
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 28
28
 4
4


这是一个剪刀石头布预测模型,会根据最近20局的历史数据训练模型,神经网络输入为最近2局的历史数据.
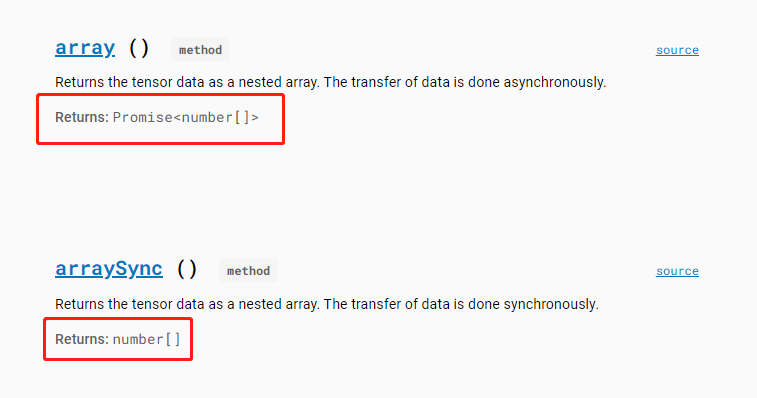
tensor = torch.tensor([1,2,3
])
np_array
= tensor.numpy()
//
方式一:arraySync()
let tensor = tf.tensor1d([1,2,3
]);
let array
=
tensor.arraySync();
console.log(array);
//
[1,2,3]
//
方式二:在async函数体内操作
async
function
fun() {
let tensor
= tf.tensor1d([1,2,3
]);
let array
=
await tensor.array();
console.log(array);
//
[1,2,3]
}
fun();
//
注意,下面的写法是不行的,因为async函数的返回值是Promise对象
array = async
function
(){
return
await tensor.array();
}();
console.log(array);
//
Promise object
//
方式三:用then取出async函数返回Promise对象中的值
let a
(async
function
() {
let array
=
await tensor.array();
return
array
})().then(data
=> {a =
data;})
console.log(a);
//
[1,2,3]
tensor = torch.tensor([1,2,3
])
print
(tensor[0])
print
(tensor[-1])
const tensor = tf.tensor1d([1,2,3
]);
const array =
tensor.arraySync();
console.log(array[
0
]);
console.log(array[array.length - 1]);
actions = {
'
up
'
:[1,0,0,0],
'
down
'
:[0,1,0,0],
'
left
'
:[0,0,1,0],
'
right
'
:[0,0,0,1
]}
actions_keys_list
= list(actions.keys())
const actions = {'up':[1,0,0,0], 'down':[0,1,0,0], 'left':[0,0,1,0], 'right':[0,0,0,1
]};
const actionsKeysArray
= Object.keys(actions);
memory = [1,2,3
]
memory.append(
4)
#
入栈
memory.pop(0)
#
出栈
let
memory = [1,2,3
];
memory.push(
4);
//
入栈
memory.splice(0,1);
//
出栈
memory = [1,2,3
]
memory.append(
4)
#
入栈
memory.pop()
#
出栈
let
memory = [1,2,3
];
memory.push(
4);
//
入栈
memory.pop();
//
出栈
actions = [
'
up
'
,
'
down
'
,
'
left
'
,
'
right
'
]
prob
= [0.1, 0.4, 0.4, 0.1
]
sample_action = np.random.choice(actions, p=prob))
const actions = ['up', 'down', 'left', 'right'
];
const prob
= [0.1, 0.4, 0.4, 0.1
];
sampleActionIndex
= tf.multinomial(prob, 1,
null
,
true
).arraySync();
//
tf.Tensor 不能作为索引,需要用 arraySync() 同步地传输为 array
sampleAction = actions[sampleActionIndex];
actions = [
'
up
'
,
'
down
'
,
'
left
'
,
'
right
'
]
prob
= [0.1, 0.3, 0.5, 0.1
]
prob_tensor
=
torch.tensor(prob)
action_max_prob
= actions[np.array(prob).argmax()]
#
np.array 可以作为索引
action_max_prob = actions[prob_tensor.argmax().numpy()]
#
torch.tensor 不能作为索引,需要转换为 np.array
const actions = ['up', 'down', 'left', 'right'
];
const prob
= [0.1, 0.3, 0.5, 0.1
];
const probTensor
=
tf.tensor1d(prob);
const actionsMaxProb
= actions[probTensor.argmax().arraySync()];
//
tf.Tensor 不能作为索引,需要用 arraySync()同步地传输为 array
range_list = list(range(1,10,1))
const rangeArray = tf.range(1, 10, 1).arraySync();
actions = [
'
up
'
,
'
down
'
,
'
left
'
,
'
right
'
]
print
(random.shuffle(actions))
const actions = ['up', 'down', 'left', 'right'];
tf.util.shuffle(actions);
console.log(actions);
(2)用 tf.data.shuffle 操作,不建议,该类及其方法一般仅与 神经网络模型更新 绑定使用.
import
numpy as np
import
torch
from
torch
import
nn
import
random
class
Memory(object):
#
向Memory输送的数据可以是list,也可以是np.array
def
__init__
(self, size=100, batch_size=32
):
self.memory_size
=
size
self.batch_size
=
batch_size
self.main
=
[]
def
save(self, data):
if
len(self.main) ==
self.memory_size:
self.main.pop(0)
self.main.append(data)
def
sample(self):
samples
=
random.sample(self.main, self.batch_size)
return
map(np.array, zip(*
samples))
class
Model(object):
#
Model中所有方法的输入和返回都是np.array
def
__init__
(self, lr=0.01, device=
None):
self.LR
=
lr
self.device
= torch.device(
"
cuda:0
"
if
torch.cuda.is_available()
else
"
cpu
"
)
#
调用GPU 若无则CPU
self.network =
nn.Sequential(nn.Flatten(),
nn.Linear(
10, 32
),
nn.ReLU(),
nn.Linear(
32, 5
),
nn.Softmax(dim
=1
)).to(self.device)
self.loss
= nn.CrossEntropyLoss(reduction=
'
mean
'
)
self.optimizer
= torch.optim.Adam(self.network.parameters(), lr=
self.LR)
def
predict_nograd(self, _input):
with torch.no_grad():
_input
= np.expand_dims(_input, axis=
0)
_input
=
torch.from_numpy(_input).float().to(self.device)
_output
=
self.network(_input).cpu().numpy()
_output
=
np.squeeze(_output)
return
_output
def
update(self, input_batch, target_batch):
#
设置为训练模式
self.network.train()
_input_batch
=
torch.from_numpy(input_batch).float().to(self.device)
_target_batch
=
torch.from_numpy(target_batch).float().to(self.device)
self.optimizer.zero_grad()
_evaluate_batch
=
self.network(_input_batch)
batch_loss
=
self.loss(_evaluate_batch, _target_batch)
batch_loss.backward()
self.optimizer.step()
batch_loss
=
batch_loss.item()
#
设置为预测模式
self.network.eval()
if
__name__
==
'
__main__
'
:
memory
=
Memory()
model
=
Model()
#
产生数据并输送到内存中
#
假设一个5分类问题
for
i
in
range(memory.memory_size):
example
= np.random.randint(0,2,size=10
)
label
= np.eye(5)[np.random.randint(0,5
)]
data
=
[example, label]
memory.save(data)
#
训练100次,每次从内存中随机抽取一个batch的数据
for
i
in
range(100
):
input_batch, target_batch
=
memory.sample()
model.update(input_batch, target_batch)
#
预测
prediction = model.predict_nograd(np.random.randint(0,2,size=10
))
print
(prediction)
const Memory =
{
memorySize :
100
,
main : [],
saveData :
function
(data) {
//
data = [input:array, label:array]
if
(
this
.main.length ==
this
.memorySize) {
this
.main.splice(0,1
);
}
this
.main.push(data);
},
getMemoryTensor:
function
() {
let inputArray
=
[],
labelArray
=
[];
for
(let i = 0; i <
this
.main.length; i++
) {
inputArray.push(
this
.main[i][0
])
labelArray.push(
this
.main[i][1
])
}
return
{
inputBatch: tf.tensor2d(inputArray),
labelBatch: tf.tensor2d(labelArray)
}
}
}
const Model
=
{
batchSize:
32
,
epoch:
200
,
network: tf.sequential({
layers: [
tf.layers.dense({inputShape: [
10], units: 16, activation: 'relu'
}),
tf.layers.dense({units:
5, activation: 'softmax'
}),
]
}),
compile:
function
() {
this
.network.compile({
optimizer: tf.train.sgd(
0.1
),
shuffle:
true
,
loss:
'categoricalCrossentropy'
,
metrics: [
'accuracy'
]
});
},
predict:
function
(input) {
//
input = array
//
Return tensor1d
return
this
.network.predict(tf.tensor2d([input])).squeeze();
},
update: async
function
(inputBatch, labelBatch) {
//
inputBatch = tf.tensor2d(memorySize × 10)
//
labelBatch = tf.tensor2d(memorySize × 5)
this
.compile();
await
this
.network.fit(inputBatch, labelBatch, {
epochs:
this
.epoch,
batchSize:
this
.batchSize
}).then(info
=>
{
console.log(
'Final accuracy'
, info.history.acc);
});
}
}
//
假设一个5分类问题
//
随机生成样例和标签,并填满内存
let example, label, rnd, data;
for
(let i = 0; i < Memory.memorySize; i++
) {
example
= tf.multinomial(tf.tensor1d([.5, .5]), 10
).arraySync();
rnd
= Math.floor(Math.random()*5
);
label
= tf.oneHot(tf.tensor1d([rnd], 'int32'), 5
).squeeze().arraySync();
data
=
[example, label];
Memory.saveData(data);
}
//
将内存中储存的数据导出为tensor,并训练模型
let {inputBatch, labelBatch} =
Memory.getMemoryTensor();
Model.update(inputBatch, labelBatch);
。
。
。
。
。
。
。
最后此篇关于从Numpy+Pytorch到TensorFlowJS:总结和常用平替整理的文章就讲到这里了,如果你想了解更多关于从Numpy+Pytorch到TensorFlowJS:总结和常用平替整理的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
28
4
 0
0
当我创建一个数据库时,我被要求选择默认排序规则,当我创建一个表时,我被要求选择排序规则。 utf8_general_ci 或...拉丁...?区分哪个是对的依据是什么? 最佳答案 A collatio
PHP不会检查单引号 '' 字符串中变量内插或(几乎)任何转义序列,所以采用单引号这种方式来定义字符串相当简单快捷。但是,双引号 "" 则不然,php会检查字符串中的变量或者转义
正则(regular),要使用正则表达式需要导入Python中的re(regular正则的缩写)模块。正则表达式是对字符串的处理,我们知道,字符串中有时候包含很多我们想要提取的信息,掌握这些处理字符
在开发过程中,有时需要对用户输入的类型做判断,最常见是在注册页面即用户名和密码,代码整理如下: 只能为中文 ?
]js正则表达式基本语法(精粹): http://www.zzvips.com/article/94068.html 许多语言,包括P
1、首先安装mongodb 1.下载地址:http://www.mongodb.org/downloads 2.解压缩到自己想要安装的目录,比如d:\mongodb 3.创建文件夹d:\mo
我更愿意在 R 中执行以下操作,但我愿意接受(易于学习的)其他解决方案。 我有多个(比如说 99 个)制表符分隔文件(我们称它们为 S1.txt 到 S99.txt)和表格,所有文件都具有完全相同的格
我制作了一个小程序,可以使用数学进行物理计算。 我有几个 if 语句,它们做同样的事情,但变量不同,但它们必须是它们,就好像 TextBox 是空的,int 将是 0。 例子如下: if (first
我正在构建需要扩展框的东西 - 这很好,我可以正常工作。然而,如果你看看这个FIDDLE你会看到它有点乱。我希望有一种方法可以扩展它们所在的盒子,这样它们就不会跳来跳去?那么盒子 3 的左侧会比右侧膨
我相当确定(在 MATLAB 中)应该有一个优雅的解决方案,但我现在想不起来。 我有一个包含 [classIndex, start, end] 的列表,我想将连续的类索引折叠成一个组,如下所示: 这个
维基百科将 XMPP 定义为: ...an open-standard communications protocol for message-oriented middleware based on
我的代码库已经进入了某种状态,希望能够摆脱它 repo 看起来有点像这样(A1、B1、C1 等显然是提交) A1 ---- A2 ---- A3 ---- A4 -
如何整理以下数据框 data.frame(a = c(1,2), values = c("[1.1, 1.2, 1.3]", "[2.1, 2.2]")) a values 1
所以我试图在 Haskell 中生成出租车号码列表。出租车号码是可以用两种不同方式写成两个不同立方体之和的数字 - 最小的是 1729 = 1^3 + 12^3 = 9^3 + 10^3 . 现在,我
我正在使用 roxygen2 来记录我正在开发的包的数据集。我知道你可以 use roxygen to document a dataset ,但是Shane's answer最终建议进行黑客攻击,虽
这个问题在这里已经有了答案: How can I combine two strings together in PHP? (19 个回答) 关闭 5 年前。 提前致歉,尽管我已经尝试并失败了几件不
我有一个大部分整洁的数据框,但有 2 列包含基准,而不是将基准合并为观察结果。我该如何整理,以便将“Facility_score”和“TTP”col_names 添加为每个独特的 FYQ 和 Metr
我有以下输入数据。每一行都是一个实验的结果: instance algo profit time x A 10 0.5 y A
我已经使用 PHP 和 MySQL 实现了搜索。目前我的表格整理是 "utf8_unicode_ci"。问题是,使用此排序规则 "ä"= "a" 是。如果我将排序规则更改为 "utf_bin" 一切正
所以我是 JS 和 Jquery 库的新手。我一直在玩弄一些东西,可以看到它非常不整洁,这就是我希望你们能帮助建议一种更好的方法来实现我想要实现的目标的地方。 目标: 要有多个复选框,其中一些如果被选

我是一名优秀的程序员,十分优秀!