len] = e;
// 设置新数组
setArray(newElements);
// 释放锁
lock.unlock();
return true;
}
// 在数组尾部添加元素
public void add(int index, E element) {
// 原理相同,省略
...
}
// 批量在数组尾部添加元素
public boolean addAll(Collection<? extends E> c) {
// 原理相同,省略
...
}
修改方法 。
// 修改数组元素
public E set(int index, E element) {
final ReentrantLock lock = this.lock;
// 获取锁
lock.lock();
// 旧元素
Object[] elements = getArray();
E oldValue = get(elements, index);
if (oldValue != element) {
// 复制新数组
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len);
// 在新数组上添加元素
newElements[index] = element;
// 设置新数组
setArray(newElements);
} else {
// Not quite a no-op; ensures volatile write semantics
setArray(elements);
}
// 释放锁
lock.unlock();
// 返回旧数据
return oldValue;
}
删除方法 。
// 删除数组元素
public E remove(int index) {
final ReentrantLock lock = this.lock;
// 获取锁
lock.lock();
Object[] elements = getArray();
int len = elements.length;
// 旧元素
E oldValue = get(elements, index);
int numMoved = len - index - 1;
if (numMoved == 0)
// 删除首位元素
setArray(Arrays.copyOf(elements, len - 1));
else {
// 删除中间元素
// 复制新数组
Object[] newElements = new Object[len - 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index, numMoved);
// 设置新数组
setArray(newElements);
}
// 释放锁
lock.unlock();
// 返回旧数据
return oldValue;
}
可以看到读取方法并没有加锁.
private E get(Object[] a, int index) {
return (E) a[index];
}
public E get(int index) {
return get(getArray(), index);
}
public boolean contains(Object o) {
Object[] elements = getArray();
return indexOf(o, elements, 0, elements.length) >= 0;
}
CopyOnWriteArrayList 的迭代器 COWIterator 是 “弱数据一致性的” ,所谓数据一致性问题讨论的是同一份数据在多个副本之间的一致性问题,你也可以理解为多个副本的状态一致性问题。例如内存与多核心 Cache 副本之间的一致性,或者数据在主从数据库之间的一致性.
提示: 关于 “数据一致性和顺序一致性” 的区别,在小彭的计算机组成原理专栏讨论过 《已经有 MESI 协议,为什么还需要 volatile 关键字?》 ,去看看.
为什么是 “弱” 的呢?这是因为 COWIterator 迭代器会持有 CopyOnWriteArrayList “底层数组” 的引用,而 CopyOnWriteArrayList 的写入操作是写入到新数组,因此 COWIterator 是无法感知到的,除非重新创建迭代器.
相较之下,ArrayList 的迭代器是通过持有 “外部类引用” 的方式访问 ArrayList 的底层数组,因此在 ArrayList 上的写入操作会实时被迭代器观察到.
CopyOnWriteArrayList.java 。
// 注意看:有 static 关键字,直接引用底层数组
static final class COWIterator<E> implements ListIterator<E> {
// 底层数组
private final Object[] snapshot;
private int cursor;
private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
snapshot = elements;
}
}
ArrayList.java 。
// 注意看:没有 static 关键字,通过外部类引用来访问底层数组
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
Itr() {}
...
}
与 ArrayList 类似,CopyOnWriteArraySet 也重写了 JDK 序列化的逻辑,只把 elements 数组中有效元素的部分序列化,而不会序列化整个数组.
同时, ReentrantLock 对象是锁对象,序列化没有意义。在反序列化时,会通过 resetLock() 设置一个新的 ReentrantLock 对象.
// 序列化过程
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException {
s.defaultWriteObject();
Object[] elements = getArray();
// 写入数组长度
s.writeInt(elements.length);
// 写入有效元素
for (Object element : elements)
s.writeObject(element);
}
// 反序列化过程
private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException {
s.defaultReadObject();
// 设置 ReentrantLock 对象
resetLock();
// 读取数组长度
int len = s.readInt();
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, len);
// 创建底层数组
Object[] elements = new Object[len];
// 读取数组对象
for (int i = 0; i < len; i++)
elements[i] = s.readObject();
// 设置新数组
setArray(elements);
}
// 疑问 5:resetLock() 方法不好理解,解释一下?
private void resetLock() {
// 等价于带 Volatile 语义的 this.lock = new ReentrantLock()
UNSAFE.putObjectVolatile(this, lockOffset, new ReentrantLock());
}
// Unsafe API
private static final sun.misc.Unsafe UNSAFE;
// lock 字段在对象实例数据中的偏移量
private static final long lockOffset;
static {
// 这三行的作用:lock 字段在对象实例数据中的偏移量
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = CopyOnWriteArrayList.class;
lockOffset = UNSAFE.objectFieldOffset(k.getDeclaredField("lock"));
}
小朋友又是有太多问号,举手提问 🙋🏻♀️:
resetLock() 方法不好理解,解释一下? 在 static 代码块中,会使用 Unsafe API 获取 CopyOnWriteArrayList 的 “ lock 字段在对象实例数据中的偏移量” 。由于字段的偏移是全局固定的,所以这个偏移量可以记录在 static 字段 lockOffset 中.
在 resetLock() 中,通过 UnSafe API putObjectVolatile 将新建的 ReentrantLock 对象设置到 CopyOnWriteArrayList 的 lock 字段中,等价于带 volatile 语义的 this.lock = new ReentrantLock() ,保证这个字段的写入具备内存可见性.
字段的偏移量是什么意思呢?简单来说,普通对象和 Class 对象的实例数据区域是不同的:
对象内存布局 。
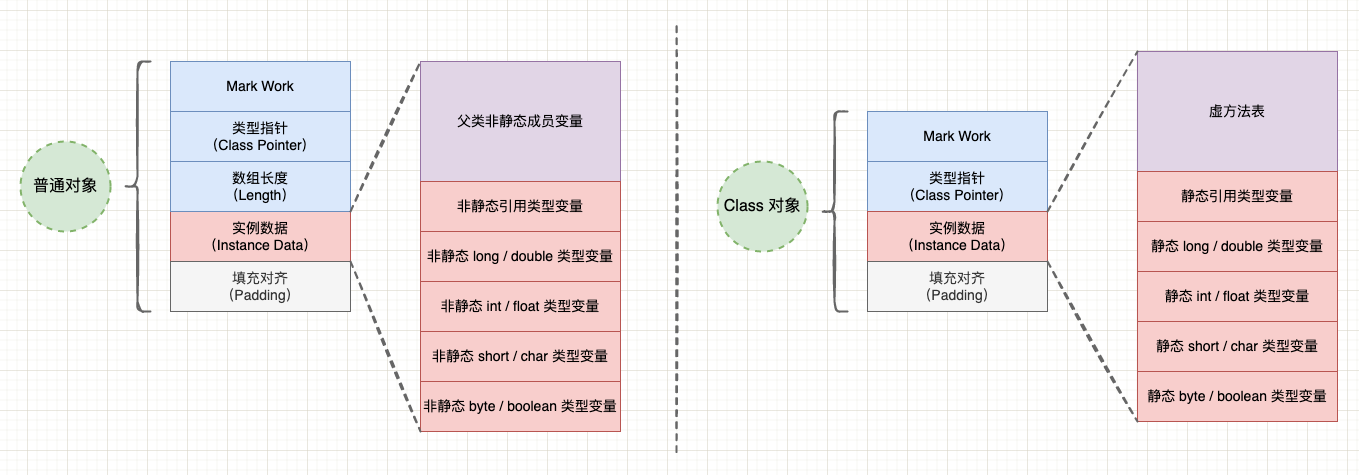
提示: 关于字段的偏移量,我们在 《对象的内存分为哪几个部分?》 这篇文章里讨论过,去看看.
CopyOnWriteArraySet 的 clone() 很巧妙。按照正常的思维,CopyOnWriteArraySet 中的 array 数组是引用类型,因此在 clone() 中需要实现深拷贝,否则原对象与克隆对象就会相互影响。但事实上, array 数组并没有被深拷贝,哇点解啊?
这就是因为 CopyOnWrite 啊!没有 Write 为什么要 Copy 呢?(我觉得已经提醒到位了,只要你仔细阅读前文对 CopyOnWrite 的论证,你一定会懂的。要是是在不懂,私信我吧~) 。
public Object clone() {
try {
@SuppressWarnings("unchecked")
// 疑问 6:为什么 array 数组没有深拷贝?
CopyOnWriteArrayList<E> clone = (CopyOnWriteArrayList<E>) super.clone();
// 设置 ReentrantLock 对象(相当于 lock 字段的深拷贝)
clone.resetLock();
return clone;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError();
}
}
在 Java 标准库中,还提供了一个使用 COW 思想的 Set 集合 —— CopyOnWriteArraySet.
CopyOnWriteArraySet 和 HashSet 都是继承于 AbstractSet 的,但 CopyOnWriteArraySet 是基于 CopyOnWriteArrayList 动态数组的,并没有使用哈希思想。而 HashSet 是基于 HashMap 散列表的,能够实现 O(1) 查询.
看一下 CopyOnWriteArraySet 的构造方法,底层就是有一个 CopyOnWriteArrayList 动态数组.
CopyOnWriteArraySet.java 。
public class CopyOnWriteArraySet<E> extends AbstractSet<E> implements java.io.Serializable {
// 底层就是 OnWriteArrayList
private final CopyOnWriteArrayList<E> al;
// 无参构造方法
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
// 带集合的构造方法
public CopyOnWriteArraySet(Collection<? extends E> c) {
if (c.getClass() == CopyOnWriteArraySet.class) {
// 入参是 CopyOnWriteArraySet,说明是不重复的,直接添加
CopyOnWriteArraySet<E> cc = (CopyOnWriteArraySet<E>)c;
al = new CopyOnWriteArrayList<E>(cc.al);
}
else {
// 使用 addAllAbsent 添加不重复的元素
al = new CopyOnWriteArrayList<E>();
al.addAllAbsent(c);
}
}
public int size() {
return al.size();
}
}
CopyOnWriteArraySet 的方法基本上都是交给 CopyOnWriteArraySet 代理的,由于没有使用哈希思想,所以操作的时间复杂度是 O(n).
CopyOnWriteArraySet.java 。
public boolean add(E e) {
return al.addIfAbsent(e);
}
public boolean contains(Object o) {
return al.contains(o);
}
CopyOnWriteArrayList.java 。
public boolean addIfAbsent(E e) {
Object[] snapshot = getArray();
return indexOf(e, snapshot, 0, snapshot.length) >= 0 ? false : addIfAbsent(e, snapshot);
}
public boolean contains(Object o) {
Object[] elements = getArray();
return indexOf(o, elements, 0, elements.length) >= 0;
}
// 通过线性扫描匹配元素位置,而不是计算哈希匹配,时间复杂度是 O(n)
private static int indexOf(Object o, Object[] elements, int index, int fence) {
if (o == null) {
for (int i = index; i < fence; i++)
if (elements[i] == null) return i;
} else {
for (int i = index; i < fence; i++)
if (o.equals(elements[i])) return i;
}
return -1;
}
1、CopyOnWriteArrayList 和 ArrayList 都是基于数组的动态数组,封装了操作数组时的搬运和扩容等逻辑; 。
2、CopyOnWriteArrayList 还是 “读写分离” 和 “写时复制” 的方案解决线程安全问题; 。
3、使用 CopyOnWriteArrayList 的场景一定要保证是 “读多写少” 且数据量不大的场景,而且在写入数据的时候,要做到批量操作; 。
4、CopyOnWriteArrayList 的迭代器是 “弱数据一致性的” 的,迭代器会持有 “底层数组” 的引用,而 CopyOnWriteArrayList 的写入操作是写入到新数组,因此迭代器是无法感知到的; 。
5、CopyOnWriteArraySet 是基于 CopyOnWriteArrayList 动态数组的,并没有使用哈希思想.
最后此篇关于CopyOnWriteArrayList是如何保证线程安全的?的文章就讲到这里了,如果你想了解更多关于CopyOnWriteArrayList是如何保证线程安全的?的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
我将 Bootstrap 与 css 和 java 脚本结合使用。在不影响前端代码的情况下,我真的很难在css中绘制这个背景。在许多问题中,人们将宽度和高度设置为 0%。但是由于我的导航栏,我不能使用
我正在用 c 编写一个程序来读取文件的内容。代码如下: #include void main() { char line[90]; while(scanf("%79[^\
我想使用 javascript 获取矩阵数组的所有对 Angular 线。假设输入输出如下: input = [ [1,2,3], [4,5,6], [7,8,9], ] output =
可以用pdfmake绘制lines,circles和other shapes吗?如果是,是否有documentation或样本?我想用jsPDF替换pdfmake。 最佳答案 是的,有可能。 pdfm
我有一个小svg小部件,其目的是显示角度列表(参见图片)。 现在,角度是线元素,仅具有笔触,没有填充。但是现在我想使用一种“内部填充”颜色和一种“笔触/边框”颜色。我猜想line元素不能解决这个问题,
我正在为带有三角对象的 3D 场景编写一个非常基本的光线转换器,一切都工作正常,直到我决定尝试从场景原点 (0/0/0) 以外的点转换光线。 但是,当我将光线原点更改为 (0/1/0) 时,相交测试突
这个问题已经有答案了: Why do people write "#!/usr/bin/env python" on the first line of a Python script? (22 个回
如何使用大约 50 个星号 * 并使用 for 循环绘制一条水平线?当我尝试这样做时,结果是垂直(而不是水平)列出 50 个星号。 public void drawAstline() { f
这是一个让球以对角线方式下降的 UI,但球保持静止;线程似乎无法正常工作。你能告诉我如何让球移动吗? 请下载一个球并更改目录,以便程序可以找到您的球的分配位置。没有必要下载足球场,但如果您愿意,也可以
我在我的一个项目中使用 Jmeter 和 Ant,当我们生成报告时,它会在报告中显示 URL、#Samples、失败、成功率、平均时间、最短时间、最长时间。 我也想在报告中包含 90% 的时间线。 现
我有一个不寻常的问题,希望有人能帮助我。我想用 Canvas (android) 画一条 Swing 或波浪线,但我不知道该怎么做。它将成为蝌蚪的尾部,所以理想情况下我希望它的形状更像三角形,一端更大
这个问题已经有答案了: Checking Collision of Shapes with JavaFX (1 个回答) 已关闭 8 年前。 我正在使用 JavaFx 8 库。 我的任务很简单:我想检
如何按编号的百分比拆分文件。行数? 假设我想将我的文件分成 3 个部分(60%/20%/20% 部分),我可以手动执行此操作,-_-: $ wc -l brown.txt 57339 brown.tx
我正在努力实现这样的目标: 但这就是我设法做到的。 你能帮我实现预期的结果吗? 更新: 如果我删除 bootstrap.css 依赖项,问题就会消失。我怎样才能让它与 Bootstrap 一起工作?
我目前正在构建一个网站,但遇到了 transform: scale 的问题。我有一个按钮,当用户将鼠标悬停在它上面时,会发生两件事: 背景以对 Angular 线“扫过” 按钮标签颜色改变 按钮稍微变
我需要使用直线和仿射变换绘制大量数据点的图形(缩放图形以适合 View )。 目前,我正在使用 NSBezierPath,但我认为它效率很低(因为点在绘制之前被复制到贝塞尔路径)。通过将我的数据切割成
我正在使用基于 SVM 分类的 HOG 特征检测器。我可以成功提取车牌,但提取的车牌除了车牌号外还有一些不必要的像素/线。我的图像处理流程如下: 在灰度图像上应用 HOG 检测器 裁剪检测到的区域 调
我有以下图片: 我想填充它的轮廓(即我想在这张图片中填充线条)。 我尝试了形态学闭合,但使用大小为 3x3 的矩形内核和 10 迭代并没有填满整个边界。我还尝试了一个 21x21 内核和 1 迭代,但
我必须找到一种算法,可以找到两组数组之间的交集总数,而其中一个数组已排序。 举个例子,我们有这两个数组,我们向相应的数字画直线。 这两个数组为我们提供了总共 7 个交集。 有什么样的算法可以帮助我解决
简单地说 - 我想使用透视投影从近裁剪平面绘制一条射线/线到远裁剪平面。我有我认为是使用各种 OpenGL/图形编程指南中描述的方法通过单击鼠标生成的正确标准化的世界坐标。 我遇到的问题是我的光线似乎

我是一名优秀的程序员,十分优秀!