
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


在Python中,一个.py文件代表一个Module。在Module中可以是任何的符合Python文件格式的Python脚本。了解Module导入机制大有用处。 。
一个.py文件就是一个module。Module中包括attribute, function等。 这里说的attribute其实是module的global variable。 我们创建1个test1.py文件,代码如下 。
# 定义1个全局变量a
a = 1
# 声明一个全局变量moduleName
global moduleName
# 定义一个函数printModuleName
def printModuleName():
print(a + 2)
print(__name__)
print(moduleName)
print(dir())
这里我们定义了3个全局变量 a 、 moduleName 、 printModuleName ,除了我们自己定义的以外还有module内置的全局变量 。
上面我们说到了,每一个模块都有内置的全局变量,我们可以使用 dir() 函数,用于查看模块内容,例如上面的例子中,使用 dir() 查看结果如下:
['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'moduleName', 'printModuleName']
其中a, moduleName, printModuleName 是由用户自定义的。其他的全是内置的。下面介绍几个常用的内置全局变量 。
__name__ 指的是当前模块的名称,比如上面的 test1.py ,模块的名称默认就是test1,如果一个module是程序的入口,那么 __name__=__'main'__ ,这也是我们经常看到用到的 。
__builtins__ 它就是内置模块 builtins 的引用。可以通过如下代码测试:
import builtins
print(builtins == __builtins__)
打印结果为 True ,在Python代码里,不需要我们导入就能直接使用的函数、类等,都是在这个内置模块里的。例如: range 、 dir 。
__doc__ 它就是module的文档说明,具体是 文件头之后、代码(包含import)之前的第一个多行注释 ,测试如下 。
"""
模块导入机制测试
"""
import builtins
# 定义1个全局变量a
a = 1
# 声明一个全局变量moduleName
global moduleName
# 定义一个函数printModuleName
def printModuleName():
print(a + 2)
print(__name__)
print(moduleName)
print(__doc__)
最后打印结果为 。
模块导入机制测试
当然如果你想查看某个方法的说明,也可以这么使用 。
__file__ 当前module所在的文件的绝对路径 。
__package__ 当前module所在的包名。如果没有,为None。 。
为避免模块名冲突,Python引入了按目录组织模块的方法,称之为包(package)。包是含有Python模块的文件夹.
当一个文件夹下有 init.py 时,意为该文件夹是一个包(package),其下的多个模块(module)构成一个整体,而这些模块(module)都可通过同一个包(package)导入其他代码中.
其中 init.py 文件用于组织包(package),方便管理各个模块之间的引用、控制着包的导入行为.
该文件可以什么内容都不写,即为空文件,存在即可,相当于一个标记.
但若想使用 from pacakge_1 import * 这种形式的写法,需在 init.py 中加上: __all__ = ['file_a', 'file_b'] ,并且package_1下有 file_a.py 和 file_b.py ,在导入时 init.py 文件将被执行.
但不建议在 init.py 中写模块,以保证该文件简单。不过可在 init.py 导入我们需要的模块,以便避免一个个导入、方便使用.
其中, __all__ 是一个重要的变量,用来指定此包(package)被import *时,哪些模块(module)会被import进【当前作用域中】。不在 __all__ 列表中的模块不会被其他程序引用。可以重写 __all__ ,如 __all__ = ['当前所属包模块1名字', '模块1名字'] ,如果写了这个,则会按列表中的模块名进行导入 。
在模糊导入时,形如 from package import * ,*是由 __all__ 定义的.
当我们在导入一个包(package)时(会先加载 __init__.py 定义的引入模块,然后再运行其他代码),实际上是导入的它的 __init__.py 文件(导入时,该文件自动运行,助我们一下导入该包中的多个模块)。我们可以在 init.py中再导入其他的包(package)或模块或自定义类。 。
首先我们创建3个包,分别是 test 、 test2 、 test3 test包下创建 test1.py 用来执行测试 test2包下创建 file_a.py 、 file_b.py ,用来测试包的导入 test3包下创建 file_c.py ,辅助测试 具体结构如下: 核心代码在 test2/__init__.py 中如下 。
__all__ = ['file_a', 'file_b', 'file_c', 'test_d']
from test3 import file_c
def test_d():
return "test_d"
解释下,当我们在 test/test1.py 中写了 from test2 import * 这句代码,程序不是直接导入test2下的所有模块,而是导入 __init__.py 文件并自动运行,由于我们写了 __all__ = ['file_a', 'file_b', 'file_c', 'test_d'] ,file_a和file_b是当下包中的模块,file_c是我们从test3包中导入的,test_d是 __init__.py 下我们定义的函数.
所以 from test2 import * 就是把 __all__ 中指定的模块和函数导入进来了,接着我们查看 test1.py 下的代码 。
from test2 import *
print(file_a.a())
print(file_b.b())
print(file_c.c())
print(test_d())
如果打印有结果,则证明了导入成功,并且导入的是 __all__ 下的模块和函数 。
。
sys.modules是一个将模块名称映射到已加载的模块的字典。可用来强制重新加载modules。Python一启动,它将被加载在内存中.
当我们导入新modules,sys.modules将自动记录下该module;当第二次再导入该module时,Python将直接到字典中查找,加快运行速度.
它是1个字典,故拥有字典的一切方法,如 sys.modules.keys() 、 sys.modules.values() 、 sys.modules['os'] 。但请不要轻易替换字典、或从字典中删除某元素,将可能导致Python运行失败。 。
命名空间就像一个dict,key是变量名字,value是变量的值.
假设你要访问某段Python代码中的变量x时,Python会在所有的命名空间中查找该变量,顺序是:
我们可以看一个小例子 。
# test_namespace.py
def func(a=1):
b = 2
print(locals()) # 打印当前函数的局部命名空间
'''
locs = locals() # 只读,不可写,会报错
locs['c'] = 3
print(c)
'''
return a + b
func()
glos = globals()
glos['d'] = 4
print(d)
print(globals())
执行 func() 会打印函数func的局部命名空间,结果如下:
{'a': 1, 'b': 2}
执行 print(globals()) 会打印模块test_namespace的全局命名空间,结果如下:
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x7fde2605c730>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '/Users/jkc/PycharmProjects/pythonProject1/test_namespace.py', '__cached__': None, 'func': <function func at 0x7fde246b9310>, 'glos': {...}, 'd': 4}
内置函数 locals() 、 globals() 都会返回一个字典。区别:前者只读、后者可写.
命名空间在 from module_name import 、 import module_name 中的体现:from关键词是导入模块或包中的某个部分.
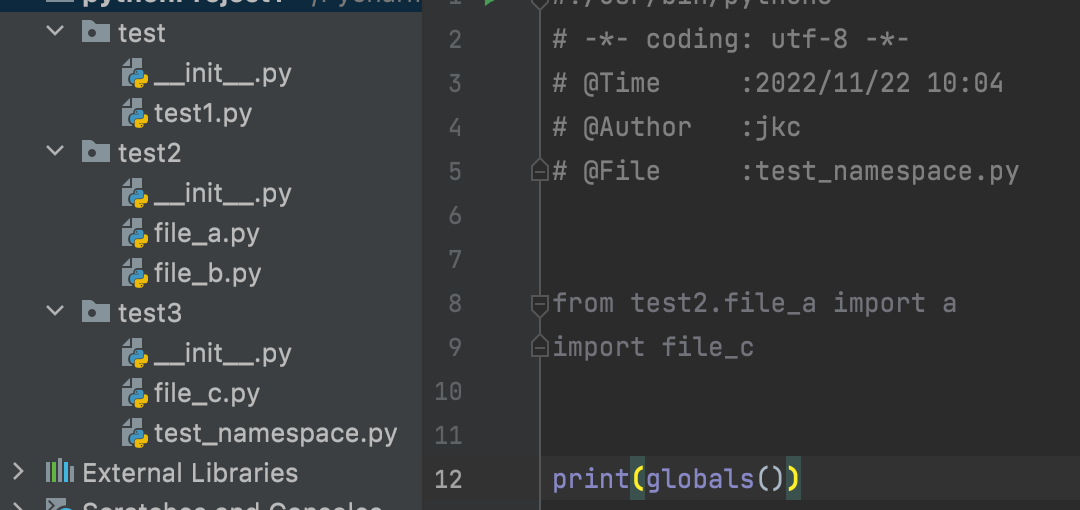
可以看到我们导入了函数a和模块file_c,接着我们打印了全局变量,结果如下:
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x7fab9585c730>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '/Users/jkc/PycharmProjects/pythonProject1/test3/test_namespace.py', '__cached__': None, 'a': <function a at 0x7fab95b04040>, 'file_c': <module 'file_c' from '/Users/jkc/PycharmProjects/pythonProject1/test3/file_c.py'>}
可以很清楚的看到全局变量中有函数a和模块file_c,接着我们尝试能否调用者2个 。
from test2.file_a import a
import file_c
print(globals())
file_c.c()
a()
最后也是可以成功调用 。
准备工作如下: 。
所有的模块import都从“根节点”开始。根节点的位置由 sys.path 中的路径决定,项目的根目录一般自动在 sys.path 中。如果希望程序能处处执行,需手动修改 sys.path .
例1:c.py中导入B包/B1子包/b1.py模块 。
import os
import sys
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
sys.path.append(BASE_DIR)
# 导入B包中的子包B1中的模块b1
from B.B1 import b1
例2:b1.py中导入b2.py模块 。
# 从B包中的子包B1中导入模块b2
from B.B1 import b2
。
只关心相对自己当前目录的模块位置就好。不能在包(package)的内部直接执行(会报错)。不管根节点在哪儿,包内的模块相对位置都是正确的.
b1.py代码如下:
# from . import b2 # 这种导入方式会报错
import b2 # 正确
b2.print_b2()
b2.py代码如下:
def print_b2():
print('b2')
最后运行b1.py,打印b2。 。
单独import某个包名称时,不会导入该包中所包含的所有子模块.
c.py导入同级目录B包的子包B1包的b2模块,执行b2模块的print_b2()方法: c.py代码 。
import B
B.B1.b2.print_b2()
运行c.py会以下错误 。
AttributeError: module 'B' has no attribute 'B1'
因为 import B 并不会自动将B下的子模块导入进去,需要手动添加,解决办法如下 在B/ init .py代码下添加如下代码 。
from . import B1
在B/B1/ init .py代码下添加如下代码 。
from . import b2
此时,执行c.py,成功打印b2。 。
我们要理解Python在执行import语句时,进行了啥操作? step1:创建一个新的、空的module对象(它可能包含多个module); step2:将该module对象 插入sys.modules中; step3:装载module的代码(如果需要,需先编译); step4:执行新的module中对应的代码.
在执行step3时,首先需找到module程序所在的位置,如导入的module名字为mod_1,则解释器得找到mod_1.py文件,搜索顺序是: 当前路径(或当前目录指定sys.path)->PYTHONPATH->Python安装设置相关的默认路径.
对于不在sys.path中,一定要避免用import导入自定义包(package)的子模块(module),而要用 from…import… 的绝对导入或相对导入,且包(package)的相对导入只能用from形式。 。
。
。

最后执行test.py,将打印3 。
moduleA.py 。
from moduleB import ClassB
class ClassA:
pass
moduleB.py 。
from moduleA import ClassA
class ClassB:
pass
当执行moduleA.py时会报错 。
ImportError: cannot import name 'ClassA' from partially initialized module 'moduleA'
报错分析:
from moduleB import ClassB 代码 sys.modules 中是否有
sys.modules ,直接得到
__dict__ 找不到ClassB,会报错
from moduleA import ClassA
<module moduleB> 的
__dict__ ,当然最终未能成功填充
from moduleB import ClassB
cannot import name 'ClassA' 解决办法:组织代码(重构代码):更改代码布局,可合并或分离竞争资源。 。
参考内如如下: Python 3.x | 史上最详解的导入(import) Python Module 。
最后此篇关于python进阶(28)import导入机制原理的文章就讲到这里了,如果你想了解更多关于python进阶(28)import导入机制原理的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
广播的原则 如果两个数组的后缘维度(从末尾开始算起的维度)的轴长度相符或其中一方的长度为1,则认为它们是广播兼容的。广播会在缺失维度和(或)轴长度为1的维度上进行。 在上面的对arr每一列减去列
之前在讲 MySQL 事务隔离性提到过,对于写操作给读操作的影响这种情形下发生的脏读、不可重复读、虚读问题。是通过MVCC 机制来进行解决的,那么MVCC到底是如何实现的,其内部原理是怎样的呢?我们要
我创建了一个 JavaScript 对象来保存用户在 ColorBox 中检查复选框时设置的值。 . 我对 jQuery 和“以正确的方式”编程 JavaScript 比较陌生,希望确保以下用于捕获用
我为了回答aquestion posted here on SO而玩示例,发现很难理解python的import *破坏作用域的机制。 首先是一点上下文:这个问题不涉及实际问题;我很清楚from fo
我想让我的类具有标识此类的参数 ID。例如我想要这样的东西: class Car { public static virtual string ID{get{return "car";}} }
更新:我使用的是 Java 1.6.34,没有机会升级到 Java 7。 我有一个场景,我每分钟只能调用一个方法 80 次。它实际上是由第 3 方编写的服务 API,如果您多次调用它,它会“关闭”(忽
希望这对于那些使用 Javascript 的人来说是一个简单的答案...... 我有一个日志文件,该文件正在被一个脚本监视,该脚本将注销中的新行提供给任何连接的浏览器。一些人评论说,他们希望看到的更多
我们正在开发针对 5.2 开发的 PHP 应用程序,但我们最近迁移到了 PHP 5.3。我们没有时间去解决所有迁移到 PHP 5.3 的问题。具体来说,我们有很多消息: Declaration of
简介 在实现定时调度功能的时候,我们往往会借助于第三方类库来完成,比如: quartz 、 spring schedule 等等。jdk从1.3版本开始,就提供了基于 timer 的定时调度功能。
Java中,一切都是对象,在分布式环境中经常需要将Object从这一端网络或设备传递到另一端。这就需要有一种可以在两端传输数据的协议。Java序列化机制就是为了解决这个问题而
我将编写自己的自定义控件,它与 UIButton 有很大不同。由于差异太大,我决定从头开始编写。所以我所有的子类都是 UIControl。 当我的控件在内部被触摸时,我想以目标操作的方式触发一条消息。
在我的代码中,在创建 TIdIMAP4 连接之前,我设置了一大堆 SASL 机制,希望按照规定的“最好到最差”顺序,如下所示: IMAP.SASLMechanisms.Add.SASL := mIdS
在 Kubernetes 中,假设我们有 3 个 pod,它们物理上托管在节点 X、Y 和 Z 上。当我使用“kubectl expose”将它们公开为服务时,它们都是集群中的节点(除了 X、Y 和
关闭。这个问题需要多问focused 。目前不接受答案。 想要改进此问题吗?更新问题,使其仅关注一个问题 editing this post . 已关闭 9 年前。 Improve this ques
我知道进程间通信 (ipc) 有几种方法,例如: 文件 信号 socket 消息队列 管道 命名管道 信号量 共享内存 消息传递 内存映射文件 但是我无法找到将这些机制相互比较并指出它们在不同环境中的
当我尝试连接到 teradata 时,出现了TD2 机制不支持单点登录 错误。 在 C# 中,我遇到了类似的问题,我通过添加 connectionStringBuilder.Authetication
我有一个带有 JSON API 的简单 Javascript 应用程序。目前它在客户端运行,但我想将它从客户端移动到服务器。我习惯于学习新平台,但在这种情况下,我的时间非常有限 - 所以我需要找到绝对
我想了解事件绑定(bind)/解除绑定(bind)在浏览器中是如何工作的。具体来说,如果我删除一个已经绑定(bind)了事件的元素,例如使用 jQuery:$("#anElement").remove
我不是在寻找具体答案,只是一个想法或提示。我有以下问题: Android 应用程序是 Web 服务的客户端。它有一个线程,通过 http 协议(protocol)发送事件(带有请求 ID 的 XML
我正在研究 FreeBSD TCP/IP 栈。似乎有 2 种 syn flood 机制,syncookies 和 syncache。我的问题是关于 syncookies,它是从头开始还是在 SYN 队

我是一名优秀的程序员,十分优秀!